软件吞噬硬件的AI时代,芯片跟不上算法进化可咋办?
编者按:本文来自微信公众号“品玩”(ID:pinwancool),作者:Decode,36氪经授权发布。
作为 AI 时代的幕后英雄,芯片业正经历着渐进而持续的变化。
2008 年之后,深度学习算法逐渐兴起,各种神经网络渗透到手机、App 和物联网中。与此同时,摩尔定律却逐渐放缓。摩尔定律虽然叫定律,但它不是物理定律或者自然定律,而是对半导体行业发展的一个观察或者说预测,其内容为:单个芯片集成度(集成电路中晶体管的密度)每两年(也有 18 个月的说法)翻倍,由此带来性能每两年提高一倍。
保证摩尔定律的前提,是芯片制程工艺进步。经常能在新闻上看到的 28nm、14nm、7nm、5nm,指的就是制程工艺,数字越小工艺越先进。随着制程工艺的演进,特别是进入 10nm 之后,逐渐逼近物理极限,难度越发加大,芯片全流程设计成本大幅增加,每一代较上一代至少增加 30%~50%。
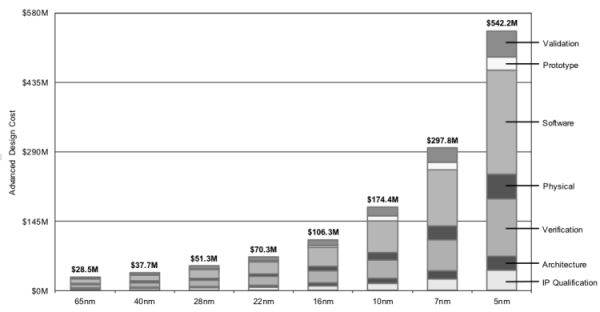
不同工艺节点的芯片设计制造成本,图片来自 ICBank
这就导致,AI 对算力需求的增长速度,远超通用处理器算力的增长速度。据 OpenAI 测算,从 2012 年开始,全球 AI 所用的计算量呈现指数增长,平均每 3.4 个月便会翻一倍,而通用处理器算力每 18 个月至两年才翻一倍。
当通用处理器算力跟不上 AI 算法的发展,针对 AI 计算的专用处理器便诞生了,也就是常说的“AI 芯片”。目前,AI 芯片的技术内涵正极大丰富着。从架构创新到先进封装,再到模拟人脑,都影响着 AI 芯片的走向。而这些变化的背后,都有着一个共同的主题:以更低功耗,产生更高性能。
更灵活
2017 年的图灵奖,颁给了计算机架构两位先驱 David Petterson 和 John Hennessy。2018 年在进行图灵奖演讲时,他们将主题聚焦于架构创新,指出计算体系结构正迎来新的黄金十年。正如他们所判断的,AI 芯片不断出现新的架构,比如来自英国 Graphcore 的 IPU——一种迥异于 CPU 和 GPU 的 AI 专用智能处理器,已经逐渐被业界认可,并且 Graphcore 也获得了微软和三星的战略资本支持。
而当下,一种名为 CGRA 的架构,在学界和工业界正受到越来越多的关注。CGRA 全称 Coarse Grained Reconfigurable Array(粗颗粒可重构阵列),是“可重构计算”理念的落地产物。
据《可重构计算: 软件可定义的计算引擎》一文介绍,这个理念最早出现在 20 世纪 60 年代,由加州大学洛杉矶分校的 Estrin 提出。由于过于超前,直到 40 年以后才获得系统性的研究。加州大学伯克利分校的 DeHon 等将可重构计算定义为具有以下特征的体系结构:在其制造后,芯片功能仍然可以定制,形成加速特定任务的硬件功能;计算功能的实现,主要依靠任务到芯片的空间映射。
简言之,可重构芯片强调灵活性,在制造出来后仍可通过编程调整,适应新算法。与之形成高度对比的,是 ASIC(application-specific integrated circuit,专用集成电路)。ASIC 芯片虽然性能高,但却缺乏灵活性,往往是针对单一应用或算法设计,难以匹配新算法。
2017 年,美国国防部高级研究计划局(Defence Advanced Research Projects Agency,即 DARPA)提出了电子产业复兴计划(Electronics Resurgence Initiative,简称 ERI)。该计划其中一个任务就是“软件定义芯片”,打造接近 ASIC 性能 、同时不牺牲灵活性的芯片。
按照进行重构时的粒度区别,可重构芯片可分为 CGRA 和 FPGA(field-programmable gate array,现场可编程逻辑门阵列)。FPGA 在工业界已经有一定规模应用,比如微软将 FPGA 芯片带入大型数据中心,用于加速 Bing 搜索引擎,验证了 FPGA 灵活性和算法可更新性。但 FPGA 有其局限性,不仅能效和 ASIC 仍有较大差距,而且重编程门槛比较高。
而 CGRA 由于实现原理上的差异,比 FPGA 能实现更加底层的重新编程,在面积效率、能量效率和重构时间上,都更有优势。可以说,CGRA 同时集成了通用处理器的灵活性和 ASIC 的高性能。

可重构计算架构与现有主流计算架构在能量效率和灵活性上的对比,图片来自《中国科学》
随着 AI 计算逐渐从云端下沉到边缘端和 IoT 设备,不仅算法多样性日益增强,芯片更加碎片化,而且保证低功耗的同时,也要求高性能。在这种场景下,高能效高灵活性的 CGRA 大有用武之地。
由于在结构上不统一、编程和编译工具不成熟、易用性上不够友好,CGRA 未被业界广泛使用,但已经可以看到一些尝试。早在 2016 年,英特尔便将 CGRA 纳入其至强处理器。三星也曾尝试将 CGRA 集成在 8K 高清电视和 Exynos 芯片中。
在中国本土,一家名为“清微智能”的公司,于 2019 年 6 月量产了全球首款 CGRA 语音芯片 TX210,同年 9 月又发布了全球首款 CGRA 多模态芯片 TX510。这家公司脱胎于清华大学魏少军教授牵头的可重构计算研究团队,他们从 2006 年起就进行相关研究。据芯东西 2020 年 11 月报道,语音芯片 TX210 已经出货数百万颗,而多模态芯片 TX510 在 11 月也已经出货十万颗以上,主要客户为智能门锁、安防和人脸支付相关厂商。
先进封装上位
如开篇所提到,由于制程工艺逼近物理极限,摩尔定律逐渐放缓。与此同时,AI 算法的进步,使其对算力需求增长迅猛,逼迫芯片行业在先进工艺之外探索新的方向,其中之一便是先进封装。
“在大数据和认知计算时代,先进的封装技术正在发挥比以往更大的作用。AI 的发展对高能效,高吞吐量互连的需求,正在通过先进的封装技术的加速发展来满足。”世界第三大晶圆代工厂格罗方德平台首席技术专家 John Pellerin 曾在一份声明中表示。
先进封装是相对于传统封装而言。封装是芯片制造的最后一步:将制作好的芯片器件放入外壳中,并与外界器件相连。传统封装的封装效率低,存在很大改良空间,而先进封装技术发力于提高集成密度。
先进封装里有很多技术分支,其中 Chiplet(小芯片/芯粒)是最近两年的大热门。所谓“小芯片”,是相对传统芯片制造方法而言。传统芯片制造方法,是在同一块硅片上,用同一种工艺制程去打造一块芯片。而 Chiplet 思路是将一块完整芯片的复杂功能进行分解,把存储、计算和信号处理等功能模块化成裸芯片(Die)。这些裸芯片可以用不同工艺制程制造,甚至可以是不同公司提供的。通过互联接口将它们相连接后,就形成一个 Chiplet 的芯片网络。
据壁仞科技研究院唐杉分析,Chiplet 历史更久且更准确的技术词汇应该是异构集成(Heterogeneous Integration)。总的来说,这个技术趋势是比较清晰明确的,而且第一阶段的 Chiplet 形态在技术上已经比较成熟,除了成本比较高,在很多高端芯片上已经使用。
比如,HBM 存储器成为 Chiplet 技术早期成功应用的典型代表。AMD 在 Zen2 架构芯片上使用了 chiplet 思路,CPU 用的是 7nm 工艺,I/0 则使用的是 14nm 工艺,与完全由 7nm 打造的芯片相比成本大约降低了 50%。英特尔也推出了基于 Chiplet 技术的 Agilex FPGA 家族产品。

异构集成示意动画,素材来自 IC 智库
不过,Chiplet 技术仍面临诸多挑战,最重要之一是互连接口标准。互连接口重要吗?如果是在大公司内部,比如英特尔或 AMD,有专用协议和封闭系统,在不同裸芯片间连接问题不大。但在不同公司和系统之间进行互连,同时保证高带宽、低延迟和每比特低功耗,互连接口就非常重要了。
2017 年,DARPA推出了 CHIPS 战略计划(通用异构集成和 IP 重用战略),试图打造一个开放的连接协议。但 DARPA 项目的一个短板是,侧重于国防相关项目,芯片数量不大,与真正的商用场景有差距。因此,芯片行业里一些公司成立了行业组织“ODSA(开放领域特定架构)工作组”,通过制定开放的互连接口,为 Chiplet 的发展扫清障碍。
另辟蹊径
除了在现有框架内做架构和制造上的创新,还有研究人员试图跳出计算机现行的冯·诺依曼架构,开发真正模拟人脑的计算模式。
在冯·诺依曼架构中,数据计算和存储是分开进行的。而内存存取速度往往严重滞后于处理器的计算速度,造成“内存墙”问题。并且,传统计算机需要通过总线,连续地在处理器和存储器之间进行刷新,这就导致芯片的大部分功耗都消耗在读写数据上,而不是算术逻辑单元,又衍生出“功耗墙”问题。人脑则没有“内存墙”和“功耗墙”问题,它对信息的处理和存储是一体的,计算和记忆可以同时进行。
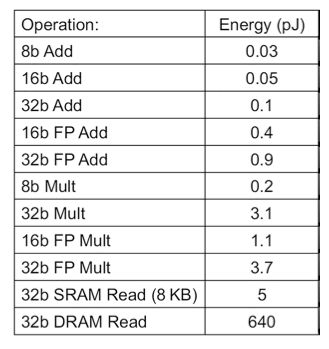
通用处理器中典型操作的能耗,图片来自《中国科学》杂志
另外一方面,当前推动 AI 发展的深度神经网络,虽然名字里有“神经网络”四个字,但实际上跟人脑神经网络的运作机制相差甚远。1000 亿个神经元,通过 100 万亿个突触并行连接,使得人脑能以非常低的功耗(约 20 瓦),进行同步记忆、演算、推理和计算。相比之下,当前的深度神经网络,不仅需要大规模数据进行训练,在运行时还消耗极大的能量。
因此,如何让 AI 像人脑一样工作,一直是学界和业界积极探索的课题。1980 年代后期,加州理工学院教授卡弗·米德(Carver Mead)提出了神经形态工程学的概念。经过多年发展,业界和学界对神经形态芯片的摸索逐渐成形。
软件方面,被称为第三代人工神经网络的“脉冲神经网络”(Spike Neural Network,简称 SNN)应运而生。这种网络以脉冲信号为载体,更接近人脑的运作方式。硬件方面,大型机构和公司研发相应的脉冲神经网络处理器。
事实上,早在 2008 年,DARPA 就发起了一个计划——神经形态自适应塑料可扩展电子系统(Systems of Neuromorphic Adaptive Plastic Scalable Electronics,简称 SyNAPSE,正好是“突触”之意),希望开发出低功耗的电子神经形态计算机。
IBM Research 成为了 SyNAPSE 项目的合作方之一。2014 年,他们发表论文展示了最新成果——TrueNorth。这个类脑计算芯片拥有 100 万个神经元,能以每秒 30 帧的速度输入 400 × 240 像素的视频,功耗仅 63 毫瓦,相比冯·诺依曼架构的计算机有质的飞跃。
英特尔在 2017 年展示了一款名为 Loihi 的神经形态芯片,包含超过 20 亿个晶体管、13 万个人工神经元和 1.3 亿个突触,比一般训练系统所需的通用计算效率高 1000 倍。2020 年 3 月,研究人员甚至在 Loihi 上实现了嗅觉识别。这一成果可应用于诊断疾病、检测武器和爆炸物以及及时发现麻醉剂、烟雾和一氧化碳气味等场景。
在中国本土,清华大学类脑计算研究中心的施路平教授团队,开发了一款面向人工通用智能的“天机”芯片,同时支持脉冲神经网络和深度神经网络。2019 年 8 月 1 日,天机成为中国第一款登上《Nature》杂志封面的芯片。
尽管已经有零星研究成果,但总的来说,脉冲神经网络和处理器仍是研究领域的一个方向,而没有在工业界大规模应用,主要是因为基础算法上还没有关键性的突破,达不到业界应用的精度,而且实现成本比较高。
相关推荐
软件吞噬硬件的AI时代,芯片跟不上算法进化可咋办?
苹果A系列芯片的三年AI进化:为何要大规模升级AI算力?
IoT坐标系下,下一个产生软件进化的硬件是什么?
4亿美元收购案失败的背后:错失AI芯片时代的最好3年
多模人车交互,智能汽车的AI感知进化
“AI芯片”通识:AI产品经理看这一篇就够了
特斯拉 AI 芯片的真正实力
对话深度学习奠基人特伦斯:AI的进化动力与终极限制
亚马逊的AI芯片出炉,会把全球芯片产业拖向何方?
A16Z合伙人:软件正在吞噬医疗保健服务
网址: 软件吞噬硬件的AI时代,芯片跟不上算法进化可咋办? http://www.xishuta.com/newsview38818.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95228
- 2人类唯一的出路:变成人工智能 21183
- 3报告:抖音海外版下载量突破1 21148
- 4移动办公如何高效?谷歌研究了 20339
- 5人类唯一的出路: 变成人工智 20338
- 62023年起,银行存取款迎来 10336
- 7五一来了,大数据杀熟又想来, 8596
- 8网传比亚迪一员工泄露华为机密 8505
- 9滴滴出行被投诉价格操纵,网约 8215
- 10顶风作案?金山WPS被指套娃 7230



