顶级AI学者邢波教授:机器学习缺乏清晰理论与工程框架,需重新思考评估方法及目标
2021年1月,全球计算机科学和人工智能领域顶级学者邢波教授(Eric P. Xing)正式出任全球首个人工智能大学 MBZUAI 的创始校长。日前他接受了机器之心的专访。在超过4个小时的访谈中,邢波教授分享了他的治学和治校之道。考虑到篇幅,我们将采访整理分为上下两篇发布。
上篇也即下文是他对机器学习和人工智能领域现状及学科发展的看法;下篇则是作为 MBZUAI 正式创始校长,邢波教授对学术管理及领导力,对研究品味,以及对探索创造新的、更加符合当前时代的 AI 科研和教育环境的思考。
近年来人工智能高速发展,却不想领域内重商主义气息愈加浓厚,随着企业和高校在设备、人才乃至研究话语权之间展开竞争,AI 的科研和教学越发受市场和资本所左右。
成为一名「教授」所能获得的回报和荣誉感,以及自由探索的空间,都大不如前。研究人员面临着一种困惑,是索性顺应这个时代的潮流去当学术网红,还是靠灌水、刷榜成为所谓的高产学者,因为在越来越多的情况下,囿于资源、制度等因素,静下心来钻研真正有价值的问题,似乎已经成为一种奢侈。
「在如今学校的科研环境里,很多学者都有一些挫折感,学生也比较迷茫,我想这一点大家是很清楚的。」2021年3月,卡内基梅隆大学(CMU)计算机科学学院教授,刚出任 MBZUAI 正式校长不久的邢波教授(Eric P. Xing)在接受机器之心专访时说。
MBZUAI 全称默罕默德·本·扎耶德人工智能大学(Mohammad Bin Zayed University of Artificial Intelligence),2019 年底在阿联酋阿布扎比成立,是全球第一所专注于人工智能的大学,仅提供研究生课程,强调研究型机构特征,最初由图像分析领域先驱、1985 年在牛津大学创立机器人研究小组(现今 Oxford Robotics Institute 前身)的 J. Michael Brady 爵士任临时校长。
被任命为 MBZUAI 正式校长时,邢波教授表示 MBZUAI 致力于在人工智能的教育和研究中追求卓越,他希望在这个新的平台上培养出具有基本 AI 素养的新一代领导力人才,能够通过学术研究和产业应用充分发挥人工智能的潜力,同时让 MBZUAI 成为阿联酋经济和社会发展的一股积极影响力。
作为全球计算机科学和人工智能领域的顶级学者,同时也是深谙 AI 实际应用的杰出商业领袖,邢波教授非常了解自己面临的考验。出任 MBZUAI 的正式创始校长,是他给自己定下的一个目标,希望通过这个从零开始的机会,探索创造一种新的、更加适应当代要求的科研教育和技术转化环境,并通过这个环境,对 AI 发展做出应有的贡献。
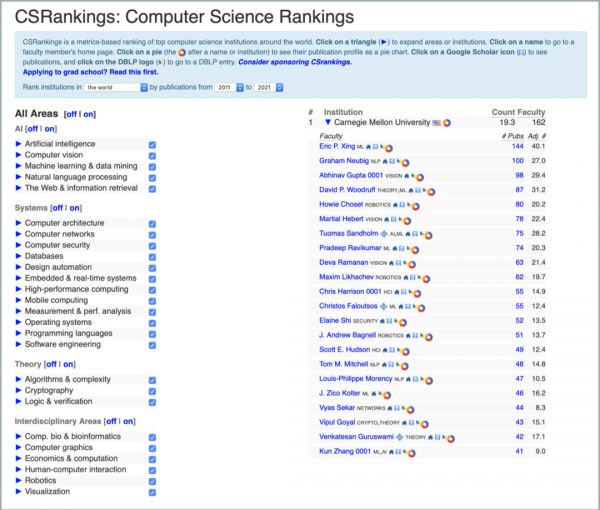
根据计算机科学领域的权威排名 CS Rankings,从 2011 年到 2021 年,在包括人工智能、机器学习、系统、理论、交叉领域等全方位计算机科学研究中,CMU 是全球范围内产出高质量研究最多的机构,而邢波教授是 CMU 里产出高质量研究最多的学者。来源:csrankings.org
1993 年,邢波教授从清华大学物理系毕业,随后进入罗格斯大学攻读分子生物学和生物化学博士学位。1999 年博士毕业后,他进入加州大学伯克利分校,继续攻读计算机科学博士学位,师从图灵奖得主 Richard Karp,以及更为如今 AI 界所熟悉的 Michael I. Jordan 和 Stuart Russell。
2004 年,拥有双博士学位的邢波教授加入 CMU 的计算机科学学院,在这一世界领先的计算机科学研究和教学环境中潜研至今,从助理教授开始,到 2011 年取得终身教职,再到 2014 年获得教授头衔。2015 年起,他开始肩任较为重要的学术管理职责,包括出任 CMU 与匹兹堡大学医学中心联合成立的「机器学习与健康中心」(Center for Machine Learning and Health)的创始主任,并从 2016 年 7 月起升任 CMU 计算机科学学院机器学习系的研究部副主任。
同样在 2016 年,邢波教授还创办了 Petuum,这是一家致力于提供人工智能和机器学习基础工程框架的公司,基于他以前在参数服务器方面的开创性成果,公司的愿景是希望 AI 和机器学习解决方案像乐高积木一样,是模块化、可拆解、能够自由组合搭配使用的。Petuum 于同年和次年连续两年入选 CB Insights 全球 AI 创企百强榜单「AI 100」,2018 年入选达沃斯经济论坛「技术先锋」。
像所有崇尚数理美感、追寻「万物皆数」的科学家那样,邢波教授认为人工智能也应该是需要去理解的,正如这个物理世界的规律可以用数学的语言去表达。从 2019 年开始,他便带领团队从损失函数的角度入手,尝试发现不同机器学习算法和模型间的共性,试图构建一个从形式化角度统一理解机器学习的理论框架,为今后人工智能的可工程化铺垫。
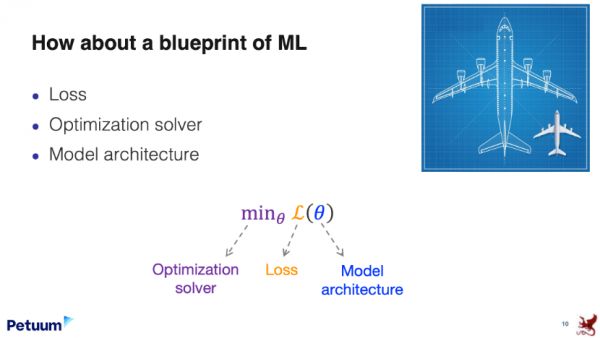
邢波教授团队从损失、优化求解器和模型架构等方面入手,为基于经验和任务的机器学习方法提供了一个统一的数学公式(standard equation)。他们发现,监督学习和无监督学习可以在数学上有着类似或相同的表达。 来源: Eric Xing & Zhiting Hu, A Blueprint of Standardized and Composable Machine Learning, Petuum & Carnegie Mellon, 2020.
与传统将「科学」和「工程」置于天平的两端去比较不同,邢波教授认为工程是承继科学之后的一个发展阶段。他指出调参或试错不是「工程」,AI 领域里真正工程化的工作还没有展开。
在下文的采访整理中,邢波教授分享了更多他对机器学习和人工智能领域现状及学科发展的思考。
一、看机器学习领域现状:缺乏理论和工程上清晰的框架
机器之心:我看了您近期的一些视频演讲,您提出了一个standard equation,想要统一所有的机器学习范式或模型,并且让它们像乐高积木那样可组合。这源自您对机器学习发展怎样的理解?提出这样的统一的表达公式之后可以为领域带来怎样的启发?
邢波教授:这的确是一个非常关键的问题,也是一个很难的问题。我们在做这项工作的时候,并不是为了统一而统一,实际上是很自然地演变进入到了这么一个阶段。机器学习和人工智能过去这十几年的飞速发展,产生了很多大大小小的结果,但是它们基本上都是停留在一个学术探索、试错、积累的状态,还没有形成一个完备的体系;甚至还没有归纳出严格的形式规范、理论基础和评估方法;没有涌现像物理、数学里面类似哥廷根学派、哥本哈根学派那种立足于某种核心理论,方法论,思考逻辑,甚至科研风格的school of thoughts。所以目前的多数成果对于工程落地和实现愿景并不是非常明确。但是人工智能又被公众和社会赋予了极大的期待,希望能够尽快地落地。
这就形成了目前这样纷乱的拓展局面,包括各种结果之间是否兼容,是不是能够组合,是否有重复,是否有冗余。这些问题都没有来得及回答。
在以前的研究里,我个人的兴趣会期待有一种比较清晰、简洁、实用,理论上具备严格逻辑且完整叙事的解决方式。
因此我对目前整个领域的这种比较混乱的发展局面是有一些关切,或者说甚至是有一些保留的。所以我觉得需要有一个工作去把它们整理一下,看看到底是怎么回事。
然后在工程上对此也有客观的需要。很多人尤其是科学家圈子,对于工程的理解其实有一些偏颇之处。诸多研究生、教授对于工程这方面的工作实际上是持鄙夷或者是轻视、藐视的态度。自认为我是科学家,那是工程问题。他们把编程、调参、系统优化、hack或者是试错的方法,甚至标准化、模块化的工作都认为是工程,所以他们会有一些居高临下、不屑一顾,以致鄙弃的看法。
但是我对工程的理解实际上是不太一样的。我认为如果要把一个学科升级到「可工程化」阶段的话,实际上代表了这个学科的成熟——工程是高于科学的。只有把科学原理搞清晰,解决了重复性、标准化这些问题之后,我们才能开始真正的工程。我觉得公众对于工程化、落地化的需求,人工智能科学尚未满足,科学方面还需要再走一步,来做标准化和统一的工作。
比如说土木工程、化学工程,或者生物工程,你会发现它们实际上是出现在力学、化学或者生物学之后的,而不是先有了这些工程,再有这些科学。
而在人工智能里面,我觉得大家没有理解这个顺序,把工程鄙视成调参或者试错,而把科学升得过高了,以至于所谓「科学」走得太快,没有停下来做一些整理或者吸收。所以我觉得 AI 领域里,工程化工作其实还没有真正的展开。
这次胡志挺博士和我做的有关 standard equation(标准方程)的工作,是希望把已有的 AI 工作进行整理,为以后可能的工程化来铺路。工程化就体现了刚才我们讲的可组合、乐高式的拼接。你会发现这个是目的,但是达到这个目的手段就已经涵盖了对于标准化、安全性,对于可解释性和数学简洁性的要求。
综上所述,我们这个工作不是为了统一而统一,是到了一个很自然的节点,有这样实质性的需要,况且目前也积累了这么多素材,我们就恰好处在这么一个很好的时机来做这项工作。
概括来说,标准方程就是用一个普适通用的公式来表达各种机器学习范式,比如传统的最大似然监督学习和无监督学习,贝叶斯学习,还有增强学习(Reinforcement Learning),主动学习(Active Learning),对抗生成学习等等。它们目前都有自己的狭义甚至专有的数学形式和计算方法,在每个局域里每年又都有大量的成果发表出来,形成了一个极其庞大的算法「野生公园」,每年新增的「新算法」不下上千。通常我们定义或者开发一个学习范式,需要从三个方面给出方案:目标方程、模型架构、算法。通常目标方程为主,定义了范式的基本数学本质;其他为从属,给出了具体的特征化手段和计算手段。目前大量的成果集中在比如模型架构,包括各种深度模型结构,概率图模型,核函数等等;以及各种算法,包括各种梯度的衍生物,蒙特卡罗,优化加随机的朗之万方法,等等。
我们提出的机器学习标准方程包含三个项:experience function(经验函数),divergence function(距离函数),uncertainty function(不确定性函数)。我们发现,对每一项的函数选取特别的实例化(instantiation),可以还原几乎所有已知机器学习范式。给定 standard equation 实例,则任意模型架构,算法,可以自由调用。
我们在机器学习标准方程上的工作,现在还仅限于对目标方程来做统一的处理。今后不排除提出通用的算法(所谓的 master algorithm,万能钥匙算法),以及通用模型(比如像 BERT 这样的所谓 all-purpose model,全能模型)。
目标方程是指在训练一个机器学习模型的时候,需要对模型好与坏做出判断,而且能够对于方程进行有目的的优化。另外,对于我们训练模型所使用的各种信息原材料,需要一个赛道来引入。这就是我们所说的从「所有经验」中学习:learning from all experiences。
简单举例:通常我们在训练一个人的时候,一种方式是用范例,给他看 1000 张图片,或者把英语各种词给他说几百遍,或者是让他见到无数多的样本,这是一种方法。但是,在人的学习里还可以通过很多其他的 experiences,比如我可以直接告诉你规则: 与其告诉你 1+1=2,2+2=4,… ,我可以告诉你 x+x=2x。这就是一个规则。
我们还可以直接总结或者提取规则:比如看高斯在做加法的时候,大家都说高斯很天才,他9岁的时候就发明了等差数列求和方法,计算从 1 到 100 这 100 个整数之和,他是把 1+100,2+99 得到 101,然后再乘以 50。这就是一种规律,而不是说把数字全加起来。这是一种学习方式,着眼于规则,而不是基本数据 (raw data)。
还有让人去做实验或体验,比如游泳,学习手脚怎样姿势,但是靠看教科书上的理论是无法学会的,必须要跳到水里去亲自游,体验这个姿势能不能让身体浮起来,能不能游动。这又是一种方式,思路上接近于增强学习(Reinforcement Learning),强调系统和环境的互动、探索、反馈。
还有模仿学习(Imitation Learning)。比如学钢琴,也许有人可以告诉你按键要用 50 克的力道,然后照着某一个音符来弹,这是一种最极端的规则式教法。也可以设想有老师会把同一音符或者乐曲用各种速度、音色、力量弹几百遍给学生作为训练数据集,实现所谓「监督学习」。甚至可以设想老师只提供你乐谱,或者没有乐谱而只放一遍音乐,然后放手让学生自己模仿甚至发挥,实现所谓「无监督学习」。听起来都很不可思议,不太靠谱?还有一种大师班里的教法,大师说你在边上观摩,我给你弹一段,他就直接弹奏一段,然后说你跟着学。在学的时候这就是 imitation,让你去模仿,但并不是用可监督或无监督的学习,实际上是一种新的模式。
还有一种类似现在的对抗生成式,一种挑战性的博弈式的训练学习,让你来生成一个例子,然后来看看你的例子能不能把我给「欺骗」住。这些都是学习的方式。
在目前的机器学习里面,对每一种方式都采用了自有的一套 paradigm,有时也被泛称作「算法」,但实际上包括了建模、定目标方程、最后的优化算法,这些都是不一样的。所以可以想象,方法论繁杂众多。每一个不同的经验、每一种不同的数据、每一个不同的训练信息来源,都是使用不同方法来获取的。
我们在做标准方程的时候,试图把这些不同的方法都统一到一个赛道里面,或者是用一套方程来写。这样至少首先让大家搞清楚我在做什么,也许我做的两个东西,把它写成方程以后,就是同样东西,它们也许没那么不同。
所以说了解整个训练过程本身,就已经相当有实际意义。
比如说 maximum likelihood learning(最大似然法),或者 Bayesian learning(贝叶斯训练),或者是 reinforcement learning(增强学习),它们实际上有类似或者完全统一的数学形式,甚至可以共享很多过去专用的高效优化算法,例如 policy gradient 和它的更强的衍生算法。
原来为了某一个训练的平台发明的算法,实际上可以用到另一个地方,它可以使优化算法的使用性拓宽,能够通用,这也是另外一个好处,能够提供这种组合的便利。因为有时候你可以把不同的经验合并在一起,而不用重新发明一个新的数据平台来做这样的统一。
就像人是用同一个大脑来学所有东西的。不是像在大学里一定要分科,有些人非要学文,有些人非要学理,然后学不同的方法还要细分。同一个人,既可以文也可以理,也可以学不同的东西。这实际上是我们希望在机器学习里能够带来的结果。
总之,在一个实用性的目标之下,把已有的成果和经验做一个梳理,最后用精确扼要的表达来涵盖我们目前的结果,有效简化以后的学习和实现,同时便于进行更通用的理论分析。这是对我们的机器学习标准方程工作的一个基本概括。
我在我的讲演里面用了一个例子,讲到了19世纪时物理学的状况。那时候电学、磁学、光学、力学都是分开的,大家认为它们是不同的领域,有很多看上去很不相关的工作被做出来了,形成了很庞大的一套结果。这对于学生来说,学会这几门学科已经要花很多时间,要看出规律、进一步往前推进就更难了。其实这是灾难性的。
但麦克斯韦把电磁统一了以后,就导致了对于这两种看似不同的自然现象的互为因果对称转化的理解和应用(比如通过磁转子来发电),甚至后来的对于光的波粒二象性的物理本质的理解,以及对于量子力学和电磁学的统一框架提供了思想上的启发,然后就发现物理衡量,比如光的常数——光速、普朗克常数、……,这些东西通过一套统一的理论话语,会看到里面缺什么,就会认识得更清楚了。它实际上更能够推动创新。
电磁统一过后,后来经过了杨振宁和米尔斯的规范场,现在物理里面从电到磁到弱力到强力,这四个都已经统一了,剩下只有引力没有统一。
这种统一一方面包含了自然哲学之美,另一方面也使很多东西有了应用和通用的可能。比如在电磁学统一了以后,人们对电磁的交互就产生了更深刻的理解,以至于后来制造出发电机、电力时代的产生,当时科学上的前瞻是起了很大作用的。
我们也希望在 AI 里面形成这样一个理论上更清晰的框架,能够使以后的创新站在更好的基础上,也使落地工作有一个更好的工程框架,让新的工作能够有更好的方向性。
机器之心:我可以这么理解吗,您认为 AI 或者说至少机器学习领域是存在这样一个统一框架的?
邢波教授:这个我觉得还不太好说。首先本质上什么叫做「统一」这个问题就有待讨论,这个词本身有模糊性。我倒不觉得统一就一定意味着用一个公式把所有的成果全都包含。我只是认为有必要把本来应该是同样原则的东西(但其表象不一样)溯本求源地发现出来,解释清楚。
不是为了统一而统一,而是把这些原本的统一或者原本的一致性的东西讲清楚。比如说引力和电磁力到底是不是相同其实还不太清楚。也许它们是不同的,也许它们是相同的,需要给出个回答。所以我没法预期它的最终形态,但是我觉得这个工作本身是有必要的。
机器之心:基于您现在的标准方程,您认为很多机器学习方式本质上是一样的,不管它是呈现出增强学习或者深度学习、对抗生成学习等形式,可以这么说吗?
邢波教授:这个问题难以用是与不是来简单回答。因为我不能保证断定它们是一样的。
机器之心:您刚才提到,很多东西看起来是很多不同的结果,实际上是一样的,我们现在就来提炼出本质。
邢波教授:这个问题比较复杂,所谓「一样」是有不同的定义的。一种是形式(symbolic)上的一样,另一种是物理(physical)上的一样,另一种是工程实现(realization/implementation)上的一样。这几个一样实际上是在不同层面上的。
现在 standard equation 只是提供了形式上的一样,但它是不是在物理上是一回事,我们还没有试图回答这个问题。比如,在标准方程第一项——经验函数(experience function)中,我们既可以嵌入数据经验(data experience),也可以嵌入来自和环境交互的回报经验(reward experience)。前者等同于最大似然学习,后者等同于增强学习。但是,这两种学习在标准公式中形式上的一致,并不代表它们学习的是同一种东西。前者是静态的模型下的隐变量和模型参数;后者是一种叫做策略(policy)的东西,是系统态(state,一种隐变量)和动作(action,通常是可测变量)之间的映射方程(mapping function)。所以这两种对于 standard equation 的实例化(instantiate),对应了物理内容上两种不同的学习。可以说它们的公式看上去是一样的,就像自然语言的算法和计算机视觉的算法,它们的数学公式可以一样,但它们显然是不同的。
这就表示两件事在形式上有一致性,但它们实质上的物理内容是不一样的。所以还是得看使用场景和具体的问题。但这种形式的一致性,可以给予研究者更大的想象空间和操作空间:比如可以把「数据经验」和「回报经验」相加,甚至加入更多的经验(比如对抗经验),那最终训练出来的系统是什么呢?它的理论特征为何?不同经验之间相对影响怎样?能否非线性组合?用什么算法来训练?……这些都是我们希望标准方程能引发的新的研究课题,非常有趣。
还有一个更大的空间,我还没有深入地研究:通常机器学习里包括目标方程、优化算法(就是用数学工具来做优化),还有一个是模型本身。模型在数学里面用 p 代替,或者用 f 代替,但这里面包罗万象。整个深度学习革命的工作一大部分都是建立在模型里面做创新,比如把它从一层变成 100 层,然后把里边的结构做不同的细化。
像现在的 co-attention model、transformer、LSTM 这几个大型的深度学习模型,其实都是在模型空间里面做创新。而生成对抗模型(GAN model)是另一个层面,是在目标方程里面做创新。
我讲课的时候会把这些东西梳理一下,让大家知道创新点在何处。但是现在在我们大众或者甚至是在某一个层面社区内对这个意义,都是混在一起。
所以我现在的工作目标之一就是把这些梳理清楚,让大家知道创新的方向在何处,或者我们现在的结果该如何评估、处置。
算法里面当然有各种各样的创新,刚才我们讲到的梯度就是最大的一个算法。Back propagation 实际上就是梯度里的一个特例而已,EM 也是梯度里的一个特例。
除了梯度以外,还有另外的算法。比如遗传算法就不是梯度算法,蒙特卡罗也不是。我们有时候会说 zero order(零阶)或者 first order(一阶)、second order(二阶),其实已经把算法层面上的大致方向做了一个概括。但是这个空间里面也有很多工作可以做。比如我们最近的一项工作叫做 black-box optimization,黑箱优化,用来支持 Learning to Learn,属于元学习(Meta-Learning)中的一项任务。因为优化的对象本身就是一个机器学习算法或者模型结构,而不是具体的形式化好的方程里的参数,无法求导,而只能采用试运行(Query),每一次都很昂贵(试想每一次都相当于在特定超参数设置下训练一遍 BERT),如何用最少的试运行找到最好的超参数获得最快训练速度和最佳训练结果?这些都是很有趣的问题。在标准模型框架下,这样的研究会有更好的理论和应用潜力。
在标准模型下,所有以上工作都会直接获得通用性,兼容性,真正做到举一反三:为增强学习设计的算法可以直接用到普通的最大似然学习,达到数据强化(data augmentation)的效果;为序列数据(sequential data)设计的深度模型可以用来表达policy;对于监督学习所做的边界鲁棒性分析也许可以覆盖其他学习范式。
我觉得现在很多创新缺乏精准的定位。任何一个具体工作都是多维的,如上所述的目标方程、模型、算法;目标方程里包括经验函数、距离函数、不确定性函数;其中经验函数里可以包括数据、规则、回报等等,而距离函数可以包含 KL-divergence,JS-divergence,cross-entropy,等等。通常在做创新的时候,或者是在定义创新、评估创新或结果的时候,是需要把那些不变维设成常数,然后拿创新维做变量,再评估结果,然后再轮换。但是如果一口气把目标方程换了,把模型也换了,把算法也换了,最后得到新结果,其实是很难让自己或者别人复制或解释到底是哪方面的创新达成了你的最佳结果。
这也是为什么升级工程产品的时候,比如说造一架飞机,通常如果要测试引擎的力道,会把其他的东西都固定,比如飞机的载重或者是造型、流体动力学都是固定的。然后通过引擎的调整或者升级,能够看结果是多少。
但要考虑更新机翼的话,如果其他方面不能使用常量,一口气把飞机从形状到动力到材料全换了,最后总结这架飞机更好。但到底是哪里好?为什么好?这是搞不清楚的。我希望能够进一步提倡这种比较严密的研究思路。虽然可能会减缓创新的速度,但是成果可能更容易积累或者更容易被消化。
二、看机器学习评估方法及目标:Leaderboard 缺陷在哪?
机器之心:您认为衡量机器学习算法或者模型的优劣,就是应该准确地定位创新点具体在哪里,可以这么理解吗?您曾经提到过,业界现在被非实际性能还有排行榜迷花了眼,大家都比较专注于那样的提高。您也在尝试一种新的方法来评估机器学习模型,您能不能就此展开一下:除了您刚才说的具体知道哪方面有所创新,还有如果我们不看性能,不看精确度,不看这些,当然也会考虑到计算消耗的能量,那我们看什么呢?
邢波教授:这个问题问得挺好的。刚才我讲的所谓「固定两点来看第三点的影响」实际上是评估方法,不是评估的目标。这个目标需要设定,你刚才的问题实际上是问到了我们根据什么目标来评估。
先讲评估方法。无论对哪一个目标,都应该每次把其他的不动维定下来,然后把变动的那一维明确好,这样一维一维地来精准评估创新的价值或者效果。
当然也可以同时两维,但是你全部改动了以后,是会 confounding,产生混淆,或者这些维度之间的关联或其他未知因素互相影响造成错误的判断。
现在假设我们的评估方法是对的,那么去评估哪个目标呢?这个问题其实在业界也有争议,或者说值得去深入思考。
目前业界在机器学习里面,基本上有两种评估目标。一种就是所谓的数学自定义目标,比如说模型方程里对于训练数据的边缘概率(marginal likelihood)或全概率(complete likelihood);或者拟合中的或然度或者叫error margin(误差幅度),虽然根据标注来定的,但基本上是内置的(endogenous),是基于模型对于数据和误差的假设的。另一种是外延的(exogenous)目标,就是根据纯粹人的判断来弄好。大概就是这两条。
狭义上说,后者就是纯粹用人工标注所定义的错误率,基本上就定义了所谓的榜单。我们常讲「刷榜」刷的是什么榜,就是人为设定好的 gold standard,然后去评选。
这两种方法,第一种方法是有数学自洽度的,对于理论的完备绝对是有用的,因为它能够证明所谓的 consistency,一致性、收敛性,这都是通过自定义的目标可以搞清楚的。但是它的价值也仅在此而已,因为内置目标的优化跟外界的功能目标是否一致完全没有保障。
所以我们会用第二种,exogenous 目标,最简单的就是人的标注。我分两个层面来讲,首先人的标注价值何在,这是有问题,值得讨论的。
我们先把这个问题定下来。假设人的标注是完全有价值的,值得拼力刷这个榜。我们在比分结果做得很高了以后,是否就可以算大功告成呢?我认为仍然是不够的。假设人的目标都是对的,目标函数是对的,但是它对于机器学习学科的发展其实还是不够,因为做人工智能的话,至少现在公众对它很大的要求是要形成工程化,可落地性。
这其中工程的质量就包含了很多其他层面。第一点就是安全性,还有成本、环保等等。这些都跟标注没有关系,或者关系很少。
比如说飞机或者汽车实现安全保障的数字是惊人的。一款汽车要想被交通部批准能售卖,基本上要实现每一亿公里安全无伤亡事故,是有一定道理的。飞机被允许飞的话,基本上还得加一到两个0,基本上是每百亿公里不能出伤亡事故甚至任何事故。这种事故率都是10的-9或-10次方,跟照片识别度达到精度千分之一或者万分之一完全不是一个概念。首先照片识别度达不到10的-9或-10次方,通常我们宣布一个算法成功,基本上精度达到 99.99% 就差不多了。
在飞机零件里怎么能够达到很低的错误率,并不是把飞机实际去飞多少万次以后看它是不是出事故。最后可能会这么做,但一开始的时候肯定不是这样子,它实际上是测试每一个零件。有一个error graph,或者error tree,是有一套图能够把错误的传递(propagation)放大或缩小,是用一个图来表示。然后测试引擎,测试机翼,测试起落架,然后我们能够做出判断,它的每一个错误怎么传递到下一级,是被放大还是被进一步缩小,这都是有很好的理解。
所以上次波音737MAX 机型事件出来以后,最后能够一直追溯到某一个传感器部件的数据识别与操作,发觉在适航认证过程中质量指标没有被及时更新,用了一个简单过时的技术数据来定义了组件的质量标准,对系统未做足够的压力测试,是软件上的疏忽,但最终能够被追溯且锁定问题出处。发现问题所在以后,重新设置这个指标,就可以解决这个问题,防止类似事故再次发生。
在人工智能里面,目前完全没有这样一个方法论或者思路。基本上就是看最后的结论是不是好,然后再开始调参。它从来不是一个分割或者是组合,也从来没想过比如人脸识别或者汽车识别算法怎么能够跟另外一个自动控制软件结合再进行下一步,它们和相关硬件模块的关系,最终是不是因误判撞人,会不会导致能量透支等等。我们都不是这么测试。
所以我现在就想提出 leaderboard 的 insufficiency 不仅仅局限在 leaderboard 本身到底是不是定义的对、是不是在正确的目标里面,而是说它其实基本上就是压制了人们对整个项目和产品的结构和安全度(的评估)。还不包括成本,这个价值还没有讲。
所以它的弊端实际上是非常大的,不仅仅造成了错误的设计问题,对人的心态和工程价值观也产生了影响,使人不去关注安全性、环保性、成本等其他影响因子,或者是标准化、政府监管,这些都无从入手。因为它没有节点,是一个black box,所以很多人做不了。但是你会看到在化工、土木工程,在生活当中,它的环节是清晰划分的。
所以我们在做 regulation(规范化)的时候并非顺畅。规则大家都恨,因为它会降低速度。但是在工程上规范化,它的伤害度或者影响度是可控的,可以说我只规范这一步,其他已经过关了的,可以给它过关。所以可以把焦点聚焦得很快。
在 AI 里面,现在规范化很难做,要么就是你不能享有这个数据或者这东西不能用,黑白分明,要么整体否定,要么整体允许。原因是没有把这个东西分割出来。我觉得研究者本身的思想方法和整个行业的惯用方法,其实是需要去思考的。
机器之心:我记得前段时间有一个团队不做 regulation,在图像分类和识别上也达到了 SOTA 性能。大家都是在追求端到端,近几年这种端到端的优化也好,或者结果也好,业界是非常推崇的。
邢波教授:我对它有保留,实际上我非常反感整天把「SOTA」这个词挂在嘴边,缺乏应有的严肃和敬畏。State Of The Art 不是只指肤浅的一个数字或比分,它实际包含了理论完备性、工程严格性、稳定性、质量、成本等等很多要素;不幸的是它现在被刚刚入门者们完全庸俗化了,搞得跟杂耍练摊似的,每几天就被突破一次,且不论真正重量级选手是不是陪着玩,比赛本身是否有意义。
回到评估,我觉得在评估的标准上应该落地,不仅是产品落地、评估标准化落地,成本也要落地。大家可能没有想到现在训练一个 GPT-3,据报道是 1200 万美元,相当昂贵。这会造成很多结果,一是独家享用,一般人玩不起,这样就造成了不平均性,很小众,造成垄断。另外也有很大的不安全度,因为任何东西使用的越少,就没有办法去充分地测试,就越不安全。所谓「端到端」也经常成为一个噱头,本来应该是最后系统产品的一个体验,现在被当成一个方法论来指导或者开展研发,特别是在很多修行不深但又嗓门很大的从业者中盛行,负影响极大。
言归正传。其实 leaderboard 的分是不是定得对,也是一个很大的问题。到底我们怎么来评估结果的好坏?比如图像标注能达到百分之几,这本身有意义吗?自然图像里有各种各样的背景,人的 reasoning(推理)不只是基于我们看到的,也有很多背景,有很多其他东西。我们可以在很杂乱的自然图像里作出判断,甚至不仅仅是简单判断,比如这个物体叫什么名字、存在与否,还可以做出情绪判断,甚至讲出一些故事。不是有些电影,就是根据一幅画直接衍生讲出来各种各样的有关故事吗?而机器学习做不到这些。所以现在的评估 leaderboard 太高了以后,其实压制了这方面的创新。
我们在解决什么问题?这方面其实现在特别局限,解决的问题很窄,就是监督学习和表征学习这两个例子。更多的学习任务没有获得关注,因为刷不了榜,发不了文章或者发了文章也没人看,所以形成了比较不健康的风气。尤其是年轻的学生,我看他们基本上对真正有挑战的问题没什么兴趣,因为机会成本太高,需要花很多时间,静下心来、不被关注地去做好几年。这些工作现在没有多少人愿意干。
机器之心:这些特别难的问题,您能举几个例子吗,您认为非常有价值,但是非常可惜少有人去从事的?
邢波教授:很多。如今在机器学习里面起了很大的发展作用的,比如监督学习、无监督学习或者增强学习,甚至是对抗学习,它们的任务基本上就是数据导向学习(data-driven learning)。Learning 都言过其实了,它本质上是 memorize,是记忆。记忆以后产生下一个功用,比如 GPT-3 model 其实就是把全世界的数据全装在一个脑子里面,然后它能够复制出来,或者可以 twist 一下复制出来。
比如说它可以产生一段莎士比亚的文字,它可以写出一篇文章,让你读着像莎士比亚,或者读着像另外一个作家,这是可以做到的。让它产生一幅画,看着像梵高的作品。这些东西基本上是基于记忆的。但你也看到有报道了,有些人会问一些问题来 trick 有意捉弄这个模型,比如问它太阳有两只眼睛吗?斑马有没有六条腿?或者直接问加法,1+1=2 它可以做,2+2=4 它也可以做,然后一亿几几几小数点几几几加上几几几,它反而又不会做了。因为它没见过这个例子,它不太会学规律。
刚才太阳和斑马的问题就是 common sense reasoning,常识性推理。Common sense 就是在人的生存环境里边或者信息环境里面的一些背景知识,是我们通过很多其他方面得到的,要么是被告知,要么是看已有的例子。其实我们从来没看过太阳有没有两只眼睛,没见过这个例子。但是我们可能是被告知了,或者是自己读过一些东西,知道太阳不是动物。总之就是拥有这样一些背景知识,让我们有能力做这样的推理。
这是机器学习做不到的。而现在研究这方面的人很少,因为它不是基于大数据的训练,它不需要大数据,需要的是从建模到训练手段和训练评估,一套不同的方法和思路。Judea Pearl 提出了更上一层的一系列问题,叫做 counterfactual,逆事实。
他举了这个有意思例子:如果奥斯瓦尔德不去刺杀肯尼迪总统,后者会不会还在世?这问题很有意思,我们不知道结果如何,但我们可以做出一套推理(reasoning)。我们会说奥斯瓦尔德不去刺杀的话,现在这么多年过去了,肯尼迪总统自己可能也已经因年长而故去了,或者肯尼迪如此地遭人非议仇恨,也许奥斯瓦尔德不刺杀会是另外一个人去刺杀……会有各种各样版本的 story。任何一个人,不需要是智者,都能够想出这些故事演绎。但是 computer model 好像描述这些是有困难的,我现在还不知道有什么 model 可以这么讲解。
Counterfactual 的这种思考方式,是现在的机器学习模型做不到的,但人在日常生活和行动中,会非常自然地切换到不同的思维状态中,用不同的方法来做。所以这个问题很有价值,而且很有挑战。它对于模型本身的表征手段,对于模型的结构、引入信息和规则的数学表示,对于最后的评估方式其实都有影响。
再稍微难一点,曾经有人要求我开发这样一个学习系统:读十本 PDF 格式的大学物理教科书,然后能不能通过大学量子物理考试?实际上,现在的那些超级模型是如此低能,甚至你给它同一个定理的几种不同表述,就像上面十本同一科目的教科书那样,它都无法搞清楚在讲的是同一个定理。更不要说去发现和提出新定理,证明新定理了。
所以创新空间很大,但它还不是主流。当然不是主流也是好事,会有更多的发展空间。我只是举个例子,这是一个挺难的东西。
还有另外一个题目,比如 federated learning,协同学习。它其实针对的也是一个很现实的问题:数据不能集中收集。比如每个实验室或者每一个医院有自己的一套数据政策或运营政策,不能把病人的数据或者是生物实验、物理实验的数据送到一个中心来处理。
那怎么能够形成 knowledge,形成 one piece of knowledge 呢?这跟现在我们在机器学习里面所定义的协同学习还不太一样,现在只是在算法上的一个分布式,只是通过硬件分散。但是刚才我讲的是一个更加深层的运行,它实际上是一个知识交换和最后统一的问题。
这是一种在人的思维过程中很常见的方法。我们经常可以看到一个数学家证明某个定理时,他会采集很多这种分散的结果,然后做出一个综合,甚至还可以进行交流,然后再如是迭代。有句俗语:To solve a problem it often takes a village。Takes a village 什么意思?是大家在彼此互动中独立打造自我,但各自组建是不是向着一个共同目标?有时候是,有时候也不尽然。但是有一些人就会用这种方式来获取分布式的部分的解决方案,然后来做综合,再做迭代。这种学习方式也是现在机器学习领域尚未被深入了解的部分。
我的研究团队小组最近做了一个工作,至少在理论上建立了一个协同学习的优化算法,和原来我们在经典文献里面常用的一个叫做 expectation propagation 的算法,就是贝叶斯后验 inference 的一种计算手段,具有数学上的一致性。它从纯算法问题换一个视角来看目前协同学习的方法是不是模型设计和训练问题,或者是一个系统兼容的问题,还是和一个算法优化增效问题。这种题目我觉得蛮有意思,我不能肯定它是不是最具挑战或者最有价值的题目,但至少它是一个全新的题目,至今还没有获得很高的关注。
这些例子还可以有很多,比如前面提到的开发黑箱优化的方法来实现自动的Learning to learn。我只是想说我们现在做机器学习或者人工智能,花了很大的资源和力气来关注的问题,其实只是所有问题里面的一小部分,还有很多的问题没有得到类似的以及应有的关注。
机器之心:您曾经说过现在很多是以算法模型为中心,但很多情况下在现实生活中是以数据为中心的,要从数据的性质里面找到解决方案,这跟您刚才说的把数据留在本地,然后算法分布式处理属于同一范畴吗?
邢波教授:我知道你可能是指在计算层面上到底是数据向模型走(data goes to model),还是模型向数据走(model goes to data)。现实上的考量是必须要有一个选项,模型得往数据走,因为如果数据不来怎么办?那是没办法的事情。就像大家使用苹果手机,有些人关了 iCloud,就不把数据给上传,怎么办?如果它还想学的话,想给用户做个性化,必须要把它的模型放到用户那里。我觉得这是一个现实的要求。
至于人工智能是不是要以数据为中心,这完全是另一个问题,这不是一个单纯物理的(physical)中心的问题。你这个问题实际上是方法论上的谁作为焦点、作为原点来展开其他题目。
我倒不觉得数据必须处在中心地位,因为从人的角度,我们的学习很多样,不见得非要通过例子。大数据只是一种方法,甚至是一种笨办法,是非常适合机器来做的。但即使是机器,也不见得一天天都要打主场,它还得适应客场的要求。它可能要进入到人的主场环境里面,来匹配人的需求。那时候也许规则是更重要的,也许先验知识更重要的,或者也许某些特殊的功能更重要。比如说我希望来做一个很环保的解决方案,以至于不能用很多电,不能大量地使用冷却水,但还需要有结果。那个时候就得牺牲数据上的这些东西,因为不能说我就做不了了然后彻底放弃。
所以我觉得定义单极的处理方式或风格,其实是不太健康或者是不太 productive 的规划。
三、看人工智能学科发展:定义一个学科的活力或价值,有时就看它是否产生了一种新的人才,开辟了新的研究方向
机器之心:我接下来问人工智能发展这一节。您认为过去这几年,从 2012 年深度学习浪潮开始,或者从 2016 年 AlphaGo 进入公众视野,您截取一个时间点,在这段时间内您认为最重要的发展或者突破是什么?哪些工作能够称得上是有深度、有分量的?
邢波教授:你这个问题其实把我问住了,因为我觉得回答这个挺难的。首先我自己现在看的文章有限,我不能 claim 我读了所有的成果,所以我很难去做高屋建瓴的总结,说谁的工作最重要,我觉得有点冒犯同事了,不应该来就此表态。另一方面,这也是一个很主观的判断。即使我把文章全看了以后,也很难做出一个很公平的评价。
我先把这个 context 讲了以后,可以提两句我个人觉得有趣的工作,我不能说它是最重要的或者是最有价值的,但是我个人觉得很有趣的,或者愿意花时间进一步去了解的。
在过去的三五年里面,让我印象比较深的工作之一是最近 DeepMind 用深度学习的方法对蛋白质结构做预测的工作。我觉得它里边有若干个思想上的创新,不是技术上创新。
通常我们在做这种结构的预测,或者是在做各种预测的时候,都是用 connecting dots forward 的思路,就是往前推演,线性逻辑。比如从因果来推,比如知道了原子成分和排序,蛋白序列,也知道每个原子蛋白序列的化学特性,能够用它来计算化学键,算最小能量,以此推算稳定结构,从一维序列,到二维结构,到三维结构,到四维结构组。我们知道物理里面实际上就是用第一性的原则,first principle。第一性,然后最小能量,然后算作稳定状态,然后蛋白结构,应该是这么一个东西。
据我了解,这份叫做 AlphaFold 的工作不是基于第一性原则弄出来的。它是用了间接的、有点舍近求远,是一个非常间接的 solution。它是先收集了所有的匹配,就是说每个原子和分子对之间的距离,这是可以通过 X 光,核磁共振,通过各种各样的物理化学实验做到的,它先就收集了这么一个数据库。
这实际上就提供了分子(本来是一维序列)的所有二度关联信息,即点到点之间的物理距离。它同时又收集了大量已知的蛋白质三维结构,然后用深度学习来做这两者的 input/output 的 blackbox mapping。
首先做了从一维序列到二维 pairwise distance matrix 的模型。Pairwise distance matrix 的好处是得到了对蛋白的二维全局观,因为把所有的 n×n 的 pairwise distance 展现在一张图上,就像我们通常的二维图像一样。然后它再通过 pairwise distance 对这个整个蛋白的结构做了黑匣子式的预测,也是通过监督式深度学习。
它的思路绕过了第一性原则——通过算最小能量值,或者是通过物理计算,通过模拟来产生最佳的解。AlphaFold 是直接通过全局的,通过由于结构而产生的 pairwise distance function 来做反推,反推什么样的结构才能够产生这样的 distance function。这个方法很有趣。有点像我们去旅游的时候,不知道自己的下一步目标,但是由于我知道到了下一步目标以后的再下一步目标,然后我来反推下一个目标在哪,是这么一个思路。
这里面充分应用了深度学习的长处,深度学习对大数据到大数据的 mapping 的学习能力很强,能够看到人看不到的一些 insights。从 a 到 b 这一步,机器虽然不善于学,但是从 a 到 c 反而是它能够学到的。人是不太容易学到 a 到 c 的,但是机器学习很容易学到这一部分。然后再从 c 回到 b,这也是机器学习能学的。所以它把 a 到 b 这一步整体 pass 过去了。
我觉得这个思路非常有意思,为什么?因为从 a 到 b 是第一性,是局部的计算,必须得通过紧邻的原子分子的相互作用一步步来 threading,就像一根线怎么慢慢地给它折叠起来,它是一步一步折叠的。但到了 c 的时候,它已经变成了 pairwise distance function,有全局的 information。在预测每一个三维结构的时候,它实际上是通过全体的二维 pairwise distance 来做预测。从全局到局部的预测,通过深度学习的方法来实现。
这个思维方法特别奇特,我甚至觉得有可能获得诺贝尔奖,通过机械的方法实现了对数据的全局观,然后通过全局再来预测局部这样一个结构。在人的计算过程中,我们很难做全局的预测,因为它的计算量太大了,做不到这一点。我不知道有没有讲清楚,但我觉得它的思路本身是有一定的突破性。
机器之心:可不可以类比 AlphaGo 下棋,论文里面说 AlphaGo 自己跟自己对弈,产生了一些新的定式。这些定式是人类此前没有想到的,而且其中一些比人类之前发明的还要好。可以这么类比吗?
邢波教授:这个不太一样。AlphaGo 也是一个创新,但是我觉得更多地利用了算力,大量的算力和不断的模拟。刚才蛋白质结构预测的研究其实并没有用太多的算力,它实际上是体现出来一种新的思维方式状态。
AlphaFold 是通过从局部一步跨到全局,然后再跨回局部的预测。这不是人的惯常思维方式。
机器之心:它确实知道了所有的结构,所有的距离,然后自己再倒回来推,这可以理解为一种大数据暴力吗?
邢波教授:我不这么理解,因为数据并不大。它实际上是数据的形式,数据的视角非常有趣。它利用深度学习模型给人提供了一个新的视角,来看后结构的结果,然后从后结构的结果来推测到结构,跳了一步棋,然后再往回看。这是我的理解,这个思路我原来没有想过。
机器之心:您认为这是模型的力量,还是设计模型的人的理解?
邢波教授:是人的理解。我觉得这里面有很大的人的设计因素,这个设计非常有趣。所以我认为它是一个突破,因为其中人做的工作很大,里面显然有相当原创性、聪明的一套思维方法,设计出这么一个 pipeline,而不只是暴力地去拼武器竞赛。
机器之心:那 GPT-3 呢?
邢波教授:我觉得 GPT-3 也算是一种创新,但是对它的突破性没有特别 impressed。它前面有好几个步骤,是一个渐进的东西。我想最近几年里深度学习领域比较主要的工作就是所谓的 attention model。因为它对不同表征(representation)能够做 alignment,能够产生对应性。
基于 attention model 又发展到 transformer,transformer 就是一堆attention models,我们称作 attention heads,然后形成一个列,这样能够使关注性部署到一个复杂的概念,或者是一个比较大的区域。GPT-3 大量地采用了这样的设计,有点像采用了很大量的记忆元来组成一个超级集合,但是记忆元已经被发明,记忆元的连接也是在小型里面实现了的,GPT-3 把它做得更大,这是我的理解。
当然做大了以后,它在工程上能不能训练,训练里面对数据的使用怎么来设计 batch,怎么让它收敛。这些东西都是技术上一些比较重要的工作。但是我没有看到它是彻底原创性的工作。整个 GPT-2、BERT、GPT-3 是随着硬件的发展,随着数据的增加,有一个很明显的渐进的路线,所以我不能把它归类成突变或者突破。
基本上我可以预测 GPT-4 在两年以后就会出现,也许更快,这是我对它的定义。它还用了一个 idea,很重要的 idea,汲取了很多前人的经验,叫做 self-supervised training(自监督训练)。在语言里面自监督训练这些技术和概念是很多人不断地构建出来的,比如我能够把词抠掉之后预测这个词,把句子折叠一下用后半句来预测前半句或者反过来,或者是用一些 combinations,这些手段都大量地用在了训练这些 GPT 或者 language model 里面。
所以我觉得 GPT-3 是一个集大成者,但是并没有形成原理或设计或算法上的巨大的原创性的突破。
机器之心:在评价研究好坏的时候,相较于工程实现,您更看重原创性的思路或者是思考方式。我可以这么理解吗?
邢波教授:未必。我并没有判断谁好谁坏,应该和不应该。它们是不同的,按照不同的需要来做的。原创本身也不是为了原创,都是需要所致。在这项工作里面,它做了应该做的需要做的东西,所以我觉得 GPT-3 还是一个很了不起的工程里程碑。它得到的这些关注度我觉得没有问题,应该是挺实至名归的很好的工作。我只是说我不能把它叫成原创。「原创」在我的定义中是一个中性词,不是一个褒义词,也不是个贬义词,它只是对这个工作的定性而已。
我还想补充一个工作,这样可以把最近的成果做一个更好地覆盖。我觉得有一个方向值得关注——system and machine learning。我觉得它有可能是这几年深度学习和机器学习运动里,另一个比较重要的新的突破点。它的突破点不是体现在某一项成果里面,而是说这个领域被诞生出来,产生了一个新的领域。
SysML 实际上是把原来操作系统这个领域和机器学习结合起来。我个人认为这是一个很重要的新突破,因为原来计算机科学家是有明确分工的,做算法的人或者建模的人是不去碰机器的,不去问机器里面的卡怎么来插,或者带宽如何来控制,通讯如何来控制,程序如何编译,这些都不理会。就像我们在做 computer vision 的时候,我们对照相机或者像素编码方法,比如对于 JEPG take for granted。有时我跟人说 Computer Vision 整个领域其实是定义在我们对于影像的编码上面,我把编码变的话,也有可能会导致全领域接着改变。因为人类视网膜看到的图也许和机器看到的图不一样。
一直以来机器学习是有它的边界的,边界就定义在数据和数学上,但是没有达到硬件和计算环境里面。但是,SysML 第一次把边界给打破了,它使系统和机器学习结合在一起,当成一个题目来做。这有突破性的意义,有点像把火车的设计和铁轨的设计结合在一起,而不是两边分别各做各的。
这里边就问出了很多新的问题。一开始的时候是认为系统达不到训练的要求,要重新设计系统,所以出现了像参数服务器这样的工作。我以前的工作也组成了 SysML 领域早期成果的一部分,包括参数服务器的架构、理论和原型系统,特别是我们第一次对于不同通讯原则作出了严格的理论分析,提出了数据并行和模型并行两种范式,给出有限异步通讯在这两种范式上的收敛性的理论证明,以及建造实际系统上的可扩展性。2012 年、2013 年的时候出了一批理论、工程和系统上的新突破,那时候的目标是希望能够设计出新的通用系统,能够适应机器学习的需要。
再过了几年以后就发觉新的系统太局限,机器学习算法发展得太快,跟不上,以致出来了专门为特定算法或模型来服务的系统。然后就是在这个基础上既优化系统,又优化算法,互为优化,这是第二个波——codesign。也持续有若干个 paper 是做这种 codesign。我们组 Pengtao Xie 博士的 Orpheus paper 就是其中的例子,提出了 sufficient factor broadcast 这个概念。
到了最近几年发现这条路可能也很难走,因为 codesign 太昂贵太小众,要既懂系统,也懂算法,还懂数学,这样的人太少了,能玩这个东西的人特别有限,所以做不大。
最后再回归,还是来做通用系统。但这个通用系统不是单一系统,还有可能是一个系统库。比如说我把所有系统都放在库里边,然后根据不同的算法或者模型需要来选择不同的通信协议,比如可以做 parameter server,也可以做 allreduce,也可以做 sufficient factor broadcast。然后在通讯里面可以是同步,也可以是异步,也可以是半同步,可以提供这么一个选项。这个系统全面丰富,也许可以满足各种需要,这是最近的方向之一。我们组 Hao Zhang 博士的 AutoSync 系统就属于其中之一。
然后可能又有一个新的问题:能不能形成自适应系统?因为虽然库都放在那里了,但是选择用哪个,用多少,用多久,还是需要很多专业知识。能不能让系统本身是智能的,等于是用智能的系统来训练智能的模型,两边都来智能。它可以自己来调节需要,包括在 schedule 里边,包括在通讯里面,都可以来做 adaptive 的操作。这也是最近的一个新的方向。我们组Aurick Qiao 博士最近在 OSDI 获得最佳论文奖的 AdaptDL 系统就属于这个方面的一个突出成果。
更新的方向还有多维的并行。我们也可以把并行进行拓宽,从数据并行到模型并行到 pipeline 并行都可以来同时做,现在可能叫「三维并行」,也是个时髦流行叫法。
SysML 这个方向孕育出很多新的问题和新亮点,都是原来没有被碰过的。所以从技术角度,还有从工程角度,至少是创造了很多岗位可以去干活。但是从学科、从理论本身其实也提出很多问题,因为每一步这样的工程创新都对原来的数学模型是一个 reduction,都是一个削减,是凿了一个窟窿,使之前的模型不再正确完备。然后我们就要证明它是不是有数学上的正确性,提出了这种理论上的问题。这个方向最后能通到哪去,还很难预测,但我觉得它是一个相当丰富的方向,可以引发出来很多新的题目。
作为一个新学科来说,SysML 是过去几年蛮重要的一个新生事物。原来没有被这么关注,现在有一批年轻的学者开始崭露头角,文武兼备,他们既会算法也会系统。这批新的人才的产生就是这股发展潮流的结果。这是我原来没有见过的。
机器之心:做框架的或者做编译器的,算属于这一批人吗?
邢波教授:广义上也可以算。其实这个群体里边包含了各种各样的人,有出身框架(architecture)的人,但他们的服务目的是为了 AI,他们就进入这个圈了。框架可以服务于数据库,也可以服务于存储,或者 cryptography 来做隐私,这也是系统里边的需要。也包括了做编译器的人,因为机器学习代码的编译质量,实际上也影响了它的人工编码成本和程序的 performance。还包含了做算法的人,如果他很有兴趣去研究系统或者是 infrastructure 对 performance 的影响的话,他们也包含在其中。
另外有一批甚至是更稀缺的,对这几个领域都懂跨界人才。例如最近 CMU 大力延揽的陈天奇博士就是在系统和 AI 上都有相当好的成果的年轻学者。这样的人现在出来了一批,比如刚才提到的 Aurick Qiao 博士,Hao Zhang 博士,以及更早一些的 Matei Zaharia 教授,Qirong Ho 博士,Mu Li 博士都是其中突出的代表。
我通常定义一个学科的活力或者是价值,有时就看它是否产生了一种新的人才,提出了新的问题,我觉得 SysML 是有这样的特质的。
这里我要提一下,我们的公司 Petuum 就是在这个业态变化中成长起来的。它一开始基于我们在参数服务器上的创新,后来我们一直在这里边加入了不同的元素,包含了比如说自动调参,机器学习建模这种乐高一样的组合性,自适应底层架构等等。我觉得在这个赛道里面,会孕育出来下一代真正的新型创新公司。很高兴地看到,刚才提到的 SysML 领域最近涌现的新锐之一,Aurick Qiao 博士能秉承持续创新,并担当起落地发展的重任,已经成长为 Petuum 新一代 CEO。作为他的博士导师,我深感骄傲。
同时,邢波教授特别留言:
作为学物理出身的计算机学家,我对于杨振宁先生提出的杨-米尔斯规范场和物理标准模型一直怀有深深的敬意,而在这次访谈中提到的我们的机器学习标准方程(standard equation)的工作,也是完全受到杨先生对于数学简洁深刻之美的推崇的激励。
这次访谈的发表正值杨先生百岁生日,我仅以这个还非常粗浅的尝试性工作和相关的妄论向杨先生致敬,也希望他的科学精神能在后辈中继续发扬光大。
本文来自微信公众号“机器之心”(ID:almosthuman2014),作者:闻菲,36氪经授权发布。
相关推荐
顶级AI学者邢波教授:机器学习缺乏清晰理论与工程框架,需重新思考评估方法及目标
CMU教授邢波出任全球最富AI大学校长,曾师从图灵奖得主
顶级AI视觉领域教授,朱松纯回国任教清华
搞深度学习框架的那帮人,不是疯子,就是骗子
机器学习之父说,别把啥都往人工智能上扯
机器学习泰斗迈克尔 · 乔丹:不是什么都叫AI的
AI的哲学系思考—认知不变性与AI
2019机器学习框架之争:与Tensorflow竞争白热化,进击的PyTorch赢在哪里?
CMU计算机及心理学系教授Ken Koedinger:用AI探索高效学习的边界 | AIAED全球AI智适应教育峰会
「一流科技」专注研发新一代深度学习框架,完成高瓴创投独家领投的5000万人民币A轮融资
网址: 顶级AI学者邢波教授:机器学习缺乏清晰理论与工程框架,需重新思考评估方法及目标 http://www.xishuta.com/newsview51198.html
推荐科技快讯






- 1问界商标转让释放信号:赛力斯 95009
- 2人类唯一的出路:变成人工智能 19751
- 3报告:抖音海外版下载量突破1 19527
- 4移动办公如何高效?谷歌研究了 18985
- 5人类唯一的出路: 变成人工智 18857
- 62023年起,银行存取款迎来 10182
- 7网传比亚迪一员工泄露华为机密 8271
- 8五一来了,大数据杀熟又想来, 7340
- 9顶风作案?金山WPS被指套娃 7131
- 10大数据杀熟往返套票比单程购买 7077



