脚镣之舞:还原法律AI在中国落地的真实道路

AlphaGo 的成功离不开几个先决条件:标注零成本、存在一个上帝视角告诉机器明确的输赢结果、完全信息下的博弈等,所有这些条件在法律(乃至绝大多数垂直领域)均不存在,其中,没有大规模现成可用的标签数据是法律 AI 领域的最大现实。玩家们不仅需要选择正确的机器学习算法、积极融入先进的深度学习模型,还要把法律知识图谱放进系统中,针对性地准确处理特定问题。所有这些都大大加大了法律 AI 的落地难度,也暗示了智能背后大量的人力工程。
然而,很大程度上影响用户体验的并非定罪量刑预测、类案推送这类高精尖应用,而是诸如数据互通、卷宗电子化等基础设施。尽管难题不少,但我们也要看到各种炒作和极端言论正逐渐让位于务实讨论,学界认为未来十年会是 NLP 的黄金十年,也描画了一副更加智能的法律 AI 图景。我们仍然值得对这个领域抱以乐观。
本文来自微信公众平台:机器之能(ID:almosthuman2017),撰文:微胖。
当 20 岁的温州乐清女孩赵培辰坐上钟元的滴滴顺风车后,就再也没有回来。距离最后一条求救微信十多个小时后,钟元被警方逮捕,残酷真相也随之揭开:
接到赵培辰后,钟元选择了一条极为生僻的路线,行至无人处后将其手脚捆绑起来,胶布封嘴,索要钱财。
9000 多元到手后,钟元再次将车开到信号不好的偏僻处,强奸了赵培辰,并用匕首刺其颈部,致其死亡。随后抛尸,离开。
这就是震惊国人的「滴滴顺风车司机杀人案」。
两个应用场景:经典、前卫
目前,案件正在审理中。笔者尝试粗颗粒地描述一下法官「加工」案件的过程:
在犯罪构成要件的指引下,拆分案件事实,将不同事实部分「封装」到相应构成要素中。
比如,捆绑、用胶布封嘴的行为,是否构成「当场使用暴力」(抢劫的行为要素之一)?用匕首刺其颈部,致受害人死亡,是否属于非法剥夺他人生命(杀人)?
构成要件「封装」完毕后,法官还要考虑其他要素,比如,犯罪特殊形态(是否存在中止?)和罪数(数罪并罚?),等等。
最后,根据所涉条文(比如《中华人民共和国刑法》第二十四条、第二百六十三条、第二百三十二条等)完成定罪与量刑。
不过,这仅仅完成了一半的工作。
裁判不是追求独创性的文学创作,恰恰相反,法官需要将个案嵌入类案体系,力求同案同判。
和主要服务 B、C 端的美国法律科技市场不同,当前中国法律智能市场中,面向 G、B 端的法律智能公司占到近 50%,无论上述哪一个工作环节——定罪量刑预测还是类案分析,都是这些公司力图覆盖的经典场景。
忒修斯之船:从属性相似到要素相似

1 世纪时的希腊作家普鲁塔克提出了这个问题:如果忒修斯的船上的木头被逐渐替换,直到所有的木头都不是原来的木头,那这艘船还是原来的那艘船吗?这类问题现在被称作「忒修斯之船」。
挪移到法律领域,这就是一个如何识别类案的问题:
一个案件就像船一样,由许许多多木板或因素组成,有时替换掉一个因素就可能对裁判造成实质性影响。什么样的情况才属于类案?
美国匹兹堡大学法与智能系统教授 Kevin D. Ashley 很早就想到了办法: 寻找重叠的要素。重叠的要素越多,系统推荐的类案就越合适。他甚至设计了一款类案推荐系统。
不过,三十多年后,这枚思想火花才开始在大洋彼岸的法律智能系统中落地。
直到十多年前,我们的机器解决手段仍然非常粗放。「当时就是寻找案件属性相似。」华宇元典 CTO 李东海说,当时他还是华宇集团的技术研发骨干。「比如,案由、法院层级、当事人属性意义上的相似。」
法院层级、当事人属性这类信息,确实有用。比如钟元的代理律师可能想要了解温州中院(审理案件的法院)有关犯罪中止的以往案例。然而,这些信息与案件是否类似,是两个完全不同的问题。
至于「案由相似」,这个标准太粗放以至于把球又踢回给了法官:
钟元杀人,与孕妇产后杀婴、儿子为避免母亲受辱而愤然杀人、误将白糖当砒霜杀人、小学生杀母等案件,虽同属故意杀人案由,但这些案件要点各有侧重,不加选择地推给法官,只会让他们抓狂。
虽然当时会定期公布指导案例,但其约束效果也极为有限。

华宇元典是华宇成立的子公司,生日是2016年7月25日,狮子座。
基于文本相似的类案推送,是 2010 年以后的事情。
华宇、国双等公司陆续用 NLP 计算文本相似,特别是词嵌入(word embeddings),可以帮助系统轻易找出与目标词语最相似的词语。
目前法律 AI 市场中的文本相似技术,主要是语词级别:采用词作为特征项,特征词作为文档中间的表示形式,实现文档与文档、文档与用户目标之间的相似度计算。
只有华宇元典等少数几家公司能做句子级别的相似,实现短文本的搜索(比如,「在公共场合起哄闹事」、「无故追砍路人」),篇章级别的相似也在探索中。
但是,技术人员眼中的文本相似与法官眼里的类案,仍然存在很大差距。
「我们很难说服法官这就是类案,因为这不是他们的实际交流方式。」李东海说。
比如,讨论钟元所犯下的罪行和之前的「空姐被杀案」是否类似时,法官不会讨论文本有多相似,而是类比法律要点,比如行为手段、结果等,就像本文前半部分描述的那样。
另一个经常被拿出来讨论的例子是「自首」。
「到公安机关自动投案」、「被追打着躲进公安局」、「在家属陪同去派出所的路上被公安机关抓获」,意思一样,都在讲自首,虽然可以通过标注一些训练数据,训练语义层面的分类器加以处理,但是,法官通常希望输入「自首」后,直接检索到包含诸如「投案,并如实供述犯罪事实」这样事实的案例,在华宇元典看来,这种认知需求没办法仅凭文本相似加以实现。
2013 年,有了数据、技术的支持和国家政策层面接纳,华宇元典、国双等公司在文本相似、属性相似之外,推出了要素相似的检索模式。
所谓法律要素,就是影响法官裁判的最小颗粒度法律事实(要素)。
比如,交通肇事罪涉及的法律要素包括法定死亡人数,重伤人数、被害过错、涉案损失、醉驾、毒驾、无证、无号牌、报废、超载、与准驾车型不符,逃逸,自首,累犯,等等。
两个交通肇事罪案件,案由相同,但只有相同要素越多,才越类似。
不过,黄琳娜补充道,虽然前两种技术各自存在不足,但「仍然具有产品价值和意义,」最终仍然需要三者合力,实现检索目标。
NLP 与知识图谱:两种技术的深与广

实现要素相似搜索,就要构建知识图谱。
你可以认为知识图谱是一个知识库,这也是为什么它可以用来回答一些搜索相关问题的原因。就笔者接触过的两三家法律科技公司来看,大家的法律知识图谱构思比较相似:
以刑事案件为例,包括犯罪构成要件、量刑情节、法律规范、刑事政策等方面,在犯罪四要件的逻辑指导下,形成图谱基本架构,至于「细枝末节」,则从裁判文书、法律、司法解释中提取要素予以充实。
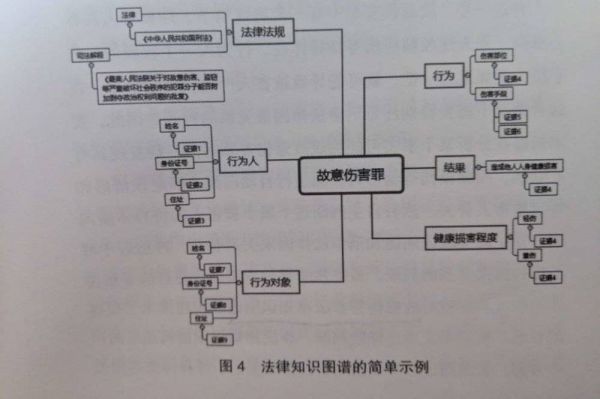
故意伤害罪知识图谱构造思路的简单示例
以元典智库为例。
如果一位法官正在承办关于自首的刑事案件,查找类案时,可以先输入「自首」。由于已经建构了相关刑事领域的知识图谱,这四个字在系统眼里不再是一个字符串,而是一个实体,系统会提示法官根据法律要素来搜索:
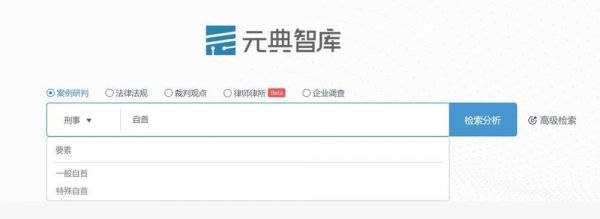
选择一般自首,系统就会推送要素相似的案例,甚至包括不带自首二字却是在讨论自首的类案:
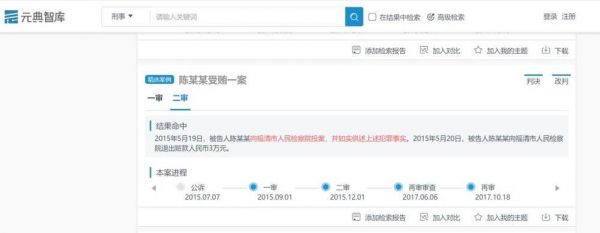
但是,法律知识图谱的功能远并不止于此。这要从另一个经典应用场景:罪名和量刑预测说起。
近些年,输入一个案件事实描述,预测法条、罪名和刑期的这种有监督学习(属于文本分类任务),越来越受到关注,这也是前不久结束的首届中国「法研杯」的竞赛项目。
从获奖情况来看,三甲团队取得的一些成果基本上都建立在深度学习模型上,「已经属于比较成熟的应用,」李东海告诉我们。
比如,「罪名预测任务上,我们叠加了多个模型,比如双向 LSTM,将各种模型串接并联,整体性地进行预测。」李东海说。
另外两支获奖团队——国双和达观也尝试了深度学习模型。国双尝试了 RamNet,达观数据也积极推荐 FastText,TextCNN,HAN 等当红模型。
虽然罪名预测与相关法条推荐的准确率可达 90% 左右,但是,这些先进的文本分类模型需要十万乃至百万级以上的数据,一旦遇到小样本罪名、稀有罪名,深度学习的方案就会捉襟见肘。
比如,长尾罪名以及重要的量刑情节(「入室」盗窃的「入室」)的样本很难达到训练要求,这个时候「华宇元典会借用知识图谱中的法律法规、司法解释中相关罪名和要素的定义规则,实现罪名预测,这样可以大幅度提升小样本罪名的预测准确性。」李东海说。
另外,无论是针对混淆罪名的预测,还是就某些法律要素进行更加深入细致的分析,NLP 的效果也是不够的。
学过法律的人都知道,寻衅滋事罪和故意伤害罪容易混淆。从文本上看会有很多一致,但蕴含的法律知识不同。「通过知识图谱中的法律要素来做区分,效果会比较好。」李东海说。
不过,「做量刑预测,必须用到知识图谱。」李东海说。
量刑需要有一个推论过程,知识图谱可以将一段文本映射到法律要素(比如重伤人数、手段等),再根据要素预测量刑,相当于做了一番解释。但是,深度学习是一个黑盒,法官很难接受。
事实上,这三支队伍都有构建自己的法律知识图谱,华宇元典在法律知识图谱领域起步较早,已取得法律知识图谱的相关专利。
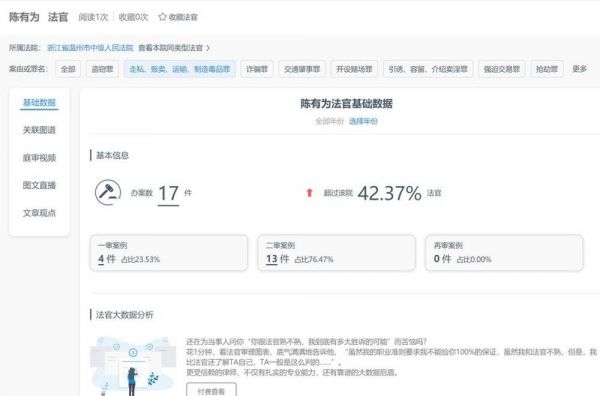
元典智库对法律主体的分析,示例中的陈有为法官是这次「滴滴顺风车杀人案」的承办法官,也是温州中院常务副院长。这样的分析也是国外法律 AI 公司非常青睐的应用场景。
目前,拥有法律知识图谱的公司除了上述三家,还有明略、法狗狗、擎盾、律品等。当然,根据公司业务和体量不同,知识图谱的具体设计,覆盖广度和挖掘深度也不同。
由于知识图谱需要根据一个个具体案由分别搭建,目前仅刑事罪名就有 469 个,民事更多,因此,没有一家公司能够搭建出覆盖所有案由的知识图谱。
元典是做法是从一个常见案由开始,形成一款产品之后,根据用户针对知识挂接、推理提出的反馈,不断补充、修正和迭代,小步快跑。
目前,元典睿核支持的刑事罪名案件覆盖量占法院相应收案数量的 90%,民事罪名案件的覆盖比例为 60%,行政案件支持提取多类案由。
「从支持法官主要的业务场景来说,并不需要面面俱到,我们希望先完成常见案件的支持,满足当下的需求。」黄琳娜说。
因此,公司接下来仍旧会以广度为先,覆盖更多的案由,更多的数据种类和产品。至于深度方面,比如针对某个要素要更为深入的分析,需要和特定的产品和应用挂钩,李东海说,比如侵权责任纠纷、网络商标、道路交通事故。
知识图谱虽然是一大步,但距离真正复杂的逻辑还有很大的距离。
有学者直指这些系统唯一的意义在于「事后控制」。比如,法官可以知道全国同类案件中,他的这种判决包括量刑的偏离程度如何。
在李东海看来,学术型需求经常关注的是数据稀少的个案,而且关注的要点可能就是某一个。「这类推荐需求,没办法通过一款搜索产品来满足,还需要结合搜索、深度挖掘等技术予以定制化地解决。」
不过业内也承认,类案推荐属于这个领域的终极问题。如果这个问题解决了,其他问题,比如定罪量刑的预测等,都会得到很好的解决。「这是一个需要不断去靠近的终极目标。」黄琳娜说。
和 BAT 比起来,目前垂直领域的知识图谱构建还处在非常初级阶段,法律知识图谱也刚起步。
虽然在有些知识图谱公司负责人看来,当前对知识图谱的刚需仅存在国家安全、金融安全等少数领域,但是,知识图谱在司法智能应用方面仍然被业内看好。
AI 可能首先成为专家,再成为一个孩子,幂律智能 CEO 涂存超曾在一篇文章中写道。
No free lunch:被忽略的讨论前提

现在,人们有关法律人工智能的对话已经从危言耸听的机器人律师、法官,逐渐转向如何在日常流程中利用好新的技术。
过去几年中,那些炮制各种极端言论的人都忽略了一个基本事实:
AlphaGo 的成功极为特殊:标注零成本、存在一个上帝视角告诉机器明确的输赢结果、完全信息下的博弈......
所有这些先决条件,在现实生活中都不存在。
先从不完全信息下的博弈说起。
越封闭的应用场景,机器越容易取得成功。所谓封闭,是指一个有限的知识子集足以支撑应用需求。
AlphaGo 的成功很大程度上得益于围棋游戏规则有限,游戏过程也不会用到下棋规则之外的知识。
这与最近又要开打的《星际争霸》不同,后者是一个不完全信息下的环境,更加贴近真实,一旦取得部分突破和进展,对商业和社会发展都会带来极大影响,比如刑侦和审判活动。
公安人员在破案过程中会用到大量常识,嫌疑人往往是基于证据根据常识进行推理而锁定的,让机器代替刑侦人员破案仍十分困难。
至于审判活动,从实证(法律现实主义)角度来看,则更为开放。美国著名法官、学者理查德·波斯纳曾在《法官如何思考》一书中,详细分析了诸多影响和塑造法官前见和判决的因素。
去年发表在《多伦多大学法学杂志》上的一篇名为《预测、说服以及行为主义的法理学(Prediction, Persuasion, and the Jurisprudence of Behaviorism)》研究曾警告,自然语言处理所预测的司法裁决实际上忽略了有价值的信息,这种预测呈现的统计学上的相关性并未考虑相关素材具备的丰厚历史意义。
比如,很多应该被归为侵犯人权类的案件因此被算法忽视了(如关键词「儿子」被算法关联到「家庭成员」项下而非「重男轻女」)。
裁判文书只是记录案件处理过程和结果的官方文本,不等于案件本身,很多案外因素不可能原原本本地体现在判决书中。
不少人因此主张,法律人工智能应更多用于诸如合同的审查、起草等非诉业务,较少用于预测裁判等诉讼事务。即使涉及审判,也要从常见多发、但案件简单明确的案由着手。
这也是为什么大多数法律科技公司主动选择诸如劳动争议、借贷纠纷、婚姻继承、交通肇事、盗窃抢劫等领域的原因。

除此之外,数据的规模、多样性以及标注成本等,都不同程度制约着法律 AI 的落地效果。
比如,现在的机器学习技术对强监督信息,高度依赖。当前在商业领域的机器学习应用,包括语音识别、图像识别、句法分析、机器翻译等,绝大部分都采用的是有监督学习。
为了得到正确的输出,往往需要人工来标注。
法律领域面临的最大现实,就是「没有大规模现成可用标签数据」。这不仅是华宇元典的认知,也是行业共识。法意科技常务副总经理陈浩也曾表示,这个领域最大问题之一就是连公开的标注数据集都没有。
而且,由于法律数据绝大多数属于非结构化数据,这不仅意味着更高的标注人力成本,也对构建高质量的知识图谱提出了更大的挑战。
有些人甚至认为,法律数据结构化是目前面临的首要问题。
另外,诸如长尾案件这类低资源数据,不仅对定罪量刑提出了挑战,也给知识图谱的建设带来困难。
目前,华宇元典主要从两个方面入手缓解这些压力。
一方面,利用资深法律人的丰富经验,也会通过华宇的全国渠道跟客户谈合作,开展联合研发,定向积累数据;
另一方面,由于案由之间也不是完全割裂开,比如都属于侵权这个大类,因此,可以从其他数据案由中学习一些共性部分,迁移给长尾案件,然后针对一些重点进行学习。
不过,在迁移学习等技术没有成熟的今天,通过对现有数据进行标注效果仍然要好于调整算法。
达特茅斯之夏

采访华宇元典时,我们所在的会议室名字叫「达特茅斯之夏」。从那个夏天到 AlphaGo 惊艳世人,已然过去一个甲子。
然而,当我们孜孜不倦讨论着高精尖的智能应用时,很多人未曾料到制约司法人员用户体验的不是类案推送、量刑建议这样的尖端应用,而是电子卷宗识别、数据互通互联、规范性文件及时公开等非常基础性的问题。
黄琳娜讲了一个真实案例。
公司曾经承接了某法院劳动争议智能辅助系统的项目,该系统可以识别劳动争议起诉状要素,并为简单案件生成庭审笔录,以及裁判文书初稿。
出乎意料的是,「我们遇到的最大阻碍不是技术,而是这个法院没有起诉书的电子版,」黄琳娜说。
由于目前最好的 OCR 也无法确保百分百的识别率,如果选择 OCR 实现文书电子版化,那就意味着法官、书记员还必须校对 OCR 后的结果,这等于增加了法官的工作量。
而且,无论是当事人还是司法人员,观念上还是不太信任电子版本,尽管当前技术可以保证电子版本不被篡改。在元典看来,比较理想的做法是,当事人直接提交电子版起诉材料,并提交纸质版入卷归档。
法院智能产品认知能力释放的前提,需要建立在卷宗数据化的基础上,像这样例子还有很多。
「我们的日常工作并非都是在攻克先进技术,有相当一部分是努力推动各种为释放认知能力所不可或缺的基建工作。」黄琳娜说。
数据互通,是元典经常提及的另一个基建问题,也是自华宇以来,一直在做的事情。
数据不是因为大而产生价值,而是因为在线上而产生了价值,因为数据从此可以在更大范围流动它产生的价值,这是真正的数据带来的巨大变化。
虽然中国基层直至最高法院内部数据是联通的,在像美国这样的司法制度下几乎不可能实现,但是,如何与外界的律师、当事人的数据资源打通,仍然是个问题。
这里不仅有制度上问题,也需要技术方面的支撑。比如,如何自动鉴别一些机密或不宜公开信息(比如身份证)并将之模糊掉。

从左到右依次为:公司 CTO 李东海、COO 黄琳娜、CEO 邹劭坤和副总经理张斌琦
未来十年,是 NLP 的黄金十年。
微软亚洲研究院的科学家们在一篇文章中写道,其中,法律、金融等领域对 NLP 的需求会大幅度上升,对 NLP 质量也提出更高要求。十年之后,随着 NLP 进步,「机器人会帮助律师找出判据,挖掘相似案例,寻找合同疏漏,撰写法律报告。」
即便将目光收回到现在,刚刚走过的 2018 年,大多数精彩也来自 NLP。
比如,作为里程碑的 BERT 节省了从头开始训练语言处理模型所需的时间、精力、知识和资源。
法律行业也深受其益。
「在发布的当天,就拿到资料做了尝试,看了结果,BERT 更适合做预训练这一块。」李东海说。
推出法律智能问答机器人「法小飞」的科大讯飞和国双在积极尝试后均表示,相较于过去采用的模型,该模型大大提升了预测结果的精准性。
前文谈到的低资源数据、模型的可解释性、解释(explanation)等问题也得到了广泛讨论和关注。
在产业领域,关于 AI 的炒作也开始降温。
「我们目前仍处于人工智能在法律领域进行狭窄应用的阶段,」ROSS CEO Andrew Arruda 在接受外媒采访时曾说道,
「(处在狭窄应用)这个周期可能会持续 12 个月左右,从那时起,我们将进入采用周期的下一个阶段。在那一点上,我们将开始看到整个行业的法律实践会如何演变。」
在《人类简史》中,作者赫拉利给足了法律 C 位的戏份:
人类和黑猩猩之间真正不同的地方正在于虚构故事,它们使得大规模协作成为可能,人类也因此踏上文化演进的快车道,将那些还堵在生物演进道路上的同伴,远远甩在了后面。
法律,正是这些虚构故事中极其重要的一个,法律人就是现代社会法力强大的巫师。
如果这个虚拟故事讲不下去了,即使语音识别技术做到 100% 的精准,又有什么意义?
要乐观。
相关推荐
脚镣之舞:还原法律AI在中国落地的真实道路
知料 | 543 天后,孟晚舟的脚镣没有被解开
美颜党的克星:AI技术一秒还原未修图的你
「土豆数据」:定位地理信息空间云服务商,真实还原你眼中的山河湖海
将人工智能融入三维建模引擎,「大势智慧」要用二维图片建设真实世界的三维底图
自动驾驶“脚步”临近,奥迪牵手中国 AI 芯片企业加速技术落地
斯坦福开设AI法律课,人工智能能否成为法律主体?
数字孪生还是个概念?「泰瑞数创」已在智慧城市、工业、自动驾驶落地
中国的自动驾驶还缺什么?真实环境路测、产学研的结合、有耐心的投资人
云计算巨头会战“云+AI”,“商业落地”会是金山云的杀手锏吗?
网址: 脚镣之舞:还原法律AI在中国落地的真实道路 http://www.xishuta.com/newsview53.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95228
- 2人类唯一的出路:变成人工智能 21183
- 3报告:抖音海外版下载量突破1 21148
- 4移动办公如何高效?谷歌研究了 20339
- 5人类唯一的出路: 变成人工智 20338
- 62023年起,银行存取款迎来 10336
- 7五一来了,大数据杀熟又想来, 8596
- 8网传比亚迪一员工泄露华为机密 8505
- 9滴滴出行被投诉价格操纵,网约 8215
- 10顶风作案?金山WPS被指套娃 7230



