强大如GPT-3,1750亿参数也搞不定中文?
本文来自微信公众号:AI前线(ID:ai-front),作者:陈思,题图来自:视觉中国
2019 年,GPT-2 凭借将近 30 亿条参数的规模拿下来“最强 NLP 模型”的称号;2020 年,1750 亿条参数的 GPT-3 震撼发布,并同时在工业界与学术界掀起了各种争论。随着时间的推移,争论的焦点也发生了变化,人们逐渐发现:GPT-3 似乎不仅仅是“越来越大”这么简单。
GPT-3 不仅庞大,还很强大?
解答一个重要的问题:GPT-3 是什么?
按照官方介绍:GPT-3 是由人工智能研发公司 OpenAI 开发的一种用于文本生成的自然语言处理(NLP)模型。它的前作 GPT-2 曾被赋予“最强 NLP 模型”的称号,一个重要的原因就是 GPT-2 拥有着非常庞大的规模(见下注)。
注:OpenAI 已经于 2019 年发布了三种 GPT-2 模型:“小型的”1.24 亿参数模型(有 500MB 在磁盘上 ),“中型的”3.55 亿参数模型(有 1.5GB 在磁盘上 ),以及 7.74 亿参数模型(有 3GB 在磁盘上)。作为 GPT-2 分段发布中的最后一轮,2019 年 11 月,OpenAI 公开了完整 GPT-2 包含 15 亿条参数,其中包含用于检测 GPT-2 模型输出的全部代码及模型权重。
2020 年 5 月,GPT-3 的论文一经发表就引发了业内的轰动,因为这一版本的模型有着巨大的 1750 亿参数量。
熟悉人工智能的人应该知道,AI 三要素是:算力、算法、数据。在前两者基本固定的情况下,数据量的大小对 AI 模型的效果会起到非常关键的作用,GPT-3 如此庞大的规模能够带来的影响不言而喻。
为了对 GPT-3 有更进一步的了解,InfoQ 采访到了来自小米公司负责开放域对话和生成类任务的技术专家魏晨 ,作为对 GPT 有过实际应用的技术人,她也研究了 GPT-3 与 GPT-2 相比的一些主要变化:
两者模型和结构是相同的,包括修改的初始化(modified initialization),预规范化(pre-normalization)和可逆记号化(reversible tokenization)。不同之处在于,在 transformer 各层中使用了交替稠密(alternating dense)且局部带状稀疏注意力(locally banded sparse attention)模式,类似于 Spare Transformer。GPT-3 模型不仅超级大,且在超大数据集上进行了训练(45TB,过滤筛选后大约 570GB)。这些使得 GPT-3 可以很好地做其他模型无法做的事情:执行特定任务而无需任何特殊调整,可以做翻译、写程序、作诗、写文章,仅需要提供极少几个训练样本 。
有了 pre-train 的 GPT-3 模型,应用到下游 NLP 任务时,无需执行微调步骤,基本无需训练样本就可以执行自定义自然语言任务。而其他的语言模型(BERT)需要精巧的微调步骤,需要准备几千个或者几万个训练数据。
GPT-3 不包含主要的新技术,它基本上是去年 GPT-2 的放大版本 ,而 GPT-2 本身就是使用深度学习的其他语言模型的大号版本。所有这些都是在文本上训练的巨大人工神经网络,用于预测序列中的下一个单词可能是什么。GPT-3 只是更大:更大 100 倍(96 层和 1,750 亿个参数),并且接受了更多数据的训练(CommonCrawl,一个包含大量 Internet 的数据库,以及一个庞大的图书库和所有 Wikipedia)。

论文中对比了 42 个评估准确率的 benchmarks,模型大小和模型表现的对比:
零样本学习(zero shot)模型效果和模型表现提升稳定;小样本学习(few shot)模型表现提升较快些。
横轴体现了模型效果与模型大小的幂律分布 :GPT2 大约是 1.5B, GPT-3 是 175B。前者在大多数任务上准确率只有 20% 左右,而后者接近 60%。

支持的任务广泛,且旨在测试快速适应不太可能直接包含在训练集中的任务的几个新任务。对于每项任务,论文在“ 零样本学习” (zero-shot learning),“ 单样本学习”(one-shot learning)和“ 小样本学习”(few-shot learning)的条件下进行评估, 效果有惊喜 。
魏晨本人对 GPT-3 的评价是, GPT-3 模型从看上去更加接近“通用人工智能”,可以动态学习,处理多种不同的任务,只需少量的标注数据。详细来说:
1. GPT-3 支持多模态交互(输入 / 输出可以是人类语言 / 图像 / 计算机语言 / 表格等);
2. 能够处理多种不同的任务(改语法错误 / 写文章 / 聊天 / 算数 / 答题 / 翻译等),支持的任务更加广泛;
3. 可以“动态”的“学习”(零样本 / 单样本 / 小样本学习,给 0/1/ 几个样例就可以处理“新”任务);
4. 显示语言模型的表现随模型大小,数据集大小和计算量而变化;
5. 经过足够数据训练的语言模型可以解决从未遇到过的 NLP 任务,GPT-3 将作为许多下游任务的通用解决方案,而无需进行微调;
6. 尽管通过增 加 模型容量可以明显提高性能,但是不清楚引擎里面发生了什么,即该模型是否已经学会推理,还是以更智能的方式记住训练示例。
另一位接受 InfoQ 采访的专家——来自百分点的首席算法科学家苏海波告诉记者, GPT-3 与 GPT-2 相比, 模型结构没什么变化 ,都是基于 Transformer 的 Decoder 模型以及使用单向语言模型训练方式, 但是训练数据量和模型规模差异很大。
并且 GPT-3 主要聚焦于更通用的 NLP 模型,它的文本生成能力会比 GPT-2 明显要强,可以应用的场景也挺多,包括写文章、翻译、问答、编程、数学推理、做财务报表等,而且这些场景都是一个由通用的模型来实现的。
此外,他这样评价 GPT-3:
从技术的角度来说,GPT-3 的技术思路是大力出奇迹, 本身算法上没有什么创新 ,但是在工程实现上,要实现这么大规模数据量的分布式训练,以及获得这么大尺寸的模型,还是很有技术含量的。
从商业价值的角度而言,GPT-3 目前更多处于宣传阶段,还没有通过实际商业化场景的考验,因此谈不上颠覆性的进步,需要进一步证明。
总而言之一句话:GPT-3 规模确实庞大,但是并不包含太多新技术,目前处在宣传期的 GPT-3 让人感觉其功能强大,但实际情况仍需要不断地实践以证真伪。
“完美”的 NLP 解决方案并不存在
魏晨在采访中表示,GPT-3 虽然是 OpenAI 有史以来最大的语言模型,有 96 层 Transformer Decoder 和 1750 亿个参数(这里提供一组参数对比:ELMO 9400 万;BERT 3.4 亿;GPT-2 初版 1.1 亿;GPT-2 15.42 亿;GPT-3 1750 亿),但是规模大也就意味着训练时间和费用也会增长,GPT-3 就 需要 355 年的 GPU 时间和至少 460 万美元的训练费用 。
此外,GPT-3 短期内比较难支持在线使用 ,无论是从 效率 还是 可控性 的角度;如果只支持离线使用(with API access),那么需要考虑下方式方法。GPT-3 的模型结构和算法以及如何提升预训练样本的效率,都仍有提升的空间;对于语境学习 / 常识知识以及指代关系丢失等问题,仍有待提高。
在实际效果层面,尽管 GPT-3 只需很少的信息即可执行新任务的能力令人印象深刻,但在大多数任务上,它离人类水平还很远 。甚至在许多任务上,它的表现都无法超过最佳的微调模型。
苏海波也同样认为, GPT-3 的生成表现只是海量文本大数据训练的结果,无法超越文本数据本身 ,本质上还是一个语言模型,没有通过图灵测试。它和人类的思维能力相比,还是有明显差距的,不具备人类推理的能力,例如处理一些基本的常识和简单的数学推理方面都存在着明显的失误。
不过,魏晨介绍说,GPT-3 的能力在某些任务上的扩展性比其他任务好。例如,在自然语言推理任务中,确定一条语句与一段文字的关系矛盾还是蕴含非常有挑战。这可能是因为很难使模型在较短的上下文窗口中理解该任务(模型需要完成某个任务,并且理解被询问的信息是什么),但是 GPT-3 得益于其自身庞大的数据优势,可以很好地处理这一问题。
与所有深度学习系统一样, GPT-3 也在寻找数据模式 。为简化起见,该程序已针对庞大的文本集进行了训练,并根据统计规律进行了挖掘。这些规则对于人类来说是未知的,但是它们被存储为 GPT-3 神经网络中数十亿个加权连接的不同节点之间。
重要的是,此过程无需人工干预:该程序无需任何指导即可查找和查找模式,然后将其用于完成文本提示。比如,在 GPT-3 中输入“fire”一词,程序会根据其网络中的权重知道,“truck”和“alarm”一词比“lucid”或“elvish”更有可能在“fire”之后出现。
最后,也是目前几乎绝大部分 NLP 模型都存在的问题,即在错误的提示下,可能会得到种族 / 性别歧视的输出结果。
两个月前,GPT-3 发布后不久,一位号称 GPT 系列的铁粉就在个人博客中列举了 GPT-3 令人失望的地方,他的核心观点跟魏晨类似,主要集中在“参数越来越大但一些实际问题仍然得不到解决”等方面。
中文难题,即使强如 GPT-3 也无解?
有人提出问题:GPT-3 再强大,也是英文环境下的强大,面对复杂的中文,GPT-3 还能保持一贯的水准吗?
仅需几个示例,即可解决语言和语法难题, 这表明 GPT-3 已在无需任何特殊训练的情况下成功掌握了某些深层的语言规则。正如计算机科学教授 Yoav Goldberg 在 Twitter 上分享的那样,这种功能对于 AI 来说是“新奇的和令人兴奋的”,但这并不意味着 GPT-3 具有“精通”的语言。
魏晨说,在 NLP 任务中,中文语言是很有挑战的。与英文不同,中文需要进行分词,而英文就是天然单词;其次中文的歧义性很强,比如说“喜欢上 / 一个人”,”喜欢 / 上一个 / 人“,”喜欢上 / 一个 / 人“,这些都表达了不同的意思。
GPT 系列语言模型是单项语言模型,用户提供上文,模型可以递归自动生成下文,语言模型天生可以用于自然语言生成的任务。但是对于一系列的自然语言理解的任务表现则有待确认,魏晨表示,目前一种猜想是将示例和说明作为附加的输入,并使用特定标记将示例和结果分隔开,然后输入模型进行生成。
另外,从 PLM 开始,不少研究就发现很多模型很擅长生成看起来“很符合语言结构特性”但实际并不存在的“词”或者“词组”,GPT-3 应该也难逃这个问题。所以哪怕是输入了额外的说明信息,也依然可能生成出乍一眼看很像那么回事,但实际不知所云的东西(比如营销号生成器等)。魏晨觉得可能依然需要一些 multi-task 的任务来辅助约束 PLM 模型进行 NLU 理解人物,学习到它应该具备的推理等能力。
而从成本方面来说,苏海波告诉记者,GPT-3 的预训练使用数千亿词(45TB 数据)进行训练,拥有 1750 亿个参数,所需要的算力资源和付出的代价实在太大,为此,Microsoft 和 OpenAI 合力开发了一款超级计算机,专门用于 GPT-3 模型训练,这款计算机拥有超过 285000 个 CPU 内核、10000 个 GPU 和 400Gbps 的网络连接,光是训练费用就高达 460 万美元。
因此,苏海波认为:“GPT-3 能产生的直接商业价值是否能弥补训练模型消耗的巨大投入,存在很大的未知和不确定性 ,还没有看到哪一家国内公司和研究机构明确要去实现中文版的 GPT-3。”
他进一步补充道,GPT-3 的目标是做一个通用的语言模型,用更少的领域数据、且不经过精调步骤去解决问题。如果存在中文的 GPT-3 模型,对于标注数据量不足的中文 NLP 场景,GPT-3 有一定的效果改善作用,但是投入产出性价比有待商榷。
同时,苏海波还说:“GPT-3 能够带来一定的作用,对标注数据量的依赖会变得更少,但是从投入产出比上而言,我们有比 GPT-3 代价低得多的办法。”
用 AI 来编写代码,真的能行吗?
分析过 GPT-3 的种种优势与短板后,现在该来聊一聊很多开发者都比较关心的问题了——GPT-3 会不会让一部分程序员“丢了饭碗”?
这个话题的起因是这样的,在陆续取得使用资格后,一些研发组织、公司或者个人开发者搞起来 GPT-3 的各种 demo:
公式生成器: 只需要输入文本就可以生成对应的数学公式。
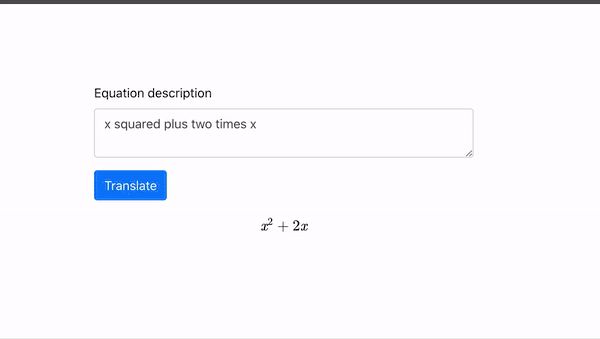
代码生成器: 输入文本,如:“生成一个像西瓜的按钮”,即可生成对应的代码及效果。

虽然有些 demo 目前还有些粗糙,但也足以看出 GPT-3 的能力是不容小觑的。作为出品方的 OpenAI 也在官网上放出了一些体验项目,比如常见的聊天机器人、智能客服等等,还有 AI 自动生成的文字闯关游戏,感兴趣的读者也可以在这里体验:https://beta.openai.com/
在这些 demo 当中,各种代码生成工具引发了讨论,除了上面说的简单生成一个按钮之外,GPT-3 还可以完整生成一整个页面及代码:

通过文字描述生成一个谷歌搜索界面
于是就有了一些声音认为,随着 GPT-3 这样强大的模型出现,一部分程序员的工作是可以交给 AI 来处理的;当然反对的声音也很大,认为前一种想法不切实际,AI 目前仍然没有替代人类的能力。
有意思的是,随着全球对 GPT-3 话题讨论热度的攀升,就连 OpenAI 联合创始人 Sam Altman 都站出来表示:“(网络上的)这类说法过分夸大了 GPT-3 的能力 。”
我们也就这一话题请两位专家谈了谈自己的看法,魏晨说:“首先,技术的发展进步令人兴奋,但是看问题仍然要回归到理性。这些都是精心挑选的示例, 更多只显示有效的结果,而忽略无效的结果 。这意味着 GPT-3 的能力总体上比其细节更令人印象深刻。但是 GPT-3 也会出现简单的错误。也许我们可以检验比较一下 GPT、GPT-2 和 GPT-3 的低级错误率,看它们是否真正在避免低级错误(从一个角度讲,掌握基础知识)上有更多的进步。”
她补充道,尽管 GPT-3 确实可以编写代码,但很难判断其总体用途 。比如,如何判断是整洁可执行的还是一般的代码?这样的代码上线后会不会给人类开发人员带来更多问题?没有详细的测试,这一切都很难说,即使是人类程序员也会犯错误。
其次,很难权衡这些错误的重要性和普遍性。如何判断几乎可以问任何问题的程序的准确性?如何创建 GPT-3 的“知识”的系统地图,然后如何对其进行标记?尽管 GPT-3 经常会出错,但有意思的是,通常可以通过微调所输入的文本(即提示)来解决这些问题。
在一个示例错误中,用户询问 GPT-3:“哪个更重,一个烤面包机或一支铅笔?”它回答说:“铅笔比烤面包机重。”学者 Branwen 指出,如果在问这个问题之前给机器喂食某些提示,告诉它水壶比猫重,海洋比尘土重,它会给出正确的响应。这可能是一个棘手的过程,但是它表明 GPT-3 有能力学习到正确的答案。
对于这类生成代码的 demo,苏海波则表示:“ GPT-3 对某些编程开发工作能够有一定的辅助作用,但完全替代是很困难的 。”他认为,目前这些通过输入文字直接生成代码的演示,对于一些逻辑很简单的代码。
例如前端开发中的标准化组件生成代码,容易通过文字来描述的,可以采用 GPT-3 来实现,但是逻辑稍微复杂一些的后端开发代码,不好用文字来描述的,就难以通过 GPT-3 来实现了,例如现有的 NLP 产品或者项目的代码开发工作,是很难通过 GPT-3 来替代的。
结语
通过对 GPT-3 的介绍、优缺点分析以及生成代码实践的解析,相信读者对于 GPT-3 的情况已经有了一些了解,最后总结一下两位老师回答的重点:
GPT-3 参数庞大(约 1750 亿参数),能力较之前确实有所提升,但是宣传效果有夸张成分;
受参数大小影响,GPT-3 并不是一款性价比很高的模型,训练成本较高;
中文 GPT-3 的实践尚未出现;
GPT-3 确实可以通过文字输入生成代码,但是仅限于比较简单的情况;
离 AI 真正替代程序员工作, 还有较长的路要走。
是的,GPT-3 很庞大,但是离“翻天覆地”似乎仍有一段距离,但不可否认的是,它仍然是自然语言处理甚至人工智能发展史上重要的里程碑。正如那句行业“金句”所说:“新技术总是在质疑中成长。”
真正有价值的技术最终会被认可,相信随着全行业愈发理性地看待 AI 技术的进步,如深度学习一样颠覆性的技术,在不久的将来就会出现。
本文来自微信公众号:AI前线(ID:ai-front),作者:陈思
相关推荐
强大如GPT-3,1750亿参数也搞不定中文?
微软拿到GPT-3独家授权,马斯克:“有悖开放初心”
GPT-3走红背后,AI 正变成普通人玩不起的游戏
细思极恐:GPT-3在《卫报》发专栏文章:不要怕我,我不想消灭人类,你们应该对计算机充满信心
GPT-3有多强?国外小哥拿它写“鸡汤文”狂涨粉
GPT-3有多强?伯克利小哥拿它写“鸡汤”狂涨粉,还成了Hacker News最火文章?
王川:关于 GPT-3 的随想 (一)
硅谷早知道 S4E33 | 人工智能又一里程碑式突破,GPT-3红了
与GPT-3对话:它的回答令人细思极恐
它抢不走程序员的饭碗,但是会让一部分人瑟瑟发抖
网址: 强大如GPT-3,1750亿参数也搞不定中文? http://www.xishuta.com/newsview28918.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95228
- 2人类唯一的出路:变成人工智能 21183
- 3报告:抖音海外版下载量突破1 21148
- 4移动办公如何高效?谷歌研究了 20339
- 5人类唯一的出路: 变成人工智 20338
- 62023年起,银行存取款迎来 10336
- 7五一来了,大数据杀熟又想来, 8596
- 8网传比亚迪一员工泄露华为机密 8505
- 9滴滴出行被投诉价格操纵,网约 8215
- 10顶风作案?金山WPS被指套娃 7230



