AI不能“取代”医生给我们看病,这并不是因为AI不够强大

本文来自微信公众号:果壳(ID:Guokr42),作者:李子李子短信
约翰霍普金斯医学院的娜塔莉·特拉雅诺娃(Natalie Trayanova)教授,刚刚度过了魔鬼一般的一年。
在外人看来,她的科研道路仿佛是一帆风顺。她带领的心血管造影技术团队拿着来自美国国立卫生研究院(NIH)的研究基金,过去三年光论文就发表了50多篇;她的项目还频频在媒体上曝光,她本人甚至被邀请到TED Talk上做演讲。然而,当她着手将这套“领域内前所未有的解决方案”向临床应用推进的时候,却遭遇了前所未有的困难。

Your Personal Virtual Heart | Natalia Trayanova | TEDxJHU
她的方案在临床上的首要任务是治疗心颤。所谓心颤,指的是心脏不再有规律地按照周期跳动,而是无规律地快速“颤抖”;轻度的心颤有时本人都感觉不到,但严重的心颤可以让在几分钟内夺人性命。你可能在商场、路边或者影视作品里见过仪器装在红色盒子里,上面写着“AED”三个大字,还可能有红色的心形和闪电标记,这就是自动化的电除颤仪,依靠放电的办法结束心颤。这样的设备已经拯救了很多心脏病突然发作的人。
不过等到心颤发生再采取除颤,还是稍微有点晚。医学研究者开发出了一种心脏除颤手术,找到那些引发心律不齐的微小心肌纤维,把它们切除,从而根本上解决问题。麻烦的是,这些微小心肌纤维很难找,很大程度都靠医生经验,经常切不准地方还会误伤正常的部分。
特拉雅诺娃实验室就开发了一套结合了影像和人工智能的心脏造影方案,构建出全息3D的心脏模型,重建每一束心肌纤维、模拟心脏动态,精确地找出病灶,让手术“指哪打哪”。“我们还能顺便用这个影像,给心脏做3D打印,送给病人做留念。”来自保加利亚、已经在这个领域摸爬滚打了三十多年的特拉雅诺娃谈起自己的技术,仍然是一脸兴奋。而最近兴起的人工智能技术,更是有希望为这个技术添砖加瓦——例如,使用机器学习提高图像精度,优化计算流程,把时间和成本大幅降低。

特拉雅诺娃团队的“模拟心脏”
然而,谈到实际应用的前景,她的乐观减少了大半。病人的各类实际需求,总是不能与技术设计完美结合,她不得不一周三天跑医院、两天跑实验室,与医生和工程师反复沟通。更大的挑战来自美国食品药监局(FDA),任何一项技术想要投入应用,都免不了和 FDA 大战三百回合;要是不能将研究成果转换为审批标准,发了再多论文都相当于白做。“还不知道什么时候会通过审批。”她对我说,“明年或者后年吧?希望如此(Hopefully),希望如此。”
“希望如此”,成了她挂在嘴边的口头禅。在人工智能计算能力大幅提升的今天,乐观派们认为AI接管医院只是时间问题,然而从实验室到医院的这段路,依然困难重重。
AI能对疑难杂症做出独立诊断吗?
“你拿一万张猫的图片训练一个机器,机器能够非常迅速地判断眼前的图片是否是猫,”约翰·霍普金斯生物工程教授杰弗里·希维尔德森(Jeffrey Siewerdeson)给我打了个比方,“但你要让机器从一张元素繁多的图片里找猫,难度就指数级增大了。”
他的实验室曾经是约翰·霍普金斯医院的病房,墙上还残留着当年的病床支架和插座。如今的实验室已经远离了医院的喧闹,被各类计算机和影像仪器所占据。生物医学领域,基于机器和数据,而不用和湿漉漉的培养基或组织器官打交道的“干科学”(dry science)逐渐成为了领域热门。据医药研究机构 Signify Research 的数据预测,5年内光医疗影像和AI这一个细分领域的市场就将超过20亿美元,其中深度学习技术更是占据了半壁江山。

作者和希维尔德森在他的实验室
然而,人们需要对机器能做什么、不能做什么有清晰的认识。目前AI的主要成就,是给人类医生的判断打底子,而不是自行下达判断。比如希维尔德森所做的工作之一,是利用机器来学习高精度图片的特征,然后据此把低清图片“算”成高清图片——换言之,就是去马赛克。有些时候医生手头的设备不够先进,另一些时候医生需要实时观察图像,这些时候的低分辨率图片都可以在机器学习帮助下变得高清。
的确,图像识别是目前的AI最擅长的事情之一。大概从2013年开始,AI在这一个领域的能力就开始飞速发展;2015年,在谷歌ImageNet数据库训练下的机器,人脸识别能力已经超过了人类。这得益于机器能够在相对短的时间内吃进海量的影像数据,并通过深度神经网络各个层级进行分析、学习,成为阅“片”无数、经验丰富的“老医生”。希维尔德森和特拉雅诺娃所做的事情,都是利用AI的这方面长处,给予医生以诊断辅助,让医生“看”得更清楚、判断更准确。
可这并不是我们平时想象的“AI看病”。AI是否能对疑难杂症做出独立的诊断?
对于有的疾病,让AI看到影像就做出相应判断其实不那么难。比如眼科教授尼尔·布莱斯勒(Neil Bressler)正在做的项目,是使用AI技术诊断糖尿病人的眼底病变。由于这种疾病十分常见,数据积累丰富,再加上对于病变的判定相对简单,目前这个技术已经有了相对成熟的应用场景。然而,触及到更难的领域,例如癌症、肿瘤等等,图像模式十分复杂,很难用一种或者几种机械的模式概括,机器往往会卡在这种人脑依靠模拟(analogy)判断的地方。而有的病变本身也十分罕见,根本无法形成值得信赖的数据库。换句话说,现在还无法像训练一个真正的医生一样训练AI。
而更根本的矛盾还在后面:就算数据够多、计算能力够强,AI能够取代人类判断吗?

图:电视剧《西部世界》
人并不相信机器?
2011年12月,在美国马萨诸塞州的一家医院,急救车送来了一个晕倒的老年男性。他立即被安置在了急救病房,安插上体征了监控设备——如果他的生命体征出现危险的波动,设备就会发出警告,召唤护士。这样一来,护士就不必时时过来查看他的情况了。
然而,第二天,这个老人却死在了病床上。死之前监控设备的红灯闪了一夜,但却被路过的护士一遍接一遍地摁掉。疏于料理的护士当然难辞其咎,然而在深入的调查之后,另外一个问题浮出水面:包括这套系统在内,许多医院用于自动化监控的装置所发出的警报,很多是误报。
通常此类自动化系统,会把极其微小的波动当做风险来处理,毕竟,万一错过了一个风险,责任就大了,所以厂商都倾向于把机器调得“过度灵敏”,并产生一系列大惊小怪的误报;反过来,医护人员则在接连不断的误报冲击下产生了疲劳,忽略了真正的危险。这是一个现代版的“狼来了”。
“狼来了”问题本身看似是可以解决的:把自动化系统的敏感度调低就行(厂商无疑会不愿这样做,因为这样意味着他们自己要直接担负更多责任,不过这至少原则上是可解的)。但这是本质的问题吗?人类同样常常过度敏感,每一个医生都无数次经历过家属大呼小叫、护士匆忙跑来报告异常但最后平安无事的场景,但却无法想象有多少合格的医生会因为假警报太多而从此对它们彻底无动于衷、像对待自动系统那样一遍遍按掉。问题在哪里?
在于人并不信任机器。

图:电影《机械姬》
科幻小说常常把人对机器的猜疑描述成没来由的非理性行为甚至是灾祸的根源,但现实中这样的不信任其实是有理由的:人和机器的决策方式并不相同。譬如一个简单的自动化系统也许会监控病人的心率,低于一定数值就报警,但不同病人静息心率原本就不同,对一个普通人而言危险的低心率,对职业运动员而言也许只是稍微异常。传统的自动化系统只能在事先设好的规则内行事,超出规则就无能为力了。
今天最火的AI路线——深度学习看起来有望打破这个限制,但它带来了一整套新的问题。最近通过FDA审批的一个叫做“WAVE”的诊断平台,能够综合病人各项身体指标,通过深度学习的算法,给出“病人什么时候会进入病危状态”的预测。然而,《科学》(Science)2019年3月的一篇评论文章指出,不像是药品或者其它医药设备,机器学习为内核的算法并非一个逻辑确定的系统,里面涵盖了上千个互相牵涉的指标,也会根据训练数据的不同产生不同的效果,究竟是否存在确凿无疑、让人百分百信服的因果联系(就像你站在体重秤上的数字从不撒谎一样),很难说清。
而治病救人的医学,恰恰最需要稳定且可重复的证据支撑。
循证的过程需要控制变量,得出A和B之间确凿的因果联系,例如病人吃了A药之后,就是比吃安慰剂的效果要好,那么A药毫无疑问发挥了作用;而这种药在一小部分病人中产生的作用,和大部分病人相似,是可以重复的。深层到药物作用的机制和原理,则更需要有大量的动物实验打底,厘清一个化合物和病菌、器官、神经之间的具体联系。然而,目前主流的深度学习的技术却是吃进数据、吐出结果的 “黑箱”,很难照着这个方式循证。再加上机器学习的核心——数据本身就具有不确定性,更为人工智能的普适性和可重复性提出了问题。
在2019年2月华盛顿美国科学促进会(AAAS)的年会上,赖斯大学(Rice University)数据科学教授吉内薇拉·阿伦(Genevera Allen)用一系列事例直击了这个问题的核心。当下,有不少团队都在癌症相关的基因上做文章,输入癌症患者的基因组和病例数据,用机器学习的方式分析出几个不同的亚型(Sub-type),并在这个基础上开发靶向药物。这也是承袭乳腺癌的成功先例——根据基因表达的不同,乳腺癌可以分为10多种亚型,每一种的具体治疗方案和预后都不同。但是这种模式可以套到所有的癌症上吗?把大量数据“喂”给机器,机器真的能依靠数据模式给出靠谱的分类吗?

Genevera Allen | EurekAlert!
她综合了一些研究结果,发现在某个样本的数据上表现出色的算法,不一定适用于所有情况,也并不能重复,在这种分类的基础上得出的诊疗意见,自然也是无意义的。“两个团队用不一样的数据,很可能得到完全不重合的亚型分类,”阿伦在会议报告上说。“这些‘发现’真的具有科学价值吗?背后是否有可靠的医学证据支撑?”
她表示,如果继续这样发展,医疗科学很有可能陷入“危机”。虽然有点悲观,但也不无道理。毕竟,不靠谱的算法在亚马逊上给你推荐一本你不喜欢的书,你不买就好了;但是“推荐”一个疗法,有时候却是关乎生死的。当然,这并不是说人类医生不会犯错误。但在面对错误的时候,医学诊断的循证基础,能够给我们提供充足的条件复盘错误、并探求避免的方法。而面对人工智能的黑箱,我们甚至很难知道机器为什么会错,应该如何纠正。
一边是人工智能领域大幅提高的计算能力与不断优化的算法,另一边却是临床医学对于证据的谨慎。在不同的学科进行交叉和对话的同时,两边是否在使用同一套语言体系,成为了解决问题的关键。
AI要想治病救人,必须符合医学标准
这个年代最常听到的一句话,是“什么专业都得写代码”。的确,像希维尔德森和布莱斯勒的实验室里,懂医学和懂计算机同等重要,甚至还需要统计等数据科学。越来越多的研究者开始恶补相关知识,注册线上课程,甚至去跟本科生挤教室。许多老教授也拉下面子,向年轻博士生和博士后取经。
而随着大数据和人工智能的广泛应用,医生们也要开始懂得怎样刨数据,即使不会编程也必须明晓其中的原理。“(数据科学)就像另一门语言,或者好几门语言,”英国惠康基金会桑格研究所的研究员蔡娜在接受《马赛克科学》(Mosaic Science)采访时的一席话,说出了生物、医药研究人员的心声。“我不得不把之前大脑中的生化路径、流程图,转化成编程代码。”
从某种程度上讲,编程和数据成为医学领域最重要的能力之一。然而,计算机领域和医学领域的学科逻辑和评价标准,却存在一些分歧。特拉雅诺娃说,“现在太多人醉心于技术细节的提升,你去参加一个学术会议,到处都是跟你吹嘘自己的技术表现有多好,算法性能有多棒,然后在核心期刊上发了多少论文——这是他们领域的‘语言’。但最后能达到什么效果呢?” 说到这里,特拉雅诺娃摇了摇头。
“现有的大部分算法,包括诊断和预测等,都不是在传统的医学范式下研究出来的,不能直接体现医学所需要的指标,即使一些已经投入应用了,但可靠度、可应用程度等,都需要进一步验证。”宾夕法尼亚大学医学院血液和肿瘤专家拉维·帕里克(Ravi Parikh)在电话里对我说。“他在《科学》期刊上发表的评论文章谈及了这个问题:当下的许多医疗人工智能相关的研究,都以计算能力、反应速度、概率分布曲线等作为指标,比如一个算法能够把判断某种征兆的速度提高百分之几之类。但是,这到底在临床上意味着什么?这对病人的治疗效果有多大增益?速度提高了,但误诊率呢?病人接受了这个诊断,是否病程变短、返诊率下降?这些所谓 “落脚点”(endpoint)才是医学关心的指标,也是监管机构是否给某个技术放行的依据。
一言以蔽之,人工智能想要治病救人,必须要接受医学标准的审视。特拉雅诺娃深知其中的不易,前文提到的3D造影技术即将投入大规模临床实验,最终的评判标准并不是技术、性能,而是手术的成功率。“接受了手术的病人,究竟有多少不用返工重来?返诊率是多少?”能够让临床医生彻底掌握这个技术,把除颤手术目前接近40%的返诊率大幅降低,才是这个技术成功的标志。

作者和特拉雅诺娃合影
希维尔德森也表示,算法必须要“翻译”成为医学实验的成果方才能称之为医疗,定量的测试和评估是一切的基础。而在临床实验中,需要照顾的不仅仅是数据,还有病人。“要验证现有技术的可用性、可靠性和效果,目前通用的方式是回溯性分析研究,这样才能在不影响病人的治疗水平的前提下得到好的结果,并且也需要伦理委员会的批准。”
而且,我们必须诚实面对算法的局限。所有的药物都有副作用和适用人群,同样,做人工智能的人也必须从“用算法去解决普适性问题”的思维中跳出,重视应用情景、数据来源和数据质量等等,学会医学语言的谨慎。监管也必须面对一些关键挑战——例如,如何保证数据的多样性,如何打开人工智能和机器学习的“黑箱”,确定一个算法的具体原理与医学证据之间的联系。 “目前可以做的是建立完善的事后审计机制(auditing system),追踪算法和数据之间的关系,以及可能出现的数据偏差。”帕里克说,“但最后,一定还是落在临床的表现上,保证效用和可重复性。”
AI和医生的关系也许不是替代,而是互补
我在希维尔德森的实验室里看到了一个比乒乓球略小的3D打印模型,质感柔韧,中间的裂痕用细密的针脚缝了起来。“这是一个有着先天心脏缺陷婴儿的心脏的一部分。”希维尔德森对我解释道,“我们用当前的造影技术,结合人工智能技术为心脏建模,然后打印出来供进行手术的医生练手。”
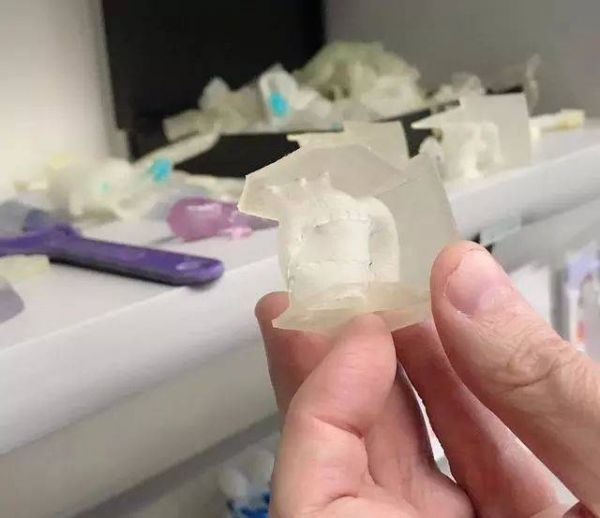
图:心脏模型
看着这个小小的模型,我仿佛能看到主刀医生和助手们围在屏幕前讨论手术方案,仔细观察和打量模型,思考着从哪里入手——这才是人机的完美配合,也是当下的医疗技术带来的最实际的进步。“在诊断和治疗中,一个医生的训练、经验和观察依然是最重要的。即使是最好的技术,也只能是增强医生的知识和能力,而不是替代。” 希维尔德森说。
帕里克也认为,我们不应该拿人工智能和医生相比。关键并不在于人工智能本身的能力,而是人工智能和现有的医学条件结合,能够发挥多大的功效。医生多年所见、所识、所领悟的并不能完全被翻译成数据、变成机器学习的资料;而人工智能亦有更精准的观察、更快的速度和永不疲倦的眼。谈论“医生+算法”的效果,远比谈论如何替代、或者谁比谁好要更有意义。
未来的医疗场景,一定不是病人被送进机器人医生的诊所,进行全身扫描之后得到“智能”的诊疗,而是可复制、可量产的机器,为医生提供足够多有价值的参考,节省更多人力物力,让诊疗变得更普及、更平民、更快捷。医疗人工智能领域的科技树不是冲着天空、往高处长,而是伸开枝叶,为更多的人提供安全和健康的荫蔽。
这个未来甚至并不遥远,脚踏实地一定走得到。
参考文献
[1].Allen, G. I. (2017). Statistical data integration: Challenges and opportunities. Statistical Modelling, 17(4-5), 332-337.
[2].Parikh, Ravi B., Ziad Obermeyer, and Amol S. Navathe. "Regulation of predictive analytics in medicine." Science 363.6429 (2019): 810-812.
[3].Razzak, Muhammad Imran, Saeeda Naz, and Ahmad Zaib. "Deep learning for medical image processing: Overview, challenges and the future." Classification in BioApps. Springer, Cham, 2018. 323-350.
[4].Giger, M. L. (2018). Machine learning in medical imaging. Journal of the American College of Radiology, 15(3), 512-520.
[5].Tenner, E. (2018). The Efficiency Paradox: What Big Data Can't Do. Knopf.
[6].https://www.bbc.com/news/science-environment-47267081
[7].https://www.wired.com/2017/03/biologists-teaching-code-survive/
[8].https://mosaicscience.com/story/how-big-data-changing-science-algorithms-research-genomics/
[9].https://www.signifyresearch.net/medical-imaging/ai-medical-imaging-top-2-billion-2023/
拇姬对本文有重要贡献;感谢美国科学促进会AAAS提供访问支持。
本文来自微信公众号:果壳(ID:Guokr42),作者:李子李子短信
相关推荐
AI不能“取代”医生给我们看病,这并不是因为AI不够强大
难摆脱医生资源争夺,互联网医疗仍缺“AI”
说取代医生为时尚早,但AI已为颠覆医疗业埋下伏笔
AI,会让放射科医生下岗吗?
中国AI技术领先,是因为数学好?
融资合伙人入围项目 | 院后服务迎来政策红利,「认识医生」想用AI让院后服务更智能高效
覆盖全生命周期,「奕诊智能」想做100%准确率的全能型AI医生 | 36氪医疗
让自己给自己看病?K Health获4500万美元C轮融资
从医疗影像运营到布局互联网医院和AI,「同心医联」找到了自己的“商业闭环”
早期诊断肺癌,这款AI已超越人类医生
网址: AI不能“取代”医生给我们看病,这并不是因为AI不够强大 http://www.xishuta.com/newsview2377.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95228
- 2人类唯一的出路:变成人工智能 21183
- 3报告:抖音海外版下载量突破1 21148
- 4移动办公如何高效?谷歌研究了 20339
- 5人类唯一的出路: 变成人工智 20338
- 62023年起,银行存取款迎来 10336
- 7五一来了,大数据杀熟又想来, 8596
- 8网传比亚迪一员工泄露华为机密 8505
- 9滴滴出行被投诉价格操纵,网约 8215
- 10顶风作案?金山WPS被指套娃 7230



