为AI而生的IPU芯片,或挑战GPU的霸主位?
在CPU芯片领域,延续至今的“摩尔定律”正在随着制程工艺逼近物理极限而有了延缓的趋势,甚至失效的可能。就在摩尔定律的增长放缓脚步的同时,半导体芯片的计算也正在从通用走向专用,其中AI计算正是其中增长最快的一种专用计算。
现在,AI计算正在接棒摩尔定律,延续并超越其倍增神话。2019年,OpenAI发布了AI算力的增长情况,结果显示AI算力以3.4个月的倍增时间实现了指数增长,从2012年起,该指标已经增长了30万倍。
在AI算力爆炸式增长的过程中,英伟达的GPU功不可没。广为人知的一个故事就是2012年,来自多伦多大学的Alex和他的团队设计了AlexNet的深度学习算法,并用了2个英伟达的GTX580 GPU进行训练后,打败了其他所有计算机视觉团队开发的算法,成为那一届ImageNet的冠军。
此后,在计算机视觉和自然语言处理领域,GPU的高并行计算能力得到了充分的发挥,英伟达的GPU也随着AI第三次浪潮的崛起而迎来井喷发展。与此同时,更多为机器学习而专门定制的专用芯片开始出现,比如专用集成电路(ASIC)的张量处理单元TPU、神经网络单元NPU以及半定制芯片FPGA等等。
2018年底,英国一家名为Graphcore的创业公司推出了一种专门用于AI计算的处理器芯片IPU(Intelligence Processing Unit)。一经问世,IPU就受到AI界越来越多的关注。

ARM创始人,被称为英国半导体之父的赫曼·豪瑟曾为Graphcore的IPU给出很高评价,将其誉为“计算机史上三次革命中,继CPU和GPU之后的第三次革命”。赫曼在芯片产业的地位自然不容置疑,但由于Graphcore是英国芯片产业中为数不多的新生力量,难免赫曼有“护犊子”的打广告之嫌。
IPU出道2年时间,现已推出了量产第二代型号为GC2的IPU。那么,IPU的表现如何,与GPU相比有哪些优势之处,这是本文要重点探讨的问题。
GPU所开启的深度学习
一个广为人们熟知的例子就是,在计算机视觉发展初期的2011年,谷歌大脑想要在YouTube的视频中识别人类和猫,当时这样一个简单的任务,谷歌要动用一家大型数据中心内的 2,000 颗服务器 CPU,这些CPU的运行会产生大量的热量和能耗,关键是代价不菲,很少能有研究人员可以用得起这种规模的服务器。
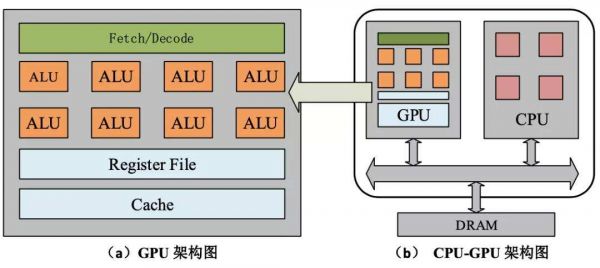
不过在当时,研究人员注意到了英伟达的GPU,斯坦福大学的吴恩达团队开始和英伟达合作,将GPU应用于深度学习。后来证明,只需要12颗英伟达GPU就可以达到相当于2000颗CPU提供的深度学习性能。此后越来越多的AI研究人员开始在GPU上加速其深度神经网络 (DNN)的训练。
现在我们都知道,GPU能够在深度学习的训练中大显身手,正是源于GPU的计算架构正好适用于深度学习的计算模式。深度学习是一种全新的计算模式,其采用的DNN算法包含数十亿个网络神经元和数万亿个连接来进行并行训练,并从实例中自己学习规律。
深度学习算法主要依赖的基本运算方法有矩阵相称和卷积浮点运算,而GPU多核架构在原本图像渲染中可以大规模处理矩阵乘法运算和浮点运算,很好地可以处理并行计算任务,使得DNN训练速度大幅提升。
此后,GPU成为辅助完成深度学习算法的主流计算工具,大放异彩。但GPU本身并非是专门为AI计算而设计的芯片,其中有大量的逻辑计算对于AI算法来说毫无用处,所以行业自然也需要专门针对AI算法的专用AI芯片。
近几年,全球已经有上百家公司投入到新型AI芯片的研发和设计当中,当然最终能够成功流片并推出商用的仍然是几家巨头公司和少数实力雄厚的独角兽公司。
这其中,2017年初创成立的Graphcore所研发的AI芯片IPU,则成为这些AI芯片当中的另类代表,因其不同于GPU架构的创新得到了业内的关注。而这正是我们要着重介绍的部分。
更适合AI计算的IPU芯片
近两年,AI 芯片出现了各种品类的井喷,其中甚至出现一些堪称疯狂的另类产品。
比如一家同样创立四年的AI芯片创业公司Cerebras Systems就发布了史上最大的半导体芯片Wafer Scale Engine(WSE),号称“晶圆级发动机”,拥有1.2万亿个晶体管,比英伟达最大的GPU要大出56.7倍。这块芯片主要瞄准的是超级计算和和大型云计算中心市场,其创新之处在于一体化的芯片设计大幅提高了内部的数据通信数据,但其架构仍然类似于GPU的计算架构。
而Graphcore的 IPU与GPU的架构差异非常大,代表的是一种新的技术架构,可以说是专门为解决CPU和GPU在AI计算中难以解决的问题而设计的。

IPU为AI计算提供了全新的技术架构,同时将训练和推理合二为一,兼具处理二者工作的能力。
我们以目前已经量产的IPU的GC2处理器来看,IPU GC2采用台积电的16nm工艺,拥有 236亿个晶体管,在120瓦的功耗下有125TFlops的混合精度,另外有45TB/s内存的带宽、8TB/s片上多对多交换总线,2.5 TB/s的片间IPU-Links。
其中,片内有1216个IPU-Tiles独立处理器核心,每个Tile中有独立的IPU核,作为计算以及In-Processor-Memory(处理器内的内存)。对整个GC2来说共有7296个线程(每个核心最多可以跑6个线程),能够支持7296个程序并行运行,处理器内的内存总共可以达到300MB,其设计思路就是要把所有模型放在片内处理。
首先,IPU作为一个标准的神经网络处理芯片,可以支持多种神经网络模型,因其具备数以千计到数百万计的顶点数量,远远超过GPU的顶点规模,可以进行更高潜力的并行计算工作。此外,IPU的顶点的稀疏特性,令其也可以高效处理GPU不擅长的稀疏的卷积计算。其次,IPU 也支持了模型参数的复用,这些复用特性可以获取数据中的空间或时间不变性,对于训练与推理的性能会有明显帮助。
其次,为解决芯片内存的宽带限制,IPU采用了大规模并行MIMD(多指令流多数据流)众核架构,同时,IPU架构做了大规模分布式的片上SRAM。片内300MB的SRAM,相对于GPU的GDDR、HBM来说,可以做到数十倍的性能提升,而且与访问外存相比,SRAM的片内时延基本可以忽略不计。
第三,IPU采用了高效的多核通信技术BSP(Bulk Synchronous Parallel)。IPU是目前世界上第一款采用BSP通信的处理器,支持内部1216个核心之间的通信以及跨不同的IPU之间的通信。通过硬件支持BSP协议,并通过BSP协议把整个计算逻辑分成了计算、同步、交换,能极大方便工程师们的开发工作。
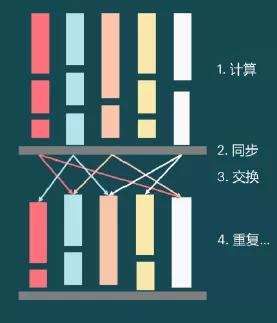
基于以上IPU的差异化特点,IPU在某些批量训练和推理中能够获得更好的性能、更低延时和更快网络收敛。片内的SRAM相对于片外存储,也有高带宽和低延时的优势。
今年7月,Graphcore发布了二代的Colossus MK2 IPU (MK2),以及包含四颗MK2芯片系统方案的IPU-Machine:M2000 (IPU-M2000),其核心数增加了20% ,达到1472个,8832个可并行执行的线程。片内SRAM则多出3倍,增加到900MB,互联扩展性能是上一代的16倍。显然在计算、数据和通信扩展层面,MK2都算是延续了第一代IPU堆料狂魔的作风。

由4个IPU芯片构成的IPU-M2000系统,可以提供大约1 PetaFLOPs的算力。基于IPU的多层级存储结构,与IPU Exchange Memory等技术优化,整体与GPU的HBM2存储比较,可以提供超过100倍的带宽以及大约10倍的容量,可以适用于更复杂的AI模型和程序。

计算加上数据的突破可以让IPU在原生稀疏计算中展现出领先GPU 10-50倍的性能优势,在通信上,Graphcore专为为AI横向扩展设计了IPU-Fabric,解决数据中心大规模计算横向扩展的关键问题。Graphcore将计算、数据、通信三者的突破技术结合,构建了大规模可扩展的IPU-POD系统,最终可以提供一个AI计算和逻辑进行解耦、系统易于部署、超低网络延时、高可靠的AI超算集群。
可以预计,未来IPU在各类AI应用中将具有更大的优势,而这也必然会引起英伟达的注意。那么,相较于英伟达GPU所占据的AI行业生态位的霸主地位,IPU会有哪些前景,也会遭遇哪些困境呢?
走向通用AI计算的“另辟蹊径”
如果回顾下AI芯片的发展经历,我们看到在经过这几年专用AI芯片的井喷之后,也开始面临一个尴尬困境,那就是ASIC芯片的灵活性或者说可编程性很差,对应的专用AI芯片只能应对一种算法应用,而算法本身则在3-6个月的时间就有可能变化一次,或许出现很多AI芯片还未上市,算法就已经发生进化的问题,一些AI芯片注定无法生产。当然,专用AI芯片的优势也很明显,在性能、功耗和效率上远胜更加通用的GPU,对于一些非常具体的AI应用场景,这些专用芯片就具有了巨大的收益。
从专注图像渲染崛起的英伟达的GPU,走的也是相当于ASIC的技术路线,但随着游戏、视频渲染以及AI加速需要的出现,英伟达的GPU也在向着GPGPU(General Purpose GPU)的方向演进。为保持其在GPU领域的寡头地位,使得英伟达必须一直保持先进的制程工艺,保持其通用性,但是要牺牲一定的效能优势。
这给后来者一定的启发,那就是AI芯片既要具备一定的灵活的可编程性(通用性),又要具备专用的高效性能优势。这为IPU找到了一个新的细分市场,也就是介入GPU不能很好发挥效能的神经网络模型,比如强化学习等类型,同时又避免的专用AI芯片的不可扩展性,能够部署在更大规模的云计算中心或超算中心,对新算法模型保持足够的弹性计算空间。
目前来看,IPU正在成为仅次于GPU和谷歌TPU的第三大部署平台,基于IPU的应用已经覆盖包括自然语言处理、图像/视频处理、时序分析、推荐/排名及概率模型等机器学习的各个应用场景。
典型的如通过IPU可以训练胸片,帮助医学人员快速进行新冠肺炎的诊断;如在金融领域,对涉及算法交易、投资管理、风险管理及诈骗识别的场景进行更快的分析和判断;此外在生命科学领域、通信网络等方面,都可以同IPU实现高于GPU性能的AI加速。
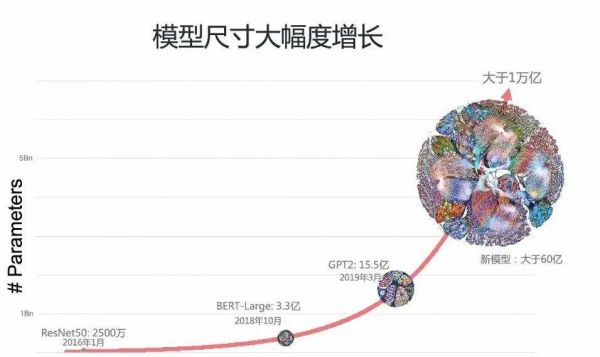
(NLP模型参数的指数增长)
当然,IPU想要在AI计算中拥有挑战GPU地位的资格,除了在性能和价格上面证明自己的优势之外,还需要在为机器学习框架提供的软件栈上提供更多选择,获得主流AI算法厂商的支持,在标准生态、操作系统上也需要有广泛的支持,对于开发者有更方便的开发工具和社区内容的支持,才能从实际应用中壮大IPU的开发生态。
今年, AI芯片产业正在遭遇洗牌期,一些AI芯片企业黯然退场,但这并不意味着AI计算遭遇寒冬,反而AI算力正在得到大幅提升,以今年数量级提升GPT-3的出场就可以看出这样的趋势。
一个AI芯片从产出到大规模应用必须要经过一系列的中间环节,包括像上面提到的支持主流算法框架的软件库、工具链、用户生态等等,打通这样一条链条都会面临一个巨大挑战。
现在,GPU已经形成一个非常完整的AI算力生态链路,而IPU则仍然在路上,是否能真正崛起,还需要整个AI产业和开发者用实际行动来投票。
相关推荐
为AI而生的IPU芯片,或挑战GPU的霸主位?
AI芯片混战:云端和终端均有长足发展
从云到端,谷歌的AI芯片2.0
2018年全球最值得关注的AI芯片初创公司
特斯拉 AI 芯片的真正实力
处理35亿张图片+42台服务器+336块显卡,硅谷可怕的AI算力就是这么来的
英伟达的未来,不只是GPU
英伟达和英特尔的AI战事
探索摩尔定律之外的新路径,「登临科技」将GPU通用计算芯片功效提高3倍以上
人工智能芯片制造商「Graphcore」获 1.5 亿美元 D2 轮融资,总估值达 19.5 亿美元
网址: 为AI而生的IPU芯片,或挑战GPU的霸主位? http://www.xishuta.com/newsview31985.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95228
- 2人类唯一的出路:变成人工智能 21183
- 3报告:抖音海外版下载量突破1 21148
- 4移动办公如何高效?谷歌研究了 20339
- 5人类唯一的出路: 变成人工智 20338
- 62023年起,银行存取款迎来 10336
- 7五一来了,大数据杀熟又想来, 8596
- 8网传比亚迪一员工泄露华为机密 8505
- 9滴滴出行被投诉价格操纵,网约 8215
- 10顶风作案?金山WPS被指套娃 7230



