GPT-3走红背后,AI 正变成普通人玩不起的游戏
编者按:本文来自微信公众号“PingWest品玩”(ID:wepingwest),作者 Decode,36氪经授权发布。
在日常生活让 AI 帮忙完成一些任务,已经不是新鲜事。智能音箱里的 AI,可以告诉你“明天天气怎么样”;翻译软件里的 AI,能准确翻译一大段话甚至一篇文章;写作 AI 则会输出作文。
但它们都只能干一件事,翻译的 AI 写不了作文,问答的 AI 也不会翻译。它们更像一个个工具,而不是一个智能体。一个真正智能的 AI 应该是什么样的?它应该是通用的,既可以对付问答、写文章,也能搞定翻译。
最近在硅谷大火的 GPT-3,就是这么一个 AI。问答、写文、翻译都不在话下,还能写代码、算公式、做表格、画图标(详细的例子参见 PingWest 品玩之前的文章:API 开放之后,我们才真正领略 GPT-3 的强大……)。
· GPT-3 甚至会设计一个看上去像西瓜的按钮
本质上,GPT-3 其实是一个语言模型。所谓语言模型,就是让机器理解并预测人类语言的一项技术。如果说以前的语言模型是专才,那 GPT-3 就是一个通才,而且样样都干得还不错。
当我们仔细回顾和梳理它的诞生故事会发现,AI 领域的一个明显趋势正在浮出水面:要训练一个有颠覆性进步的模型,最终比拼的是数据量和算力规模,这意味着这个行业的门槛越来越高,最终可能导致 AI 技术的竞争变成少数“烧得起钱”的大公司之间的游戏。
预训练筑起数量门槛
GPT-3的故事要从2018年说起。
2018 年初,艾伦人工智能研究所和华盛顿大学的研究人员提出了 ELMo(Embedding from Language Models)模型。这之前的模型,无法理解上下文,不能根据语境去判断一个多义词的正确含义,ELMo 第一次解决了这个问题。
在训练 ELMo 模型过程中,研究人员采用了一种关键的方法——预训练。通常,训练一个模型需要大量经过人工标注的数据。而在标注数据很少的情况下,训练出来的模型精度很差。
预训练则摆脱了对标注数据的依赖,用大量没有标注的语料去训练(即无监督学习),得到一套模型参数,再把这套模型参数应用于具体任务上。这种模式训练出来的语言模型被证明了,在自然语言处理(以下简称 NLP)任务中能实现很好的效果。可以说,预训练这种方式的成功,开创了自然语言研究的新范式。

2018 年 6 月,在 ELMo 基础上,OpenAI 提出了 GPT。GPT 全称 Generative Pre-training,字面意思是“生成式预训练”。
GPT 同样基于预训练模式,但和 ELMo 不同的是,它加入了第二阶段训练:精调(Fine-tuning,又称“微调”),开创了“预训练+精调”的先河。所谓精调,即在第一阶段训练好的模型基础上,使用少量标注语料,针对具体的 NLP 任务来做调整(即有监督学习)。
除了开创“预训练+精调”模式,GPT 还在特征提取器上采用更加强大的 Transformer。所谓特征提取器,就是用来提取语义特征的。Google 在 2017 年推出的 Transformer,比 ELMo 所用的特征提取器 RNN,在综合效果和速度方面有优势。并且,数据量越大,越能凸显出 Transformer 的优点。
GPT 在预训练阶段设计了 12 层 Transformer(层数越多规模越大),并且使用“单向语言模型”作为训练任务。上文说到,ELMo 模型能理解上下文,上文和下文的信息都被充分利用。而 GPT 和之后的迭代版本,坚持用单向语言模型,只使用上文信息。
GPT 的设计思路奠定了此后迭代的基础,但由于它的规模和效果没有很出众,风头很快被 2018 年底亮相的 BERT 所盖过。

· 冷知识:ELMo 和 BERT 都是美国儿童节目《芝麻街》里面角色的名字
BERT 由 Google 打造,刷新 11 项 NLP 任务的最好水平,颠覆了整个 NLP 领域。BERT 的成功其实有 GPT 功劳,它们大框架上基本相同,都采用“预训练+精调”模式。差异的地方在于,GPT 是单向语言模型,而 BERT 采用双向语言模型。
BERT 虽然取得了巨大成功,但它有两个缺点。其一,虽然采用无监督学习和有监督学习结合(即“预训练+精调”)的模式,但还是少不了特定领域一定量的标注数据。其二,因为领域标注数据有限,会导致 BERT 模型过拟合(模型过于死板,只适用于训练数据),难以应用到其他领域,即通用能力不足。
2019 年 2 月亮相的 GPT-2,解决了 BERT 的短板。为了摆脱对标注数据的依赖,OpenAI 在设计 GPT-2 模型时,基本上采用无监督学习(即预训练),减小了精调阶段有监督学习的比重,尝试在一些任务上不进行精调。
其次,为了增强通用性,OpenAI 选取了范围更广、质量更高的数据,用 800 万个互联网网页的语料(大小 40 GB)去训练,几乎覆盖所有领域。此外,OpenAI 还加大了 GPT-2 模型的规模,把参数增加到 15 亿,是 GPT(1.17 亿个参数)的 10 倍,是 BERT-Large(BERT 一个规模较大的版本,有 3 亿个参数)的 5 倍。
GPT-2 亮相后,很快吸引了整个 NLP 领域的目光。它在做具体 NLP 任务时(如问答、翻译和摘要),用的都是预训练阶段的模型,都能比较好的完成这些任务。特别是给定短文续写文章方面,表现十分出色。
沿着大规模预训练的思路,OpenAI 继续“大水漫灌”,用更多无标注数据、更多参数和更多算力去训练模型,终于在 2020 年 5 月推出了 GPT-3。7 月,又开发了 API(应用程序接口),让更多开发者可以调用 GPT-3 的预训练模型,彻底引爆了整个 NLP 圈。
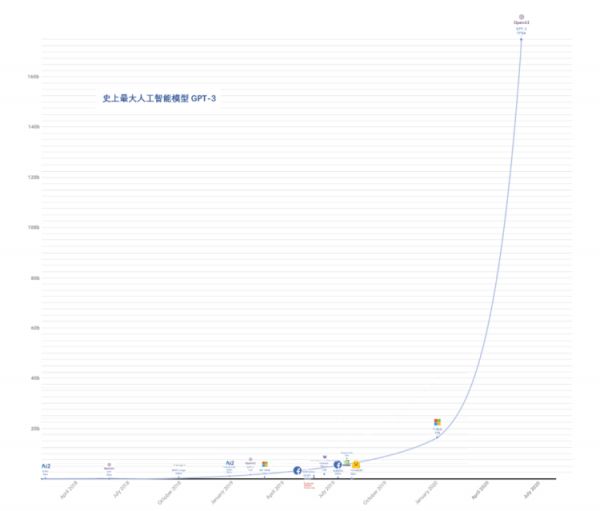
· GPT-3 在右边最上面,图片来自微信号“亲爱的数据”
堆人、堆算力规模
从 GPT-1 的“平平无奇”到 GPT-3 的突破,充分体现了什么叫“大力出奇迹”。
首先看人力。初代 GPT 的论文只有四位作者,GPT-2 论文有六位作者。到了 GPT-3,论文作者猛增为 31 位。
· GPT-3 的论文足有 31 位作者
并且,这 31 位作者分工明确,有人负责训练模型,有人负责收集和过滤数据,有人负责实施具体的自然语言任务,有人负责开发更快的 GPU 内核,跟公司不同部门间合作没啥区别。

· 31 位作者的分工就写了整整一页
再看看算力。从初代 GPT 到 GPT-3,算法模型基本没有变化,都是基于 Transformer 做预训练,但训练数据量和模型规模十倍、千倍地增长。相应地,所需要的算力也越来越夸张。初代 GPT 在 8 个 GPU 上训练一个月就行,而 GPT-2 需要在 256 个 Google Cloud TPU v3 上训练(256 美元每小时),训练时长未知。

到 GPT-3,算力费用已经是千万级别。据 GPT-3 的论文,所有模型都是在高带宽集群中的英伟达 V100 GPU 上训练的,训练费用预估为 1200 万美元。
甚至,由于成本过于地高,研究者在发现了一个 Bug 的情况下,没有选择再去训练一次,而是把涉及的部分排除在论文之外。

· 研究人员发现了一个 Bug,但由于成本问题没有去解决
显然,没有强大的算力(其实相当于财力)支持,GPT-3 根本不可能被训练出来。那么,OpenAI 的算力支持源自何处?这要说回到一笔投资。2019 年 7 月,微软向 OpenAI 注资 10 亿美元。双方协定,微软给 OpenAI 提供算力支持,而 OpenAI 则将部分 AI 知识产权授权给微软进行商业化。

2020 年 5 月,微软推出了一台专门为 OpenAI 设计的超级计算机。它托管在 Azure 上,包含超过 28.5 万个处理器内核和 1 万块 GPU,每个显卡服务器的连接速度为 400 Gbps/s。它的性能在超级计算机排名中,可以排到前五。
最后,再来说说 OpenAI 这家机构。埃隆・马斯克和原 Y Combinator 总裁山姆·奥特曼主导成立于 2015 年的 OpenAI,原本是一个纯粹的非营利 AI 研究组织,但经过一次转型和架构调整,加上引入微软投资,现在已经成为混合了营利与非营利性质的企业。
一直以来,OpenAI 的目标都是创建“通用人工智能”(Artificial General Intelligence,简称AGI),就好像文章开头所说的,AGI 是一个可以胜任所有智力任务的 AI。
打造 AGI 的路径有两种,一种是开发出更加强大的算法,另一种是在现有算法基础上进行规模化。OpenAI 就是第二种路径的信仰者。2019 年,OpenAI 核算了自 2012 年来所有模型所用的计算量,包括 AlexNet 和 AlphaGo,发现最大规模 AI 模型所需算力,已经增长了 30 万倍,每 3.4 个月翻一番。而摩尔定律指出,芯片性能翻倍周期是 18–24 个月。这就意味着,最大规模 AI 模型对算力需求的增长,远超芯片性能的提升。
毫无疑问,算力已经成为 NLP 研究甚至 AI 研究的壁垒。知乎用户“李渔”说得好:GPT-3 仅仅只是一个开始,随着这类工作的常态化开展,类似 OpenAI 的机构很可能形成系统性的 AI 技术垄断。
相关推荐
GPT-3走红背后,AI 正变成普通人玩不起的游戏
GPT-3有多强?国外小哥拿它写“鸡汤文”狂涨粉
与GPT-3对话:它的回答令人细思极恐
GPT-3有多强?伯克利小哥拿它写“鸡汤”狂涨粉,还成了Hacker News最火文章?
强大如GPT-3,1750亿参数也搞不定中文?
“生成式 AI”时代:“超现实”会让人失去对现实的兴趣吗?
硅谷早知道 S4E33 | 人工智能又一里程碑式突破,GPT-3红了
微软拿到GPT-3独家授权,马斯克:“有悖开放初心”
普通人眼中的AI:大众对AI的认知调研报告(上篇)
王川:关于 GPT-3 的随想 (一)
网址: GPT-3走红背后,AI 正变成普通人玩不起的游戏 http://www.xishuta.com/newsview28886.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95228
- 2人类唯一的出路:变成人工智能 21183
- 3报告:抖音海外版下载量突破1 21148
- 4移动办公如何高效?谷歌研究了 20339
- 5人类唯一的出路: 变成人工智 20338
- 62023年起,银行存取款迎来 10336
- 7五一来了,大数据杀熟又想来, 8596
- 8网传比亚迪一员工泄露华为机密 8505
- 9滴滴出行被投诉价格操纵,网约 8215
- 10顶风作案?金山WPS被指套娃 7230



