AI性能基准测试从此有了「中国标准」,英伟达、谷歌可以试试这套算力卷
编者按:本文来自微信公众号“量子位”(ID:QbitAI),作者:金磊,36氪经授权发布。
在秀算力这件事上,近几年一个叫MLPerf的AI性能基准测试,经常跃入人们的视线。
为了拿这个标准证明实力,英伟达、谷歌等「算力」大厂的表现,可谓是赚足了眼球。
早在2018年12月,也就是MLPerf首次出炉之际,英伟达便基于自家Tesla V100,在包括图像分类、物体分割、推荐系统等六项测试中均取得优秀成绩,拿下全场最佳。
而此后,英伟达更是频频刷榜,就在刚刚过去不久的最新性能测试中,英伟达又凭借A100 GPU打破了八项AI性能纪录。

谷歌方面也是毫不示弱,凭借4096块TPU V3将BERT的训练时间缩短到了23秒。
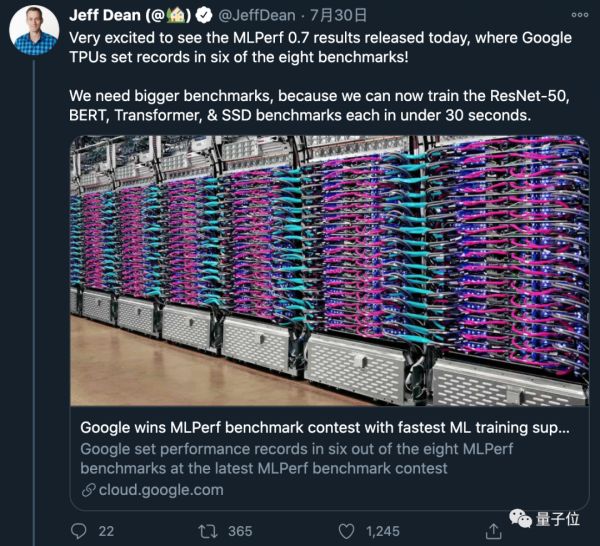
对此,谷歌AI掌门人Jeff Dean还在社交平台发文表示:
很高兴看到MLPerf 0.7的结果,谷歌TPU在八项基准测试中,创造了六项纪录。
我们需要(换)更大的标准了,因为我们现在在30秒内,就可以训练ResNet-50、BERT、Transformer、SSD 等模型。
那么问题来了,令这些「算力」大厂们竞相追逐的MLPerf这套「考题」,真的是「AI性能基准测试的唯一标准」吗?
不见得。
要达到理想的AI或者高性能计算(HPC)基准测试,具有三方面的挑战:
首先,基准工作负载(workload)需要表示关于硬件利用率、设置成本和计算模式等的实际问题。
其次,基准测试工作负载最好能够自动适应不同规模的机器。
最后,使用简单、较少的指标,就可以衡量AI应用上的整个系统性能。
反观MLPerf,正如Jeff Dean所言,它具有固定的工作负载大小,这本身或许就是个错误。
因为增加的算力,应当被用来解决更大规模的问题,而不是用更少的时间去解决相同的问题。
而像LINPACK这样的基准测试,在没有代表性工作负载的情况下,又无法反映AI的跨栈性能。
针对上述问题,清华大学、鹏城实验室、中科院计算所联合推出了一套「中国AI试卷」——AIPerf。
简单来说,AIPerf的特点如下:
基于的是自动化机器学习(AutoML)算法,能够实现深度学习模型的实时生成,对不同规模机器有自适应扩展性,并可检验系统对通用AI模型的效果。
通过全新的解析方式计算浮点数运算量,可快速准确的预测AI任务中需要的浮点数运算,以此计算浮点数运算速率并作为评测分数。
那么,中国的这套「AI试卷」具体难度几何?科学与否?
还请各位看官继续品读。
中国的这套「AI试卷」长什么样?
摊开这套「AI试卷」,全貌如下:
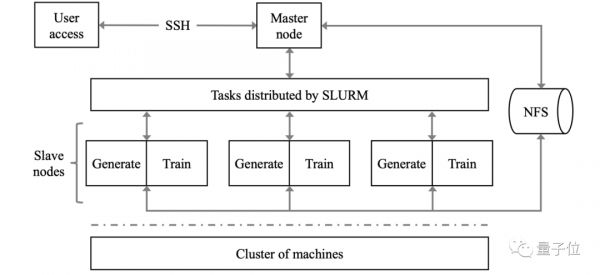
△ AIPerf基准测试工作流程图
刚才也提到,AIPerf是基于AutoML算法来实现,在框架方面,研究人员选择的是一款较为用户友好的AutoML框架——NNI(Neural Network Intelligence)。
但在此基础上,研究人员针对「AI加速器闲置」、「模型生成耗时」等问题,对NNI框架进行了修改。
AIPerf的工作流程如下:
通过SSH访问主节点,收集从属节点的信息,并创建SLURM配置脚本。
主节点通过SLURM,将工作负载并行和异步地分配给对应请求和可用资源的从属节点。
从属节点接收到工作负载后,并行地进行架构搜索和模型训练。
从属节点上的CPU,据当前历史模型列表搜索新的架构(该列表中包含了测试数据集上详细的模型信息和精度),然后将架构存储在缓冲区(如网络文件系统)中,以便后期训练。
从属节点上的AI加速器加载「候选架构」和「数据」,利用数据并行性与HPO一起训练后,将结果存储在历史模型列表中。
一旦满足条件(如达到用户定义的时间),运行就会终止。根据记录的指标计算出最终结果,然后上报。
做完这套「AI试卷」,得到的分数又该如何来衡量和排名呢?
我们知道,FLOPS是当前最常用来反映高性能计算整体计算能力的性能指标。
在这套「试卷」中,研究人员还是用FLOPS作为主要的指标,直接描述AI加速器的计算能力。
在AIPerf中,浮点数运算速率被当作一个数学问题来求解。通过对深度神经网络的分解,对每个部分的运算量进行解析的分析,得到浮点数运算量。
结合任务运行时间,即可得到浮点数运算速率并作为benchmark分数。
理论到位了,实验就要跟上。
硬件规格方面如下:

评估环境的详情如下:

最后,公布性能结果!
研究人员在各种规模的机器上运行了AIPerf这项基准测试,主要对两方面特性做了评估,分别是稳定性和可扩展性。
从10个节点到50个节点,最多有400个GPU。所有的中间结果,包括生成的架构、超参数配置、每个时间点的精度和时间戳,都记录在日志文件中。
下图展示了用不同规模的机器进行评估的「基准分数」和「规范分数」(单位均为FLOPS),随时间产生的变化。
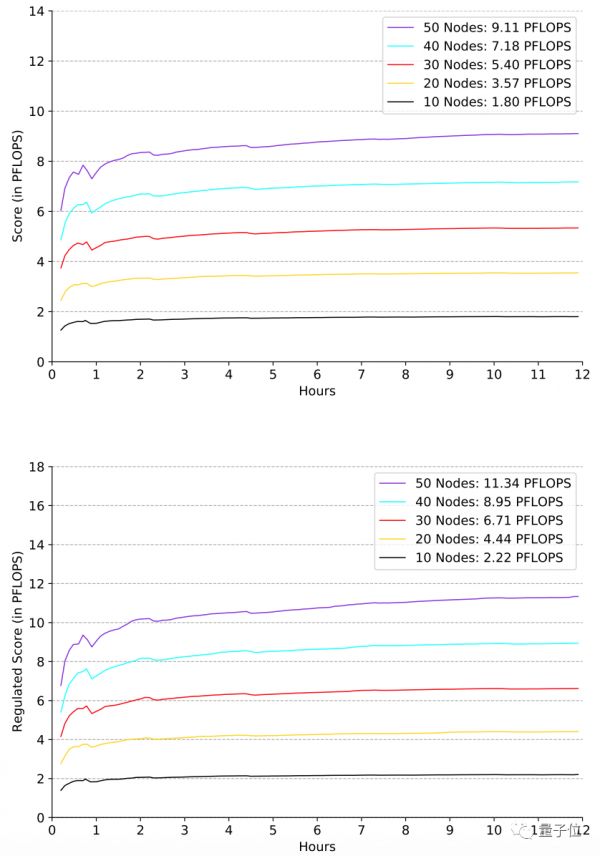
结果表明,AIPerf基准测试具有鲁棒性和线性可扩展性。
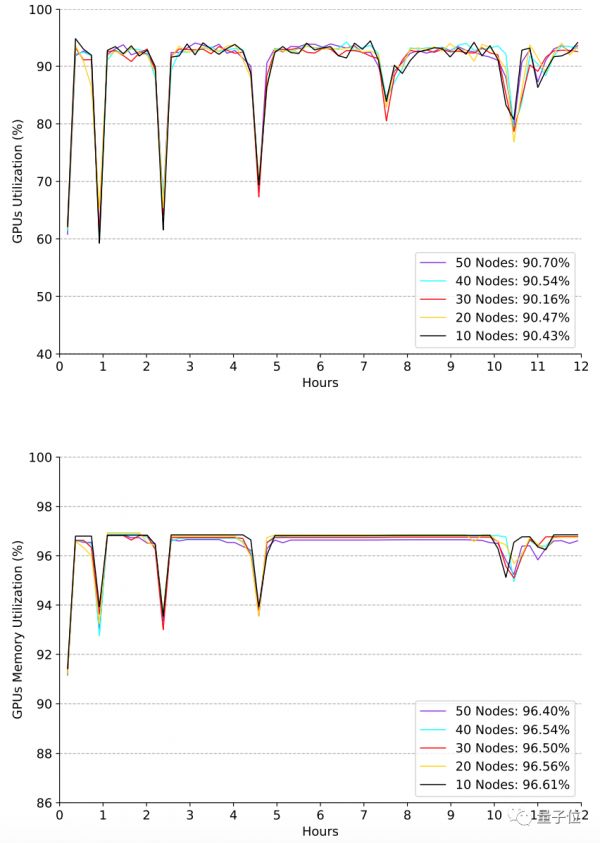
接下来,是在不同规模机器下,GPU及其内存利用率的相关评估。
从图中可以发现,AI训练卡整体的计算和内存利用率很高(均大于90%)。在不同模型之间的过渡阶段,由于数据的加载和计算图的编译等原因,利用率会有所下降。
为什么要出这套「试卷」?
「浏览试卷」后,就需要思考一个问题:
为什么要出AIPerf这套AI基准测试?
这个问题就需要「由表及里」地来看待。
首先,从表象来看,类似MLPerf和LINPACK基准测试程序,自身存在一些漏洞和问题:
要么工作负载大小是固定的,而算力的增加,应当用来解决更大规模的问题,限制了可扩展性。
要么在没有代表性工作负载的情况下,无法反映系统对AI的跨栈计算性能。
虽然诸如此类的评测标准,目前来看是具有一定的价值和意义,但客观存在的不足也是不容忽视。
毕竟在当前人工智能飞速发展的大环境下,算力显得格外重要,而完备及更加科学的「基准测试」,将有助于算力的发展。
由此看来,「基准测试」和「算力」更像一对作用力和反作用力。

其次,从深层意义来看,发展算力,是非常必要的。
对于高性能计算来说,早在1993年便诞生了「TOP500」榜单,从一开始的美国、日本霸榜,到中国算力的崛起,不难看出国家在这项建设中的投入。
原因很简单,高性能计算对于各个国家发展航天事业、石油勘探、水利工程,再到新兴的高科技产业,都起到至关重要的作用。
但伴随着AI的兴起,改变了一往传统高性能计算的「求解方法」——AI+HPC才是未来算力的发展趋势。

近年来TOP500榜单,便能体现这一点:
首台登顶榜首的ARM架构HPC,是基于富士通48/52核A64FX ARM。
排名第二的SUMMIT,采用IBM Power+NVIDIA V100。
……
榜单中近30%系统拥有加速卡/协处理器,也就是说,越来越多的系统配有大量低精度算术逻辑单元,用来支撑人工智能计算能力需求。
而在我国,也有越来越多的企业,开始或已经布局其中。
例如华为、浪潮、联想等,均拿出了自家强悍产品,在诸如TOP500、MLPerf等榜单中大显身手。
再从实际应用层面来看,或许你觉得发展算力对平民百姓并没有用,但其实不然。
恰好每年大血拼的「双11」即将来临,而每个电商平台背后,都有一套强有力的推荐系统,也就是用户经常看到的「猜你喜欢」功能。
推荐得准不准、快不快,很大程度上也是依赖于AI算力的强大与否。
再则,每年上千亿元成交额,能够保证及时付款成功,AI算力也是功不可没。
……
最后,回到最初的那个问题:
中国出的这套「AI试卷」,即ALPerf,英伟达、谷歌等老牌算力大厂又会有怎样的表现?
相关推荐
AI性能基准测试从此有了「中国标准」,英伟达、谷歌可以试试这套算力卷
AI性能基准测试,从此有了“中国标准”
英伟达和英特尔的AI战事
黄仁勋的「厨房演讲」,熬制的却是英伟达 GPU 史上最大性能飞跃
AI芯片大战背后:英特尔对英伟达虎视眈眈,国内芯片公司蠢蠢欲动
英特尔甩出视觉推理新杀器,性能超英伟达,大秀首款云端AI商用芯
最前线 | 英伟达发布GPU旗舰A100,采用7nma工艺,性能提升20倍
CES现场芯片巨头上演开年大战:AMD、英特尔、英伟达、高通展开对决
焦点分析 | 英伟达推出“算力怪兽” A100 , 国产云端AI芯片们如何破局
英伟达收购Arm的B面
网址: AI性能基准测试从此有了「中国标准」,英伟达、谷歌可以试试这套算力卷 http://www.xishuta.com/newsview33878.html
推荐科技快讯






- 1问界商标转让释放信号:赛力斯 95178
- 2人类唯一的出路:变成人工智能 20885
- 3报告:抖音海外版下载量突破1 20771
- 4移动办公如何高效?谷歌研究了 20054
- 5人类唯一的出路: 变成人工智 20036
- 62023年起,银行存取款迎来 10307
- 7网传比亚迪一员工泄露华为机密 8456
- 8五一来了,大数据杀熟又想来, 8338
- 9滴滴出行被投诉价格操纵,网约 7960
- 10顶风作案?金山WPS被指套娃 7213



