站在百亿亿次巅峰之前,Top500超算的过去、现在与未来
本文来自微信公众号“科技云报道”(ID:ITCloud-BD),作者:科技云报道,36氪经授权发布。
日前,ISC大会如期公布了2021上半年度的TOP500超算排行榜。
毫无意外,算力为445PFlops的日本理化学研究所富岳(Fugaku)超算继续蝉联榜首,而二三四名也与上届和上上届榜单一样,被橡树岭国家实验室的Summit(美国)、劳伦斯利弗莫尔国家实验室是的Sierra(美国)、国家超算中心无锡的神威太湖之光(中国)分别收入囊中。

作为2020年6月建成的新一代超算,富岳(Fugaku)的制造商为日本富士通,CPU为其自研的A64FX系列处理器。
CPU采用ARM架构设计,48核心,主频2.2GHz;整个超算包含158,976个单路节点,总计核心数量也达到了恐怖的7,603,848个。
不同于绝大多数超算所采用的集群架构设计,富岳(Fugaku)采用了MPP架构设计,整台超算以单一主机形态来执行并行任务。
显然,这样的设计对超大规模的单一任务有着更高的友好度,却也会给多任务并行带来管理方面的挑战。
由于MPP架构中的所有CPU和内存都在一个统一架构内,因此,对于MPP架构对互联架构的性能和效率都有着更高的要求。
为此,富士通也采用了专门研发的TofuInterconnect D技术来进行超算内部节点间的互联。
受疫情等因素的影响,全球绝大部分的顶级新建超算工程均出现了或多或少的延迟;这也使得原本计划在2020年底或本届TOP500榜单中出现的各国新一代百亿亿次超算推迟到了今年年底或更晚的榜单。
虽然大型超算的兴建工程大受影响,但“中小型”超算由于规模相对较小,因此进度影响相对有限。
本次TOP500共有48台新上榜超算,排名大多集中在50-250名左右。而在更令人关注的TOP10排名当中,新晋超算则只有来自HPE的Perlmutter一台。
受到这些新晋“中小型”超算的影响,本次TOP500榜单的合计算力达到2786.1PFlops,相对上一届的2428.8PFlops提升15%。
由于本届TOP500榜单的确“乏善可陈”,因此我们也将对比范围从一年扩大至5年。那么,下面就让我们来看看5年中,人类的顶尖算力发生了怎样的变化。
01 中想过去看今朝,图说Top500
01、国家对比
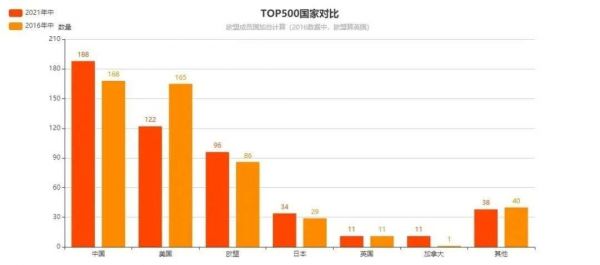
2016年中,中国超算数量首次超越美国,成为全球超算第一大国。5年后,中美在超算数量上的差距进一步增大,从5年前的3台扩大为目前的66台。
与此同时,欧盟和日本超算数量稳中有升。值得注意的是,即便不将英国计算在内,欧盟与美国的超算数量差距也在以肉眼可见的速度缩小。
不过,另一方面,我们也应该注意到,无论是5年前还是现在,在TOP10的顶级榜单中,美国都能占据4-6席,而中国则仅能保持1-2席。
这证明中国虽然能够在数量上超越美国,但在前沿领域,两国仍存在明显差距。
02、处理器品牌及架构对比
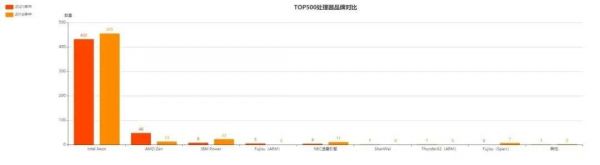
无论是5年前还是现在,IntelXeon系列处理器仍旧是超算构建最主流的选择。不过伴随近几代AMD Zen系列架构的强势发展,越来越多企业和机构也开始选择使用AMD EPYC霄龙系列产品。
这也使得AMD在TOP500中的份额从5年前的13台发展成为现在的48台,占比接近10%。
另外一个值得注意的趋势则是IBM Power系列处理器在超算领域中的衰落。虽然我们仍能再TOP10当中看到Summit、Sierra这样的顶级产品,但从23台到8台的占比也足以证明IBM和Power的式微。
预计,IBM Power系列产品仍将长期盘踞在TOP50这样的“高端”排行榜中,但在更看重性价比的50名开外,用户的确有着更具性价比的多种选择。
第三,5年间,ARM架构已经取代Sparc,在超算领域崭露头角。
目前,TOP500当中已经有5台采用Fujisu A64FX系列处理器的超算和一台采用ThunderX2系列处理器的产品;相比之下,Sparc架构已经在今年的TOP500榜单中彻底消失(让我们为Sun举杯,缅怀这位老友)。
值得一提的是,在中欧日的百亿亿次计划当中,都有ARM的身影。
03、架构对比
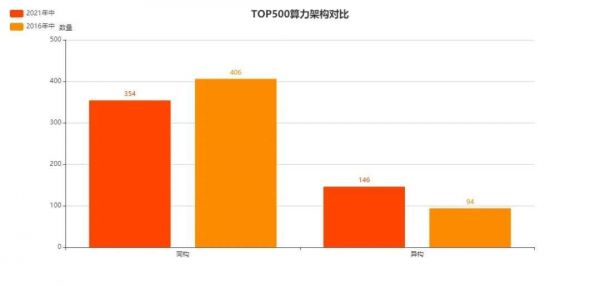
近几年,伴随AI等应用的强势崛起,异构算力成了最火爆的概念。
随之而来的便是NVIDIA暴涨的市值和以Intel为代表的各大半导体巨头纷纷杀入GPU(或协处理器)领域。
虽然在HPC领域,GPU的通用计算(GPGPU)的应用更早,但我们仍能发现,5年间,异构超算的数量从94台增长至146台。
而且,在更尖端的2021年中TOP50榜单中,异构超算的数量更是达到29台,占比接近60%。5年前,这一数量仅为14台,占比仅为28%。
当然,在所有加速器当中,NVIDIA仍旧是绝对的主流。但我们仍能偶尔看到国防科大Matrix-2000、NEC矢量引擎或曙光Deep Computing Processor这样的“异类”,而这让我们兴奋不已。
04、互联网络
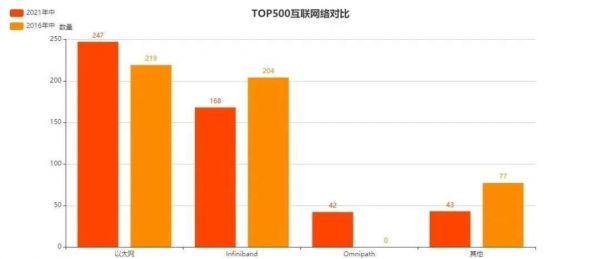
互联架构是超算的另一大组成部分,而从上图的对比中我们也能够发现,从商用网络中脱颖而出的以太网在5年间也取得了不小的进步。
在2021年中的榜单当中,使用以太网进行互联的超算数量已经达到247台,无限接近50%。与之相对应的则是Infiniband这种传统高性能网络和各类定制网络占比的降低。
造成这种现象的原因在于以太网性能的不断提升、价格不断降低;最新一代以太网交换机和网卡还包含了RDMA、智能网络编排等重要功能,这就使得以太网在于传统Infiniband的对比中更具吸引力。
出于同样的原因,各类定制型网络的占比也在持续降低。
一方面,在面对以太网时,定制型网络几无性价比可言;另一方面,定制型网络通常与特殊的超算架构相绑定,这也限制了其发展和用途。
未来,定制网络并不会消失,但也只会出现在高精尖科研或国防等注重自主和保密的狭窄领域内。
另一个值得注意的点便是OmniPath。这是英特尔在之前两代至强可扩展处理器当中新加入的特性。
由于将很多网络特性集成在了CPU内部,OmniPath能够为采用特定至强处理器的同构超算带来超高的处理器互联性能。
但由于需要采购特定的处理器型号、主板型号并搭配专用的交换机,OmniPath终究没能被更广泛的市场所接受。
而单靠超算用户显然也无法支撑庞大的各类产品研发和制造成本。所以Intel最终取消了OmniPath产品线,这也就使得目前榜单中使用该互联架构成为了这一技术的绝唱。伴随榜单的持续更新,OmniPath的名字在TOP500之中会逐渐消失。
05、超算架构对比
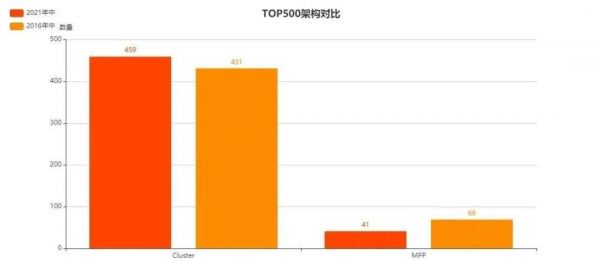
Cluster(集群)与MPP是当代超算常见的两种架构。在集群架构中,各个节点相对独立,任务在各类节点中相对独立的进行计算;而在MPP架构中,各个节点中的CPU和内存则紧密相连,作为一个整体来执行任务。
相比于应用更广泛的集群架构,MPP更易于执行那些对内存和计算资源有着超大规模需求的任务。
当然,在这种结构之下,超算对于互联架构有着更苛刻的带宽和延迟需求,这使得MPP大多只能使用定制网络进行互联。
而即便使用以太网,也只有CRAY的Slingshot-10这样的超高性能以太网才能一战。
另外,MPP架构也有自己天生的缺点——无法使用异构算力。
在2021年上榜的41台MPP架构超算中,除了排名第5的Perlmutter带有GPU结构之外,其余40台MPP架构超算均为同构超算。
当然,在Perlmutter当中,CPU仅作为任务调度和为节点提供GPU所需的PCI-E Lane通道之用,核心算力仍来自于其搭载的6159个NVIDIA A100 GPU。当然,能够在MPP架构上成熟实践这一操作的,目前来看,也只有HPE CRAY一家,别无分店。
在这些功能和架构限制之下,MPP架构超算占比逐渐降低也就顺理成章了。
06、制造商
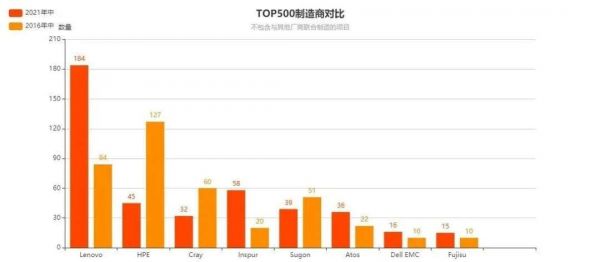
相对于商用市场,超算的市场规模并不大;但由于需要承接来自国家、科研机构和顶尖企业的需求,超算仍旧各大硬件制造商“不蒸馒头争口气”的顶尖竞技场。
由于收购了IBM的服务器制造业务,5年间,联想在TOP500超算市场的份额快速提升,从84台跃迁至184台,进步明显。提升第二明显的则是浪潮,5年间,TOP500上榜数量从20提升至58。
榜单中最大的输家当属HPE,TOP500上榜数量从127降至40。即便完成了对CRAY和SGI等传统超算专业品牌的收购,市场份额持续流失也是不争的事实。
TOP500榜单中超算制造商此消彼长的背后,既有中国品牌的不断砥砺前行的进取之心,也有国家科研和经济高速发展所带来的巨大红利;愿这一趋势能够长久保持。
07、关于百亿亿次
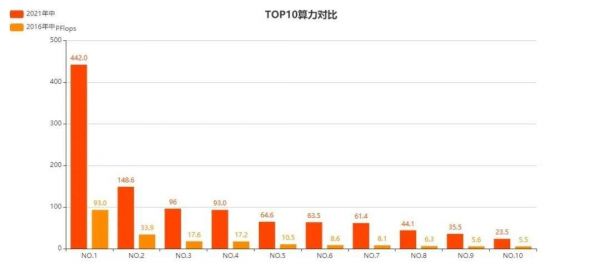
说明:2016榜单中算力33.9PFlops,排名第二的天河2号与2021榜单中算力33.5PFlops,排名第9的天河2A虽有血缘关系,但由于加速器从之前的Xeon Phi更换为Matrix 2000,因此,并不能认为他们是同一台超算。特此说明。
在5年跨度的两张TOP10榜单的对比中,我们可以看到4-5倍的算力增长,也能看到富岳超算的强劲实力。
而在百亿亿次算力即将出现的2021年终榜单中,第一梯队算力将与第二梯队产生更加明显的差距。
02 全球各大经济体百亿亿次超算计划对比
接下来让我们看看全球各大主要经济体的百亿亿次计划。
中国:
天河三号:将采用新一代飞腾系列处理器(ARM架构),并安装Matrix 2000+系列加速器(众核架构),预计将采用新一代TH Express-3互联架构。原型机已经完成部署。
神威E级:将采用于神威太湖之光上首次部署的申威SW26010处理器(260核,众核架构,预计仍采用DEC Alpha的派生指令集),但预计会在制造工艺上进行升级。神威E级将在处理器数量、加速器数量和节点数量上进行翻倍处理,至少达到8万个节点规模。原型机已经完成部署。
曙光E级:将采用x86架构的海光处理器(32核心)和曙光DeepComputing Processor,互联架构预计采用500Gb 6D Torus网络,原型机已经完成部署(原型机采用200Gb 6D Torus互联)。
美国:
Aurora:由Intel和HPE CRAY共同研发制造,用户为美国能源部阿贡实验室。新超算将包含Intel的全套产品,包括但不限于第三代至强可扩展处理器(IceLake架构,10nm工艺)、Xe系列加速卡、Optane内存以及OneAPI软件等等。系统将采用HPE CRAY的Shasta架构及管理软件,预计将使用Slingshot-10或后续产品作为互联架构。
Frontier:由AMD和HPE CRAY共同研发制造,用户同样为美国能源部。新超算预计将采用第三代AMDEPYC处理器和最新一代Radeon Instinct计算卡,算力将达到1.5exaFlops(150亿亿次),每节点采用1CPU+4GPU的结构,计算环境则为HPE CRAY的ROCm,互联架构也很有可能采用HPE CRAY 的Slingshot-10或后续产品。
El Capitan:由AMD和HPE CRAY共同研发制造,用户为美国能源部劳伦斯利弗莫尔实验室。计将采用第四代AMDEPYC处理器和最新一代Radeon Instinct计算卡,算力将达到2exaFlops(200亿亿次),预计2023年建成。
欧盟:
EPI项目:The EuropeanProcessor Initiative,由欧盟28个成员国共同出资,计划包含ARM和RISC-V两种架构的通用处理器。
采用ARM架构的RHEA SoC将包含72个ArmNeoverse Zeus内核,Mesh网格式布局,2.5D封装,集成HBM和网络互连模块,使用台积电6nm工艺制造。
采用RISC-V架构的EPAC1.0测试芯片目前已经流片,并计划于2021年Q4推出。计划中,每个处理器将包含四个VPU(矢量处理器)以及EXTOLL超高速片上网络和SerDes互连技术。芯片预计将采用Chiplets封装。
同时,由RISC-V架构多位创始人联合创办的SiFive公司也在竞标欧洲百亿亿次超算项目,其处理器产品同样采用RISC-V架构。
日本:
Post-K(后“京”):作为日本超算“京”的后续产品,Post-K将采用目前已经成功部署的富士通A64FX处理器。Post-K计算节点原型已经开发完成,I/O及计算节点有48个核心外加4个辅助核心。
系统结构每个节点使用1个CPU,采用水冷散热, 384个节点组成一个机架。按照这一结构,预计Post-K将会有更夸张、更庞大的节点数量和核心数量。
03 总结
作为一张榜单,2021年中的TOP500的确让人提不起兴趣,但2021与2016的两张榜单对比当中,我们也的确能够看到超算发展的各种趋势。
站在百亿亿次的大门之前,我们既对未来充满期待,也应该为那些致力于挑战人类算力巅峰的科学家和工程师们鼓掌加油。
面对无尽的未知,算力就是照亮前路的聚光灯。
相关推荐
站在百亿亿次巅峰之前,Top500超算的过去、现在与未来
全球超算Top500排行榜:日本蝉联冠军,中国排第几?
全球超算Top500发榜,日本「富岳」蝉联冠军,中美两国持续霸榜
超算芯片霸主之争,终于有了新变数
一夜之间,世界最强超算易主
“天河”E级验证系统摘得图计算领域两项桂冠
全球最快AI超算Perlmutter问世,将绘制宇宙最大3D地图
小米的过去、现在和未来
全球Top 500超算榜单更新:Summit仍居榜首,中国上榜227台,总算力占比31.9%
揭秘特斯拉自动驾驶超算Dojo原型,全球排名可进前五
网址: 站在百亿亿次巅峰之前,Top500超算的过去、现在与未来 http://www.xishuta.com/newsview46491.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 94963
- 2人类唯一的出路:变成人工智能 19337
- 3报告:抖音海外版下载量突破1 19054
- 4移动办公如何高效?谷歌研究了 18573
- 5人类唯一的出路: 变成人工智 18435
- 62023年起,银行存取款迎来 10137
- 7网传比亚迪一员工泄露华为机密 8198
- 8顶风作案?金山WPS被指套娃 7105
- 9大数据杀熟往返套票比单程购买 7050
- 10五一来了,大数据杀熟又想来, 6947



