贾扬清:人工智能如何重塑传统软件行业?
编者按:本文来自微信公众号“OReillyAI”(ID:OReillyAI),作者 大数据文摘,编译 effy。36氪经授权转载。

特别感谢大数据文摘字幕组
编译:effy
本文基于Caffe的创始人、TensorFlow核心作者之一贾扬清在O'Reilly和Intel共同举办的AI Conference旧金山站所做的演讲《在AI时代重新思考软件工程》,通过揭秘传统软件工程的痛点,他希望向各位分享自己对人工智能时代,软件工程行业发展的思考。
长期以来,我们一直把分辨某个物体、颜色、形状的能力想成理所当然。什么意思呢?比如,当小编提道“斩男色”的时候,相信很多小姐姐都心领神会,但是你如何给不知道这个颜色的ta,或者计算机描述/形容“斩男色”?
注:斩男色,传说涂上这个颜色的口红可以就能天下无敌,撩弟无数,斩获所有直男的心。
在图像识别和处理领域,传统的软件工程是通过设计规则(rules),也就是使用硬编码来描述物体特征,来研究计算机视觉的问题。在深度学习之前,方向梯度直方图(histogram of gradients 简称HOG)火遍了大江南北。
什么是HOG?简单的说,HOG试图在图像的局部收集统计数据,或者可以理解为,它试图找到物体各个方向上的边界。比如,当你认真仔细看箭头下的图,(希望)你可以看出类似汽车的物体轮廓。
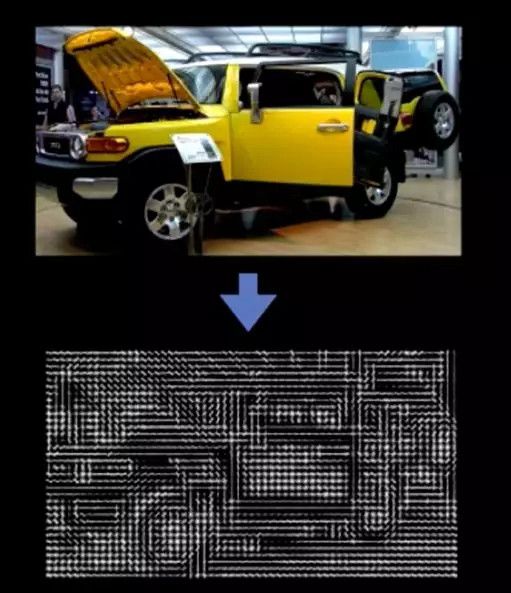
是不是仿佛回到了小时候体检看色盲卡?再来一张,这张是不是好多了?

因此,传统软件工程需要告诉电脑,规则是什么,或者特征是什么,并一步一步‘告诉’电脑该怎么做。可想而知,这种设计本身限制了计算机视觉的进一步发展。
从逻辑编程到自调适模型:从授之以鱼到授之以data
传统图片识别技术错误率在26%停滞不前,急坏了众多科学家、学者、研究人员。

这时,一位名叫Alex Krizhevsky的小哥哥,提出用一种更抽象的方式写模块,设计出了我们今天称为‘卷积神经网络‘的模型。并用大量的数据构建和训练它,实现了图像识别从传统的逻辑编程到建模的转变。

这种方法的效果惊天地泣鬼神,和传统图片识别技术相比,在准确性方面实现了飞越。AlexNet在2012年ImageNet中以15%的错误率取得前5的好成绩。
AlexNet由5个卷积层和3个全连接层,650,000个神经元以及60,000,000个参数构成。其中,卷积层扮演着抽象和提取特征的角色。

传统图像识别的方法,是将人为指定的、通过HOG提取出来的特征再放入分类器中,进行识别。而AlexNet实现了通过卷积层自主学习图片特征,并通过全连接层输出概率,确定分类的‘一条龙’服务。真的非常优秀了!
reference:http://www.image-net.org/challenges/LSVRC/2012/supervision.pdf
有意思的是,AlexNet还有生物后端的支持。研究发现,在我们的视觉皮层中,神经元会进行分层推断。信息从一层传递到下一层,再到下一层,从而让大脑提取越来越复杂的信息。
数据金矿
传统的方式是如何编写软件呢?我们编写软件时,会把源代码放入编译器中,编译器会将源代码转换成计算机能解读、运行的低阶机器语言。
而在人工智能领域,我们写的程序或者说模型已经和传统软件工程编译不同了。它不再是一组逻辑,而是会根据不同的训练数据和目标数据,得到不同的程序和模型。这些模型可以推导出一个通用的规则,然后使用大量的数据和计算来得到精确的结果。
举个例子,对于大约有一百二十万张图片的数据集来说,传统的方式处理这些编译的一个挑战是,它需要进行大约百万万亿次的计算(1 exaflop)来训练一个图像网络模型。
这是什么概念呢?如果让每个伦敦人每秒都做一个浮点运算的话,需要大约四千年的时间来训练这个模型。
其实我们已经意识到,人工智能的计算在某种程度上是非常野蛮的。特别是在卷积神经网络,或者叠加的神经网络,我们需要做大量的浮点运算(float operations)。
因此,在几年前,我们就开始建立和研发更高效的硬件。而且,我们还建立起了数据中心、规模集群或环境(scale clusters or environment)来进行计算。

与此同时,我们还看到了科学计算算法的回归,比如那些传统的用来预测天气的方法。
这都推动了软件设计的发展,现在我们不再使用代码进行编译,而是用代码和数据放在一个计算阶段(compute phase),或者我们也可以称其为现代版的代码编译。
当然,引用一句谚语:巧妇难为无米之炊。数据已经成为了人工智能生态系统中一个非常重要的部分。
互联网时代,大量的数据产生并充斥着我们的生活。那么面对如同大量的金矿一般的数据,我们真的能从中开采出黄金吗?或者我们的模型可以处理如此大量的数据么?
在Facebook,有一群非常优秀的小伙伴尝试回答这个问题。他们通过在网上分享大量的公共图片,和相关的信息,比如标签,来训练模型找出这些图像中有哪些东西。
随着这个项目的训练数据不断增加,最后达到大约四十五亿张图片,模型的质量和准确率也随之上升。也就是说,只要有更多的数据,就能带给我们更多更好更高质量的模型。
在这些领域中,我们看到的是用数据驱动的方法,代替硬编码或者说传统软件工程的方案。我们要做的只是提供大量的数据,然后在没有太多人工干预的情况下,就能得到理想的模型。完美!
算力呢?
人工智能时代的软件工程逐渐形成三个关键部分的良性循环:我们设计的模型可以从大量的数据中获取信息,利用我们现在拥有的巨大的计算能力,或者说更好的算法,开启智能之门。
大量数据的涌入,使我们能够为这些复杂模型的培训提供燃料。硬件的开发,使我们能够获得更多的计算资源,并且使我们能够在几天,几小时甚至几秒内完成这样的任务。
而随着硬件和计算机技术的发展,现在我们能够将这些模型部署到各种设备上。以前,我们的手机就是手机。今天,我们的手机不止是一部电话,还是一个私人助理,一台照相机和一种连接到智能世界的方式。
未来已来? or还未来?
有时我会想,我们还需要做些什么呢?好像已经全部做完了呀。难道不是么?人工智能渐渐变得常见并被大家了解和认识,我们已经有了很多高大上的模型和厉害的硬件设备,但是我们仍处于一个非常原始的阶段。
当我们试图管理实验的模型,我们有时会使用一些非常古老的手工方法,比如说excel表格。现在,在传统的软件工程中有更好的方法,比如,持续集成(continuous integration)。
我们知道当我们在写软件的时候,有复杂的系统来进行版本控制(version control),以确保代码的测试和质控。而当我们的项目考虑使用表格来管理我们的实验时,这些问题并没有出现。
所以问题来了,我们如何做到现代化的版本控制和现代的SDK和现代的持续集成呢?对于AI系统,这变得非常困难。不仅仅因为算法在改变,数据每天都在变化。而反过来,这些又改变和影响了将要部署的模型和即将出现的新硬件。
这三个因素会相互作用,并交织在一起难舍难分。因此,现在的软件工程不仅仅只是停留在代码层面了,它还需要处理数据和计算资源,从而保证结果的准确性,并确保我们能够对这些软件和系统有效管理。
这是一个开放的问题,因为我们还需要做很多工作,才能让AI继续发展下去。让我开心和激动的是,越来越多的人对AI感兴趣和加入。现在越来越多的学术论文在引用卷积神经网络,数量呈现指数级的增长,这和摩尔定律非常相似。于我个人而言,我非常期待看到人工智能的进步和更多的应用,帮助我们的社会的推进和提升。
相关推荐
贾扬清:人工智能如何重塑传统软件行业?
确认!贾扬清加盟阿里,任技术副总裁
贾扬清出任阿里巴巴开源技术委员会负责人
贾扬清从Facebook跳到“大牛收割机”阿里?
加盟阿里!贾扬清被曝从Facebook离职,任阿里硅谷研究院VP
我对人工智能方向的一点浅见
对话达摩院科学家:阿里人工智能这五年
大西洋月刊: 人工智能将如何重新重塑人类社会秩序
新基建如何重塑新型供应链?
沣扬资本杨希:复盘「映翰通」投资逻辑,解析物联网企业成长路径
网址: 贾扬清:人工智能如何重塑传统软件行业? http://www.xishuta.com/newsview5402.html
推荐科技快讯






- 1问界商标转让释放信号:赛力斯 95178
- 2人类唯一的出路:变成人工智能 20885
- 3报告:抖音海外版下载量突破1 20771
- 4移动办公如何高效?谷歌研究了 20054
- 5人类唯一的出路: 变成人工智 20036
- 62023年起,银行存取款迎来 10307
- 7网传比亚迪一员工泄露华为机密 8456
- 8五一来了,大数据杀熟又想来, 8338
- 9滴滴出行被投诉价格操纵,网约 7960
- 10顶风作案?金山WPS被指套娃 7213



