Hadoop创始人聊数字化变革:性能和成本不再是唯二的考虑因素
编者按:本文来自微信公众号“大数据文摘”(ID:BigDataDigest),作者:刘俊寰,36氪经授权发布。

2020腾讯全球数字生态大会如约而至。
在今年的腾讯全球数字生态大会上,腾讯介绍了AI、5G等技术领域的最新进展,还请出了Hadoop创始人Doug Cutting站台,讲述了他对于数字化变革的看法。
此外,在刚刚结束的大数据专场中,腾讯云公布了大数据平台的相关数据。目前,腾讯的算力弹性资源池达20万,每日分析任务数达1500万,每日实时计算次数超过30万亿次,每日接入数据条数超过35万亿条,训练数据维度达1万亿。
之后,腾讯还重磅发布了全链路数据开发平台WeData,同时发布和升级了流计算服务、云数据仓库、ES、企业画像等6款核心产品。进一步优化和提升了腾讯云大数据的全托管能力,助力企业从基础设施层、场景开发层以及行业应用层快速构建一站式大数据平台能力。
Doug Cutting:不能从管理层着手,要从更低层次细节,“小步迭代”推动
腾讯云副总裁刘煜宏在发布会上提到,疫情加速了企业的数字化进程的发展。
其中,大数据作为基础能力,支持了所有腾讯云业务的发展,比如我们每天都在使用的健康码。

Hadoop创建人Doug Cutting对此表示认同,他认为,随着社会数据量级的不断增加,我们的社会正在经历具有重大意义的数字化转型阶段。
“软件成为进步的主要来源。”
Doug Cutting也基于自己的一些经验,提出了几点建议。
首先是创新。我们需要加快创新的步伐,要实现创新,我们就需要寻找最能让我们快速创新的技术和工具,在这里我们不应该忽略了开源的力量。
比如,2000年,Doug Cutting开发了Lucene,经过二十年发展,Lucene已经成为当前最完善最受欢迎的检索引擎。可能Lucene不是业界最好的,很大一部分原因是因为Cutting在一开始就确定了开源的发展路线,用户可以加入整个项目的建设,实现真正的用户驱动,这对于新平台来说尤为重要。
在Lucene之后,Cutting做了Hadoop,扩大了计算范围。在近几年的发展中,人们围绕Hadoop做了很多更新的应用,形成了一个生态,甚至在其中Hadoop本身已经变得不那么重要了。
可以看出,开源不仅可以更快地提升单个技术,对于整个开源社区、开源环境来说都是十分重要的。
其次,在企业的发展中,往往规模越大的组织就越难进行转变。
Cutting指出,数字化变革不能从上层的管理层着手,要从细节的小部分、从更低的层次推动,这种小步迭代的方法在长期看来是更需要的。同时,公司必须要有管理能力,要从上层的组织方进行规划,实现安全、监督和限制,也不应忘记保持数据的一致性和协调性。
最后,Cutting表示,性能和成本不能再作为唯二的首要考虑因素,对社会和用户的影响正在变得越来越重要,这就要求我们把涉及到用户、数据的更多维度的因素囊括进来。
至于企业应该如何部署自己的大数据能力,Cutting认为,云已经成为主要的部署方式,尽管云存在一些问题,但总的来说云端的优势更有价值。并且,公司也应该多考虑混合系统的形式,以应对快速变化的数据现状。
腾讯云重磅发布大数据平台算力!日实时计算量超40万亿
也正是基于“从小的地方、从更低的层次推动”的理念,在今年的发布会上,腾讯把重点放在了产品开发层。
刘煜宏在发布会现场先公布了腾讯云大数据平台的算力数据:算力弹性资源池达500万核,每日分析任务数达1500万,每日实时计算次数超过40万亿,能支持超过一万亿维度的数据训练。

之后,腾讯云大数据产品中心副总经理雷小平介绍到,腾讯大数据能力其实分为三层,产品开发层是中间层。
腾讯大数据能力的第一层是底层基础的存储计算设施,典型产品如EMR、神盾联邦计算。这一层主要要解决的问题,除了最基本的提供基础设施之外,还能够帮助企业运维的工程师快速构建一个性能比较卓越、并且成本很低廉更安全的算力。
中间一层是产品开发层,这一层强调的是开箱即用。用一个平台搞定某个业务场景的开发的所有事情,可以让企业的开发人员更多地去做业务相关的事情,不用太多考虑平台的东西。
最上面是应用层,腾讯云会提供各种各样的比较接近业务的SaaS化的产品,比如营销的能力、增长的能力、BI的能力、风控的能力。
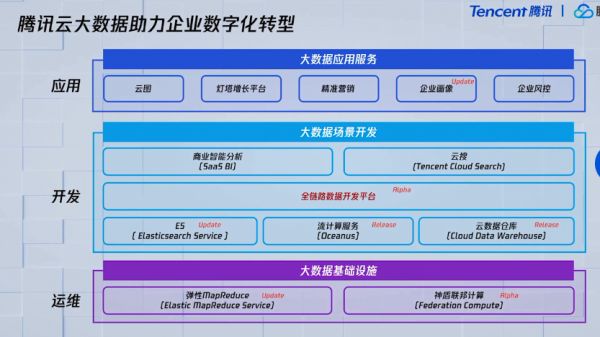
重磅发布全链路大数据平台WeData
作为中间层的重磅代表新产品,腾讯云推出全新的全链路数据开发平台WeData,WeData是一个一站式的大数据开发平台,打通了通用大数据开发和数据治理的过程中的所有环节。
雷小平表示,WeData主要解决了三个问题。
第一个问题是解决希望通过WeData,能够把企业所有的元数据管到一起,不管是存在Hive还是其他地方。这样的话,我们就能在一个地方看到所有的元数据,然后把不同平台的数据打通进行计算。
第二个问题是,希望把大数据开发整个链条从数据的集成到开发到测试到发布到调度等,所有的过程放到一个平台上面。有了开发之后,再上面希望把一个企业数据治理相关的东西集成进来,包括数据的血缘、数据的地图、数据的质量等等。
第三块是在企业、客户侧的应用。首先是安全方面,雷小平介绍到,在年中时候,微盟的数据出现了人为误操作的问题,腾讯云花了一个星期帮助恢复了数据,不仅如此,腾讯给微盟提供了一整套的大数据的安全解决方案,从它的数据的访问安全到整个服务的安全到数据本身的安全,做了一整套的安全方案。

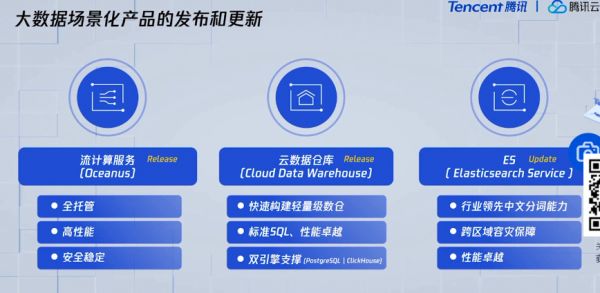
除了WeData外,腾讯还发布了其他几款面向场景化的一些产品。比如流计算的全托管的服务Oceanus,它能够帮助企业快速建立一个计算的能力,以及云数仓,是一个基于GP进行打造的,还有一个就是ES。
专访腾讯云大数据负责人:安全与融合是未来发展重点
在腾讯的这次全球数字生态大会之前,文摘菌提前采访到了腾讯云大数据基础平台总经理陈鹏,和腾讯云大数据产品中心副总经理雷小平。
采访过程中,二位透露了腾讯云最新的大数据产品WeData,以及腾讯云本身的更多内容。
首先,针对腾讯大数据目前包括团队、产品、研发、业务场景的情况,陈鹏介绍到,从2018年至今,通过开源协同,腾讯把原来各个业务模块的大数据做了一个整合,目前,腾讯内部大数据的基础设施基本上实现了协同整合。
不仅如此,在内部大数据平台整合的过程中,以前一些小众的需求,在内部协同的背景下,都可以在统一平台上得到满足。
比如,政企客户的一些需求在腾讯内部是不会出现的。假设,广东省公安厅需要做分析计算,在传统意义上,广东省公安厅不会把各个市的数据放在一起,这就会引发数据孤岛的现象。在这样的情况下,就需要跨源、跨域、跨类型、跨IDC的分析需求。这样的需求从外部进入到腾讯的业务线后,就能让平台在未来演进的方向上多一个思考视角。
近年来,随着大数据的发展,大数据造就了AI,但AI却没有很好的赋能大数据,此外,安全问题也逐渐成为大数据社区的短板。融合与安全,这就构成了未来大数据发展的两大方向。
那如何做到融合,陈鹏指出,下一代的计算平台主要应该围绕安全、智能和统一。
第一是安全,虽然大数据本身就是采用集群解决孤岛问题,但是真正的问题在于,一部分数据分散后,再把它聚集起来,你没有办法把数据整合在一起做一个集群来解决,这就把问题分散给了不同团队,职能部门不同,数据库也不相通,这就导致了大数据发展面临的问题。
数据安全涉及到权限的管控安全、计算安全,以及存储安全。就腾讯内部的系统而言,部门与部门之间,数据的隐私性保护是非常高的,大数据安全本身是一个生态,涉及大数据的各个系统组件,所以安全必须要跟每一个环节联系在一起。
安全问题不像SQL或者其他,大数据在这一块没有标准而言,腾讯云内部从接入到落地、计算、清洗、分析,到最后的报表查看,平台的全链路都把安全串起来了。因此能够保证数据使用者在使用数据过程中的每一个操作都记录在案,在最大程度上保证了数据安全。
雷小平补充道,在云上,腾讯吸收内部和外部的不同经验,将其结合在了一起,做了一整套安全方案,主要包括以下三个维度。
第一个维度是用户的数据访问的安全,这包括了哪些人能够访问数据,这个人是一个合法的人还是一个冒充的人,以及他能访问哪些数据,具体到这些数据的哪些字段,是可读还是可写。这些都做了比较细粒度的管控。
第二个维度是服务安全。这是对整个数据的容灾,比如用户在操作的时候不小心把这个数据删掉了,那这个数据能不能快速恢复等。以及在数据本身的存储上,如果是某一个部分挂掉了,或者某一个机房挂掉了,怎么样保障数据的安全。
第三个维度是上层应用,对于数据内容做安全校验。这个服务是用户可以选的,也就是说,腾讯有一整套系统能够识别用户的数据里面哪些是身份证号,哪些是密码,这样可以通过一些接口让用户在写数据进来的时候自动加密、脱敏等等。除此之外,腾讯还做了数据访问频率的审计,可以简单地将其理解为一层增值服务。
总的来说,云就通过访问的安全、服务的安全、数据的安全做到全链路的安全保护,这套安全能力在整个国内的云市场还是比较领先的。
安全之后是智能,智能就是怎么让A帮助B,这是在AB融合过程中的重点。现在集群规模已经达到了十万台,基本上每年按照百分之五十左右的规模发展,几年后,整个大数据的规模可能达到几十万台。但现在,大数据还需要人工辅助解决一些运营问题,希望随着技术的发展,能够做到将线上运行的数据回流反馈,再基于机器学习获得智能化的决策,基于这些决策和指标,进行后期调度性能、驱动硬件的定制。
最后是统一,这里涉及框架的统一、AB技术融合统一等。
从框架统一来讲,大数据的技术栈目前发展得已经非常复杂了,单纯说计算这一块,现在有Spark、Hadoop,发展过程中,同质的系统非常混乱。在这样的情况下,如何保证企业本身不会被业界这些复杂的系统影响,以及怎么不影响整体架构的延伸。
AB技术融合统一,AB底层算子和分布式运行有着很强的相似性,比如大数据的join、aggregator、sort和AI的grad、dot、softmax等,通过运行的机制上面做一些融合;在计算引擎方面,通过统一批、流、图三种计算形态,涵盖DAG、PS、MPI多种shuffle模式,cost-based optimization,统一执行计划优化,还有基于编译技术软硬件集合,通过代码生成适配异构硬件,计算型算子下推到GPU、FPGA等。从这些角度讲,AB融合是一个体系化的融合,不是一个单点的融合,这也是个趋势,最终能给用户带来一站式的数据处理体验。
相关推荐
Hadoop创始人聊数字化变革:性能和成本不再是唯二的考虑因素
瞄准5G室分千亿市场,「唯得科技」为运营商解决成本难题
工业品销售的发展、变革、关键点,我们和 30 岁、营收过百亿的「鑫方盛」聊了聊
宽带资本刘唯:产业互联网投资策略及思考
融资首发 | 资本押注云原生数据库,偶数完成B轮融资
浅谈大宗物流数字化:产业互联网变革的必取之地
36氪专访 | 腾讯930变革“设计师”杨国安:数字化转型,最难还是处理人的问题
传闻再起:中国手机厂商唯“芯”论可以休矣?
唯捷城配完成1亿元B+轮战略融资,华润润湘联和基金战略领投
咖啡连锁如何突围?我们和印尼 Kopi Kenangan 的创始人聊了聊
网址: Hadoop创始人聊数字化变革:性能和成本不再是唯二的考虑因素 http://www.xishuta.com/newsview30802.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 94991
- 2人类唯一的出路:变成人工智能 19561
- 3报告:抖音海外版下载量突破1 19300
- 4移动办公如何高效?谷歌研究了 18798
- 5人类唯一的出路: 变成人工智 18666
- 62023年起,银行存取款迎来 10162
- 7网传比亚迪一员工泄露华为机密 8236
- 8五一来了,大数据杀熟又想来, 7158
- 9顶风作案?金山WPS被指套娃 7120
- 10大数据杀熟往返套票比单程购买 7069



