12万词名著175词讲完,AI比我会抓重点
读完一本书后对故事内容进行总结概述,这件事情对于一个人类来讲并不是能不假思索完成的。现在,机器学习模型可以了。
近日,美国著名人工智能非营利组织OpenAI公布了一项新成果——由GPT-3微调而来能总结梗概书籍内容的算法模型,它不仅可以对每本书的各个章节进行概述,还能够进行更高层次的总结。
用机器学习来写作体育比赛、地震、财经新闻等类别的文字摘要已经较为常见,此前,学术出版商Springer Nature也借助机器学习对锂离子电池领域的数百篇研究论文做了综述,使读者根据摘要去有选择地阅读全文。
不过,本次OpenAI首次将其在去年6月推出的大型语言模型GPT-3进行应用,开发出能对文学名著等图书进行总结概述的算法模型。
据称,该进展是团队第一次关于梗概对齐技术(scaling alignment techniques.)的大型实证工作。这里提到的对齐技术,简单来说就是找到能够对人一般智能进行对齐的技术,这一类研究目前是机器学习研究的一大挑战。

▲论文链接:https://arxiv.org/abs/2109.10862
01 AI读名著:将12万词小说提炼出175词摘要
我们来看看OpenAI团队的成果,模型能对图书内容进行怎样的梗概?
以很多人看过的《爱丽丝梦游仙境》为例,这本书共十二个章节,近26,449词。在AI更改后变成以下136词英文摘要,也就是差不多一条微博文字的长度,大家感受一下:

可以看到,AI在事件概述上抓住了主要人物、事件和时间顺序,但同时也显得有些流水账、缺起承转合,很像一个小学生回家后被要求给爸爸妈妈复述课本上内容的反应。
看完童话故事,再看看更有难度的著名剧作家莎士比亚的名著《罗密欧与朱丽叶》,“读”完这本书后,AI写下119词摘要:

如果说梗概简单的童话故事AI尚能胜任,那么理解成人的爱情故事对它来说就显得有些吃力。它确实把主角罗密欧与朱丽叶前后的相遇、相爱、分别、死亡点到了,却让人感到旷世的爱情悲剧好像被讲成一场碎片拼贴起来的drama悬疑剧,让读者找不到矛盾的核心,更不用提被爱情感动。不过,仅从叙事梗概这个层次来说,机器做得还是比较准确的。
看完AI对短篇文学作品的梗概,我们再来看看中长篇,比如简·奥斯汀12万词的《傲慢与偏见》,摘要是这样的:

中文译文参考如下:

这一小说主要讲述了乡绅之女伊丽莎白·贝内特和富有的达西先生,以及他们的亲友简和宾格利的爱情故事,反映了19世纪英国乡绅阶层的礼节、成长、教育、道德、婚姻的情态。可以看到机器还是抓住了几个主角的爱情故事的主旋律,逻辑基本没有问题。不过不足之处和前面也十分类似,机械化、堆砌、缺乏多层次抽象。
不过,对于这项需要从海量的人物、动作、心理、环境等描写和复杂的时间线、场景转换中总结出主角、主要事件的任务来说,OpenAI的这项模型已经表现不错。据团队称,其输出结果在BookSum数据集、“叙事QA”数据集上都实现了最先进的结果,这表明尽管你觉得这一模型表现跟人类差远了,但这已是世界先进水平。
对此,团队在论文中也承认,用研究模型生成的这些摘要包含了书中重要的事件,有时还对多出细节进行了抽象化地归纳总结;然而,他们经常遗漏重要的细节或无法掌握更广泛的上下文内容。
02 先把小说分成66部分梗概,再总结为6段
要做到整本书的梗概,OpenAI团队首先的工作是让模型从总结篇幅更小的段落文字开始。
以往,大型训练模型并不善于总结文本。此前,团队发现从人类反馈中训练强化学习模型,有助于使模型变得善解人意。简单说,就是由人来判断模型输出结果,以帮助模型进化,从而理解短帖和文章中人的情感和表达的含义。当任务扩展到整本书,摘要工作对模型来说变得更难。
为了解决这一问题,团队采用递归任务分解法,简单来说,就是在程序上将一项艰巨的任务分解为较容易的任务。在这个任务中,就是将长文章被分解为多个小节进行处理。
以《爱丽丝梦游仙境》为例,团队首先让模型将全文66小节共长达6024词的内容分节梗概,如下图所示:

▲66节中的第一节梗概内容
然后将这66节梗概再缩写,转化成6小节一共830词的梗概,可以看到,内容逐渐变得更精简抽象。

▲6节中的第一节梗概内容
直到最后,一段136词的梗概才呈现出来。这一梗概生成的过程可以从以下模式图中展现,该方法可用于对任意长度的书进行总结,实现了在数十万字的书籍上递归到3层深度的内容总结。
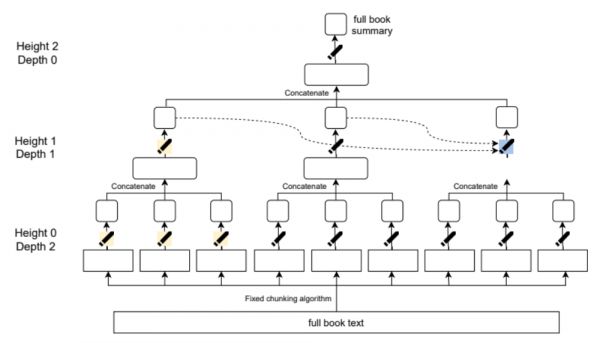
团队指出,相对于端到端的训练过程,递归任务分解具有以下优点:
1、允许参考书籍内容的一小部分摘要来更快地评估模型,而不是阅读原文。
2、跟踪摘要的编写过程更容易。例如,可以查找摘要中的某些事件在原文中发生的位置。
3、这一方法可用于总结无限制长度的书籍,不受使用的转换模型上下文长度的限制。
团队在论文中称:“当定量评估时,我们的模型显著优于我们的行为克隆基线,并且,少量的总结接近人类水平的质量。”
03 GPT-3发布一年多以来,展现出对齐人类智能的潜力
OpenAI本次发布的模型只聚焦一个细分领域的应用,但这一模型是由GPT-3微调而来,代表着GPT-3模型的最新应用进展。GPT-3的全称叫生成预训练转换器-3(Generative Pretrained Transformer-3),是OpenAI于2020年6月推出的大型语言模型,诞生的使命是使用深度学习分类或产生人类可以理解的自然语言。
今年3月,OpenAI宣布,GPT-3现已被数万开发者用于300多个不同的应用程序,应用包括创作小说、编写潦草的代码,以及让用户对话历史人物等,每天输出45亿词之多。
任何公司都可以申请使用GPT-3的通用API,而获得OpenAI授权商用GPT-3底层代码的目前只有微软。今年5月,GPT-3被加入到Power Apps使用的低代码编程语言Power Fx中。
本次,对基于GPT-3开发的书籍内容梗概模型,OpenAI在博客中写道:“这项工作是我们正在进行的调整先进人工智能系统的研究的一部分,这是我们任务的关键。当训练模型去做越来越复杂的任务时,对模型的输出进行明智的评估对人类来说将变得越来越困难。”
“我们目前解决这个问题的方法是,让人类能够利用其他模型的帮助来评估机器学习模型的输出。”
展望未来,团队正在研究更好的方法来帮助人类评估模型行为,目标是找到能够对人一般智能进行对齐的技术。“希望我们的工作能够鼓励更多的研究,使用训练过的模型来帮助人类完成更简单的任务,为更困难的任务提供训练指引。”
04 结语:让算法对齐人类智能,仍有很远的路
OpenAI的新成果让我们看到,基于GPT-3等语言模型,机器正在实现阅读理解、抽象写作等更加需要思考的复杂任务,让人看到其向认知智能靠近的潜力。
与此同时,算法的能力依然十分有限,更多是像一个剪刀手剪辑出来片段的组合,虽然看起来也能模仿人类的抽象思维,但难以把部分和总体联系起来结合上下文去理解事件背后的深层含义。
让人工智能更具有认知智能,从而理解人类博大精深的语言下的深层思想情感和隐含意义,这仍然距今有很长的路要走。
本文来自微信公众号 “智东西”(ID:zhidxcom),作者:李水青,编辑:心缘 ,36氪经授权发布。
相关推荐
12万词名著175词讲完,AI比我会抓重点
百度沸点2019年度科技热词:AI、5G、区块链位居前三
最前线 | 三个词,盘点互联网大佬们的两会提案
年度互联网热词你GET到了吗?
2020 年,手机行业还会出现哪些“热词”?
沃尔玛的防盗AI,只抓好人,抓不到贼
不用唤醒词就能激活,谷歌助手又要放大招
网络热词“干饭人”被注册成餐饮公司
《大宋宫词》:一部大IP古装剧四年踩雷全史
关于政府工作报告的5个热词,董明珠雷军等有啥看法
网址: 12万词名著175词讲完,AI比我会抓重点 http://www.xishuta.com/newsview51096.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95228
- 2人类唯一的出路:变成人工智能 21183
- 3报告:抖音海外版下载量突破1 21148
- 4移动办公如何高效?谷歌研究了 20339
- 5人类唯一的出路: 变成人工智 20338
- 62023年起,银行存取款迎来 10336
- 7五一来了,大数据杀熟又想来, 8596
- 8网传比亚迪一员工泄露华为机密 8505
- 9滴滴出行被投诉价格操纵,网约 8215
- 10顶风作案?金山WPS被指套娃 7230



