从算力、数据、算法、工程化等维度看AI的未来
本文作者:王元(苏宁金融研究院金融科技研究中心主任助理),题图来自:视觉中国
2020年是不寻常的一年,全球的健康、贸易、经济、文化、政治和科技领域,无不发生着深刻的变化。笔者所在的科技领域,也恰逢现代人工智能(简称AI)发展10周年。前10年,人工智能技术得到了长足的发展,但也留下许多问题有待解决。
那么,未来AI技术将会如何发展呢?本文将结合学术界、工业界的研究成果,以及笔者个人研究见解,从算力、数据、算法、工程化4个维度,与读者一起探索和展望AI发展的未来。
一、数据
我们首先分析数据的发展趋势。数据对人工智能,犹如食材对美味菜肴,过去10年,数据的获取无论是数量,还是质量,又或者是数据的种类,均增长显著,支撑着AI技术的发展。未来,数据层面的发展会有哪些趋势呢,我们来看一组分析数据。
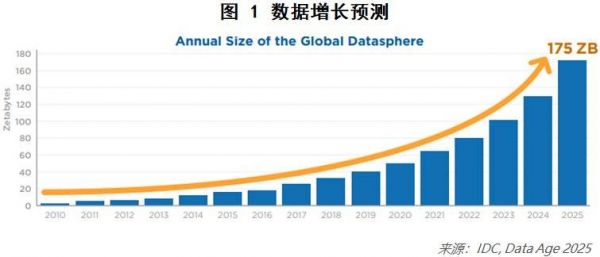
首先,世界互联网用户的基数已达到十亿量级,随着物联网、5G技术的进一步发展,会带来更多数据源和传输层面的能力提升,因此可以预见的是,数据的总量将继续快速发展,且增速加快。参考IDC的数据报告(图1),数据总量预计将从2018年的33ZB(1ZB=106GB),增长到2025年的175ZB。
其次,数据的存储位置,业界预测仍将以集中存储为主,且数据利用公有云存储的比例将逐年提高,如图2、图3所示。
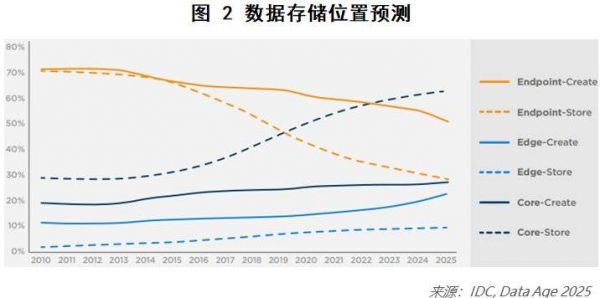
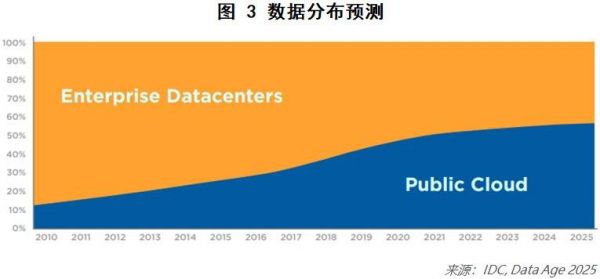
以上对于未来数据的趋势,可以总结为:数量持续增长;云端集中存储为主;公有云渗透率持续增长。站在AI技术的角度,可以预期数据量的持续供给是有保证的。
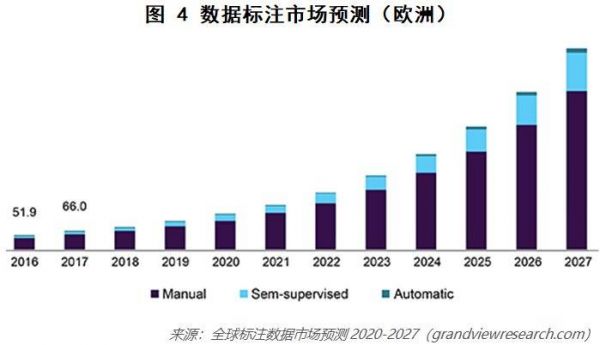
另一个方面,AI技术需要的不仅仅是原始数据,很多还需要标注数据。标注数据可分为自动标注、半自动标注、人工标注3个类别。
那么,标注数据未来的趋势会是怎样的?
我们可从标注数据工具市场的趋势窥探一二,如图4所示。可以看到,人工标注数据在未来的5年~10年内,大概率依然是标注数据的主要来源,占比超过75%。
通过以上数据维度的分析与预测,我们可以得到的判断是,数据量本身不会限制AI技术,但是人工标注的成本与规模很可能成为限制AI技术发展的因素,这将倒逼AI技术从算法和技术本身有所突破,有效解决对数据特别是人工标注数据的依赖。
二、算力
我们再来看看算力。算力对于AI技术,如同厨房灶台对于美味佳肴一样,本质是一种基础设施的支撑。
算力指的是实现AI系统所需要的硬件计算能力。半导体计算类芯片的发展是AI算力的根本源动力,好消息是,虽然半导体行业发展有起有落,并一直伴随着是否可持续性的怀疑,但是半导体行业著名的“摩尔定律”已经经受住了120年考验(图5),相信未来5年~10年依然能够平稳发展。
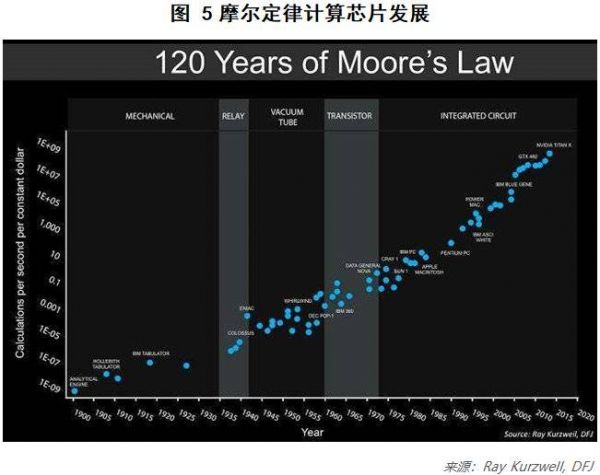
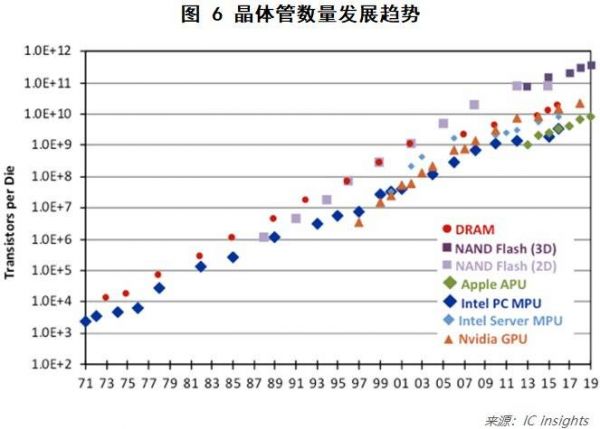
不过,值得注意的是,摩尔定律在计算芯片领域依然维持,很大原因是因为图形处理器(GPU)的迅速发展,弥补了通用处理器(CPU)发展的趋缓,如图6所示,从图中可以看出GPU的晶体管数量增长已超过CPU,CPU晶体管开始落后于摩尔定律。
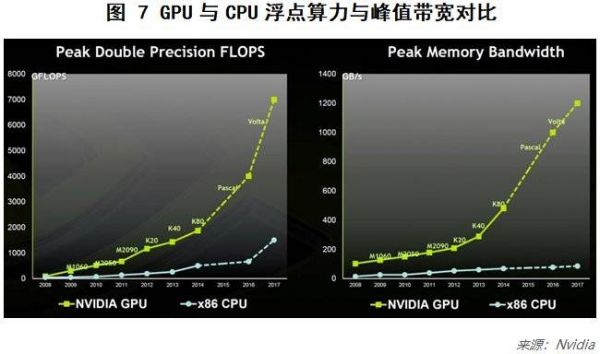
当然,半导体晶体管数量反映整体趋势可以,但还不够准确地反映算力发展情况。对于AI系统来说,浮点运算和内存是更直接的算力指标,下面具体对比一下GPU和CPU这2方面的性能,如图7所示。可以看出,GPU无论是在计算能力还是在内存访问速度上,近10年发展远超CPU,很好的填补了CPU的性能发展瓶颈问题。
另一方面,依照前瞻产业研究院梳理的数据,就2019年的AI芯片收入规模来看,GPU芯片拥有27%左右的份额,CPU芯片仅占17%的份额。可以看到,GPU已成为由深度学习技术为代表的人工智能领域的硬件计算标准配置,形成的原因也十分简单,现有的AI算法,尤其在模型训练阶段,对算力的需求持续增加,而GPU算力恰好比CPU要强很多,同时是一种与AI算法模型本身耦合度很低的一种通用计算设备。
除了GPU与CPU,其他计算设备如ASIC、FGPA等新兴AI芯片也在发展,值得行业关注。鉴于未来数据大概率仍在云端存储的情况下,这些芯片能否在提高性能效率的同时,保证通用性,且可以被云厂商规模性部署,获得软件生态的支持,有待进一步观察。
三、算法
现在我们来分析算法。AI算法对于人工智能,就是厨师与美味佳肴的关系。过去10年AI的发展,数据和算力都起到了很好的辅助作用,但是不可否认的是,基于深度学习的算法结合其应用取得的性能突破,是AI技术在2020年取得里程碑式发展阶段的重要原因。
那么,AI算法在未来的发展趋势是什么呢?这个问题是学术界、工业界集中讨论的核心问题之一,一个普遍的共识是,延续过去10年AI技术的发展,得益于深度学习,但是此路径发展带来的算力问题,较难持续。下面我们看一张图,以及一组数据:
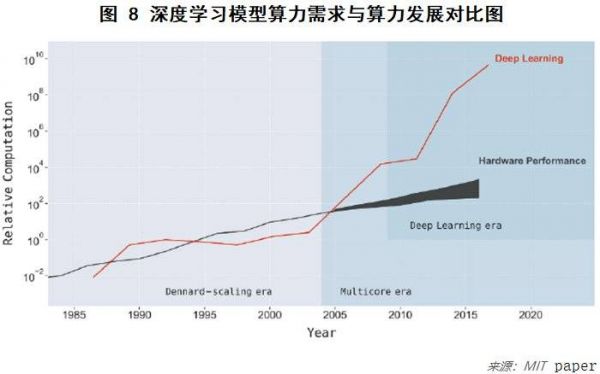
1. 根据OpenAI最新的测算,训练一个大型AI模型的算力,从2012年开始计算已经翻了30万倍,即年平均增长11.5倍,而算力的硬件增长速率,即摩尔定律,只达到年平均增速1.4倍;另一方面,算法效率的进步,年平均节省约1.7倍的算力。这意味着,随着我们继续追求算法性能的不断提升,每年平均有约8.5倍的算力赤字,令人担忧。一个实际的例子为今年最新发布的自然语义预训练模型GPT-3,仅训练成本已达到约1300万美元,这种方式是否可持续,值得我们思考。
2. MIT最新研究表明,对于一个过参数化(即参数数量比训练数据样本多)的AI模型,满足一个理论上限公式:
上述公式表明,其算力需求在理想情况下,大于等于性能需求的4次方,从2012年至今的模型表现在ImageNet数据集上分析,现实情况是在9次方的水平上下浮动,意味着现有的算法研究和实现方法,在效率上有很大的优化空间。
3. 按以上数据测算,人工智能算法在图像分类任务(ImageNet)达到1%的错误率预计要花费1亿万亿(10的20次方)美元,成本不可承受。
结合前文所述的数据和算力2个维度的分析,相信读者可以发现,未来标注数据成本、算力成本的代价之高,意味着数据红利与算力红利正在逐渐消退,人工智能技术发展的核心驱动力未来将主要依靠算法层面的突破与创新。就目前最新的学术与工业界研究成果来看,笔者认为AI算法在未来的发展,可能具有以下特点:
(1)先验知识表示与深度学习的结合
纵观70多年的人工智能发展史,符号主义、连接主义、行为主义是人工智能发展初期形成的3个学术流派。如今,以深度学习为典型代表的连接主义事实成为过去10年的发展主流,行为主义则在强化学习领域获得重大突破,围棋大脑AlphaGo的成就已家喻户晓。
值得注意的是,原本独立发展的3个学派,正在开始以深度学习为主线的技术融合,比如在2013年,强化学习领域发明了DQN网络,其中采用了神经网络,开启了一个新的研究领域称作深度强化学习(Deep Reinforcement Learning)。
那么,符号主义类算法是否也会和深度学习进行融合呢?一个热门候选是图网络(Graph Network)技术,这项技术正在与深度学习技术相融合,形成深度图网络研究领域。图网络的数据结构易于表达人类的先验知识,且是一种更加通用、推理能力更强(又称归纳偏置)的信息表达方法,这或许是可同时解决深度学习模型数据饥渴、推理能力不足以及输出结果可解释性不足的一把钥匙。
(2)模型结构借鉴生物科学
深度学习模型的模型结构由前反馈和反向传播构成,与生物神经网络相比,模型的结构过于简单。深度学习模型结构是否可以从生物科学、生物神经科学的进步和发现中吸取灵感,从而发现更加优秀的模型是一个值得关注的领域。另一个方面,如何给深度学习模型加入不确定性的参数建模,使其更好的处理随机不确定性,也是一个可能产生突破的领域。
(3)数据生成
AI模型训练依赖数据,这一点目前来看不是问题,但是AI模型训练依赖人工标注数据,是一个头痛的问题。利用算法有效解决或者大幅降低模型训练对于人工标注数据的依赖,是一个热点研究领域。实际上,在人工智能技术发展过程中一直若隐若现的美国国防部高级研究计划局(DARPA),已经将此领域定为其AI3.0发展计划目标之一,可见其重要程度。
(4)模型自评估
现有的AI算法,无论是机器学习算法,还是深度学习算法,其研发模式本质上是通过训练闭环(closed loop)、推理开环(open loop)的方式进行的。是否可以通过设计模型自评估,在推理环节将开环系统进化成闭环系统也是一个值得研究的领域。在通信领域,控制领域等其他行业领域的大量算法实践表明,采用闭环算法的系统在性能和输出可预测性上,通常均比开环系统优秀,且闭环系统可大幅降低性能断崖式衰减的可能性。闭环系统的这些特性,提供了对AI系统提高鲁棒性和可对抗性的一种思路和方法。
四、工程化
上文已经对人工智能数据、算力、算法层面进行了梳理和分析,最后我们看看工程化。工程化对于人工智能,如同厨具对于美味佳肴一样,是将数据、算力、算法结合到一起的媒介。
工程化的本质作用是提升效率,即最大化利用资源,最小化减少信息之间的转换损失。打一个简单的比喻,要做出美味佳肴,食材、厨房灶台、厨师都有,但是唯独没有合适的厨具,那么厨师既无法发挥厨艺(算法),又无法处理食材(数据),也无法使用厨房灶台的水电气(算力)。因此,可以预见,工程化未来的发展,是将上文提到的算力与算法性能关系,从现在的9次方,逼近到理论上限4次方的重要手段之一。
过去10年,AI工程化发展,已形成一个明晰的工具链体系,近期也伴随着一些值得关注的变化,笔者将一些较为明显的趋势,汇总如下:
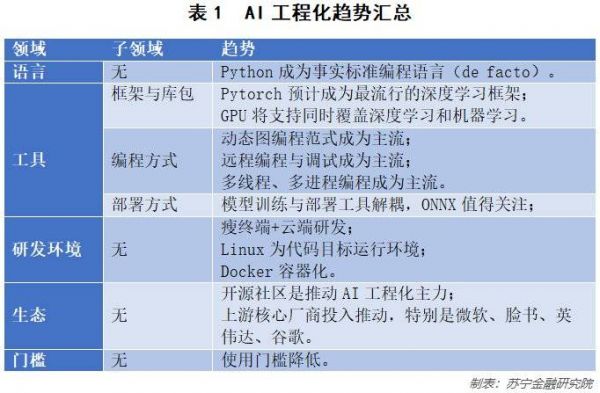
总结来说,AI工程化正在形成从用户端到云端的,以Python为编程语言的一整套工具链,其3个重要的特点为:远程编程与调试,深度学习与机器学习的GPU加速支持,以及模型训练与推理工具链的解耦。与此同时,产业链上游厂商对开源社区的大量投入,将为中下游企业和个人带来工具链的技术红利,降低其研发门槛和成本,笔者认为微软、脸书、英伟达3家上游厂商主推的开源工具链尤其值得关注。
五、结语
对于人工智能技术过去10年发展取得的成就,有人归因于数据,也有人归因于算力。未来人工智能技术发展,笔者大胆预测,算法将是核心驱动力。同时,算法研发的实际效率,除了算法结构本身,还取决于设计者对先进工具链的掌握程度。
未来10年,科技界是否能用更少的数据,更经济的算力,获得真正意义上的通用智能呢?我们拭目以待。
相关推荐
从算力、数据、算法、工程化等维度看AI的未来
从苹果A14芯片看AI算力的新摩尔定律
如何看待人工智能未来十年的发展?
苹果A系列芯片的三年AI进化:为何要大规模升级AI算力?
建超算中心、开源核心算法,商汤开辟AI开放战场
AI算力报告:未来五年,AI芯片复合增⻓率将达到53%
36氪首发 | AI边缘端算力升级趋势下,「米文动力」获得「北汽产投」领投的数千万A+轮融资
算力即权力
新基建的背后,是一场算力之争
从联想到比特大陆,中国的算力芯片之路
网址: 从算力、数据、算法、工程化等维度看AI的未来 http://www.xishuta.com/newsview29204.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95178
- 2人类唯一的出路:变成人工智能 20885
- 3报告:抖音海外版下载量突破1 20771
- 4移动办公如何高效?谷歌研究了 20054
- 5人类唯一的出路: 变成人工智 20036
- 62023年起,银行存取款迎来 10307
- 7网传比亚迪一员工泄露华为机密 8456
- 8五一来了,大数据杀熟又想来, 8338
- 9滴滴出行被投诉价格操纵,网约 7960
- 10顶风作案?金山WPS被指套娃 7213



