谷歌发布万亿参数语言模型, AI的语言功能真的可以超越人类吗?
编者按:本文来自微信公众号“将门创投”(ID:thejiangmen),作者:让创新获得认可,36氪经授权发布。

From: VentureBeat;编译: Shelly
掌握独特而深远的人类语言,是人工智能面临的最艰巨挑战之一。近年来,更为复杂的人类语言模型迅速发展。
2020年初,谷歌训练的语言模型终于能够在广泛的语言理解任务中击败人类,他们通过在更多数据上训练更大的网络,将BERT架构推向了极限。现在,这种T5模型在标注句子和找到问题的正确答案方面可以比人类表现得更好。
而在刚刚到来的2021年,谷歌又发布了万亿参数语言模型(trillion-parameter model),效果更加强大。那么可想而知,2021年,人类距离人工智能最重大的突破以及由此带来的无限可能,也许只有一步之遥。

在短短几年时间里,深度学习算法飞速进化,已经能够在围棋大赛中打败世界上最好的棋手,并能以不亚于人工识别的精准度来准确识别人脸。
但事实证明,掌握独特而深远的人类语言,是人工智能面临的最艰巨挑战之一。
这种情况会改变吗?

如果计算机能有效处理人类语言,那么这将彻底改变人类商业世界中的交往方式。目前,大多数公司并不具备足够的人力物力来回答客户的每一个问题。想象一下,如果一家公司能够在任何时间、任何频道上倾听理解和回答客户问题,世界会是什么样子?
已经有团队在与世界上最具创新精神的组织、技术平台展开合作,希望利用现有的巨大机会建立一对一的大规模客户对话生态系统,但这项目标任重道远。
脸书DeepFace:最早一代可匹敌人类精准度的人脸识别算法
回溯过往,直到2015年,能匹敌人工识别精准度的人脸识别算法才出现:脸书DeepFace的准确率为97.4%,略低于人工识别率97.5%。
作为参考,FBI的面部识别算法仅达到85%的准确率,这意味着仍然存在超过七分之一的情况存在误差。
脸书DeepFace的人脸识别
FBI的算法是由一组工程师手工编写的,对五官的识别,比如鼻子的大小和眼睛的相对位置,都是手动编码的。
而Facebook的算法则是先学习人脸特征,它使用了一种特殊的深度学习架构,我们称之为卷积神经网络。人眼的视觉皮层有不同层次,而它模仿了我们视觉皮层不同层次处理图像的方式。
作为普通人,我们不知道自己的眼睛是如何看见事物的,而算法学习了这些层次之间的联系。
脸书之所以能够做到这么高的准确率,是因为它恰到好处地利用了具有学习功能的架构和数百万用户在分享的照片中标记好友的高质量数据。
势如破竹:多语言模型成果频频
在逐渐进化的过程中,数百万物种都成功解决了视觉的问题,但语言却要复杂得多。据我们所知,人类是目前唯一使用复杂语言交流的物种。
不到十年前,人工智能算法只会计算特定单词出现的频率,尚不能理解文本是什么。但这种方法显然忽略了一个事实:单词还有同义词,而且不同的语境往往反映不同的意义。
2013年,Tomas Mikolov和他在谷歌的团队构建了一个能够学习单词含义的架构。他们提出的word2vec算法可以映射同义词,还可以对同义词的大小、性别、速度进行建模,甚至可以学习诸如国家和首都等函数的关系。
然而,理解上下文的能力仍处于缺失状态。
这一领域的真正突破发生在2018年,当时,谷歌引入了BERT模型。
Jacob Devlin和他的团队重新使用了一种典型的用于机器翻译的架构,并使其学习与句子上下文相关的单词含义。
通过引导这个模型去填补维基百科文章中缺失的单词,团队将语言结构嵌入到BERT模型中。
仅用有限数量的高质量标记数据,他们就能让BERT适应多种语言任务——从找到问题的正确答案到真正理解一个句子内容。

论文链接:https://arxiv.org/abs/1810.04805
语言理解有两个关键要素:正确的架构和海量的高质量数据。而他们正是第一个真正把握语言理解这两大要素的团队。
2019年,脸书的研究人员进一步推进该项研究。
他们在一个类似于BERT的模型上同时训练、学习了100多种语言。训练结果是:该模型在完成一种语言的学习后,能完成其他语言的相同任务。比如说,该模型能把英语的学习结果映射到学习阿拉伯语、汉语或印度语上。
这个模型在语言上的表现与BERT相同,而且从一种语言到另一种语言的转换错误可忽略不计。

论文链接:https://arxiv.org/abs/1907.11692
到了2020年初,谷歌训练的语言模型终于能够在广泛的语言理解任务中击败人类。
通过在更海量的数据中训练,谷歌将BERT的潜能发挥到了极限。现在,这种T5模型在标注句子和找到问题的正确答案方面已经比人类表现得更好。
而2020年10月发布的mT5模型,在从一种语言切换到另一种语言的表现几乎和双语者一样出色,但同时它又远不止是一个双语者——它可以同时处理100多种语言。

论文链接:https://arxiv.org/abs/2010.11934
今年1月,就在近几日,谷歌又公布了万亿参数模型(trillion-parameter model),使语言模型变得更加强大。
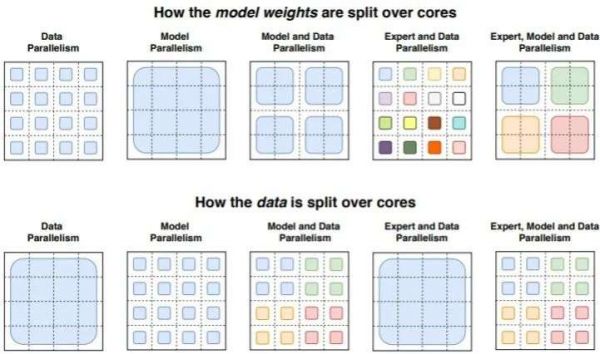
trillion-parameter model
回溯与展望:语言模型前景无限
想象一下:无论你使用哪种语言,聊天机器人都可以理解你的想法,它们能真正理解语境,还能记住过去的对话。你得到的信息不再是泛泛之言,而是真正切中主题的。
再想象一下:搜索引擎能够理解你的任何问题,即使你甚至打了错别字,搜索引擎也能秒懂你。
这样一来,你好像得到了一个了解公司所有程序的“AI同事”。对于新入职的小伙伴来说,它帮你迅速了解所有的行话。“不会看、看不懂公司公告的新同事”将成为过去式。
这也意味着,数据库的新时代即将到来:任何备忘录、电子邮件和报告将得到自动解释、存储和索引。
而这还只是冰山一角,目前来看,任何仍需要人类理解语言的程序,现在都处于被瓦解或被自动化代替的边缘。
Talk isn’t cheap:“语言天才”并不便宜
美妙的事情往往也暗藏“陷阱”:为什么这些算法不是随处可见呢?
一般来说,训练这些语言模型大概率需要极高的花费。举个例子,培训T5算法的云计算成本约为130万美元。
虽然谷歌的研究人员非常友好地分享了这些模型。但是,如果不在操作中对它们进行微调改善,就不能将它们挪为私用。
因此,即使大企业开源了这些模型,其他人如果想拿来直接使用也需要花费很高的成本。而且,一旦使用者针对特定的问题优化了这些模型,执行过程仍然需要消耗大量的计算能力和很长的时间。
随着时间的推移,随着各大公司在算法优化上的投入,我们将看到更多新应用出现。
进一步讲,如果大家相信摩尔定律,那么大约五年内我们将看到更复杂的应用诞生。另外,超越T5算法的新模型也将出现。
2021年初,我们距离人工智能最重大的突破以及由此带来的无限可能,也许只有一步之遥。
ref:
https://venturebeat.com/2021/01/17/language-ai-is-really-heating-up/
https://www.theverge.com/2014/7/7/5878069/why-facebook-is-beating-the-fbi-at-facial-recognition
https://venturebeat.com/2021/01/12/google-trained-a-trillion-parameter-ai-language-model/
相关推荐
谷歌发布万亿参数语言模型, AI的语言功能真的可以超越人类吗?
微软发布史上最大AI模型:170亿参数横扫各种语言建模基准,将用于Office套件
“男性说教”“茶里茶气”,我们的语言真的有性别差异吗?
强大如GPT-3,1750亿参数也搞不定中文?
自然语言处理最强 AI 模型 GPT-3:未来还有多少可能?(上)
要啥给啥的写作AI:新闻评论小说都能编,题材风格随便选,真假难辨,16亿参数模型已开源
揭秘动物语言翻译器:打着AI幌子的娱乐产品
对话乔姆斯基:语言、道德、人工智能和深度学习的未来
「玩秘」AI语音对话助理服务在小米手机上线,语言多样性覆盖度已达76%
Facebook 号称击败谷歌,推出最强聊天机器人
网址: 谷歌发布万亿参数语言模型, AI的语言功能真的可以超越人类吗? http://www.xishuta.com/newsview37806.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95254
- 2人类唯一的出路:变成人工智能 21423
- 3报告:抖音海外版下载量突破1 21393
- 4移动办公如何高效?谷歌研究了 20566
- 5人类唯一的出路: 变成人工智 20563
- 62023年起,银行存取款迎来 10359
- 7五一来了,大数据杀熟又想来, 8806
- 8网传比亚迪一员工泄露华为机密 8543
- 9滴滴出行被投诉价格操纵,网约 8429
- 10顶风作案?金山WPS被指套娃 7247



