斯坦福等新研究:随意输入文本,改变视频人物对白,逼真到让作者害怕
编者按:本文来自微信公众号“量子位”(ID:QbitAI),作者 栗子、安妮,36氪经授权发布。原题目《找不出破绽!斯坦福等新研究:随意输入文本,改变视频人物对白,逼真到让作者害怕》
细思极恐的事情还是来了。
斯坦福和普林斯顿大学等最新研究:给定任意文本,就能随意改变一段视频里人物说的话。
并且,改动关键词后人物口型还能对得奇准无比,丝毫看不出篡改的痕迹,就像下面这样:

苹果今日收盘价91块4,改成82块2你也看不出来。
让新垣结衣向你表白,让石原里美大声喊出你的名字,甚至随便根据某个人的视频伪造个人陈述……现在都不在话下。

手握这项技术,在视频中让你怎么说你就怎么说,让你说什么你就得说什么,谁也看不出来这是假的。
有视频有真相?现在已经彻底过去了。
可能因为技术过于强大真是,研究人员还在项目主页上特意声明,这项技术一旦被滥用会造成可怕的后果,公布技术只是用于向公众科普,还呼吁相关部门建立相关法律……
这项研究的论文中选了计算机图形学顶会SIGGRAPH 2019。
来看全部效果展示↓↓↓
天衣无缝P视频
这个技术可以完成对视频多种类型的篡改。
功能1:改变人物台词
改变视频里的关键词,用假信息替换真内容,后果不要太可怕。
开头展示的视频就是改动后的效果。
功能2:改变人物嗓音
就算用合成的嗓音改造视频主角,也可以把人物口型调的宛如原生。

功能3:随意删除信息
即使你删掉视频中的部分关键词,也可以保持语音和图像的连贯。

有些话你说了么?你觉得说了,但看起来就是没说~
功能4:扩充视频背景
AI将视频里没有拍到的内容进行补充,窥一斑而见全豹:

功能5:连贯视频
此外,这项技术还能把磕磕巴巴的演讲/对话等视频,拆开后重新拼接,变成流畅画面。
结巴的救星、镜头恐惧患者的福音就是它了。
研究人员进行了不同维度的测评,发现这项技术的效果在同类产品中领先了不少。
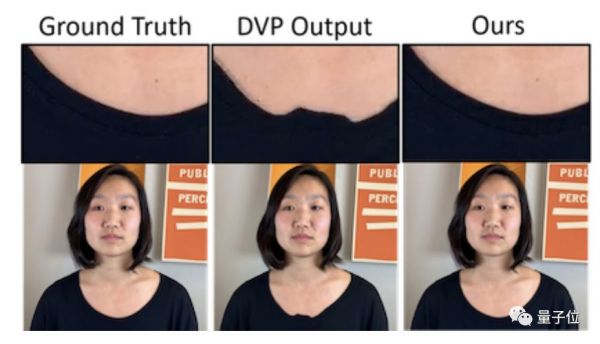
将此方法与深度视频人像(Deep Video Portraits,DVP)方法输出的人物渲染图像相比,新技术终于看起来不那么诡异了。
比如牙齿的合成效果:

比如衣服细节的合成效果:
与传统删除视频场景的MorphCut技术对比,MorphCut在第2、3、4帧的场景删除任务中失败了,而新技术可以成功切除:

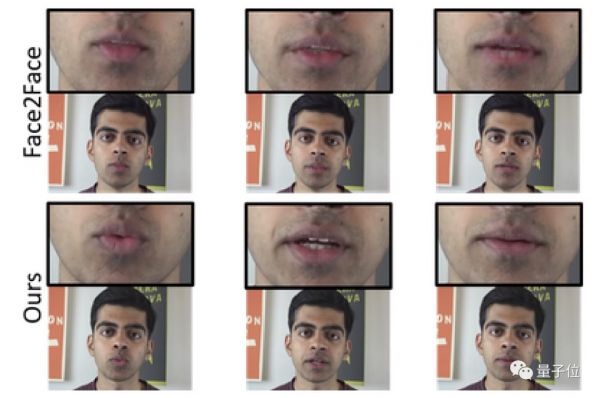
与Face2Face的面部改造技术相比,新技术避免了画面中出现的“鬼影”,合成画面也更加高清、稳定。
最后,研究人员还邀请了138位志愿者,来评估这种方法的真实性如何。
这些志愿者去判别“这个视频是不是真实”,如果同意真实则给5分,完全确信是假的就给1分,结果显示,这项技术在很多时候,已经让丧失了对视频真假的准确判断。

AI对口型
自动合成某个人的语音,已经有许多算法可以做到。这里,团队使用了原本视频主角的录音,而在不需要原声的部分,用了Mac自带的语音合成工具。暂不赘述。
这项研究最闪亮的部分,是流畅自然的“对口型”。
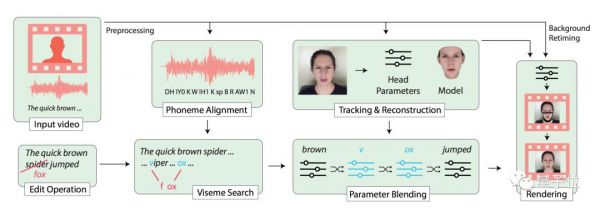
左手拿着视频,右手拿着文本,团队使用了五步法:
第一步:视频和文本要对齐
这里需要的是非常细致的对齐,精确到音位(Phoneme) 。
音位是什么?那是人类语言里能够区分语义的最小声音单位,分成元音和辅音。
找到特定的元音辅音,就能组成你要的单词,或者句子。
每种音位,又有各自对应的口型。所以在对口型任务里,视频和文本之间的精准对齐很有必要。
团队用的对齐工具叫P2FA:除了分辨出各种音位,还会把每个音位开始和停止的时间标记出来。
当然,如果手头数据只有视频没有文本的话,也可以用自动语音转录工具来生成文本,这类应用已经很常见了。
第二步:3D人脸追踪和重构
要为视频的每一帧,注册一个3D参数人脸模型 (3D Parametric Face Model) 。
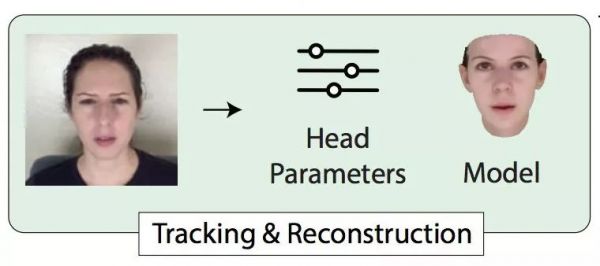
模型里的各种参数,会在后面的步骤中混合 (Blending) ,发生奇妙的反应:
比如,用某一帧的面部表情,搭配另一帧的头部姿势/朝向,组成新的一帧。
为了获得3D参数模型,团队从前辈的研究里借鉴了单目的、基于模型的人脸重构算法 (Monocular Model-Based Face Reconstruction) 。
这类算法,可以把头部姿势参数化,把脸部几何参数化,还有脸部的反射率、表情,以及场景中的光线,都可以参数化。
于是,视频的每一帧都获得了257个参数的向量。
第三步:唇形搜索
刚才的精细对齐,现在派上用场了。
就像上文提到的,每种音位对应了各自的唇形。但不同音位也可以有相似的唇形,可以通用。
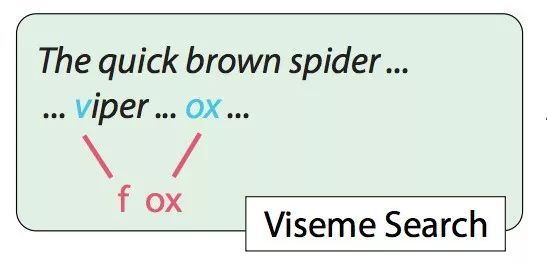
比如,想把蜘蛛 (Spider) 改成狐狸 (Fox) ,原本需要“f”的唇形和“ox”的唇形。
不过,“v”和“f”从视觉上看并没有太大差别。如果,视频里讲过毒蛇 (Viper) ,只要把“v”的唇形提取出来,和“ox”的唇形拼到一起,也能组成“fox”的动作。
根据文本,可以从视频里面,把需要拼接的片段,从视频里面抽出来。
第四步:重新定时,参数混合
可四下提取出来的片段,还不能直接拼到一起。有两个重要的问题需要解决:
一是,音位视频里提取的音位,可能动作满足要求,但时长就不一定跟新台词吻合了。
二是,两个需要连在一起的片段,可能在原始视频里相距很远,说话人头部的位置、姿势都会发生变化,直接拼起来就会不连贯了 (下图右) 。

想生成连贯自然的视频,前面做好的3D人脸参数模型,就是这里的大招:
把头部姿势、面部表情、反射率、场景光线等等参数,都放在一个参数空间里面去混合 (Blend) 。
这个过程,包括给各个片段重新设定时长,也包括把头部动作变连贯。
除此之外,为了避免摄像头移位带来的背景变化,还需要选择一个背景序列。
这样,一个流畅的背景视频就做好了。
之所以叫“背景视频”,是因为在这个步骤里,嘴部动作被提前抠掉了,所以还有下一步。
第五步,脸部渲染
最后一步,训练一个循环网络 (RNN) 作为GAN的生成器,加上一个时间空间判别器:
让GAN把嘴部动作 (下半张脸) 和背景视频,无缝混合到一起。

到这里,跟着新台词对口型的视频,就愉快地生成了。
作者介绍
这篇研究的作者共有10人,都带着闪闪发光的履历。
他们来自较为知名的机构,包括斯坦福大学的Ohad Fried、Michael Zollhöfer、Maneesh Agrawala,普林斯顿大学的dam Finkelstein、Kyle Genova,马克斯·普朗克信息学研究所的Ayush Tewari、 Christian Theobalt和Adobe的Eli Shechtman、Zeyu Jin,此外还有DAN B GOLDMAN。
一作Ohad Fried为现在为斯坦福大学的博士后,与印度裔教授Maneesh Agrawala合作,主要研究计算机图形学、计算机视觉和人机交互。
Fried小哥本科和研究生毕业于希伯来大学,博士去普林斯顿进行深造,随后在谷歌、Adobe等实习过。
二作Ayush Tewari目前是马克斯·普朗克信息学研究所博士三年级在读,此前有多篇论文被顶会收录,包括一篇ECCV 18、两篇CVPR 18和一篇ICCV 17。
作者团队中还有一位华裔成员,是来自Adobe的研究科学家ZEYU JIN。

ZEYU JIN的个人主页显示, ZEYU主要研究方向是语音和音乐合成,视频中用到的音频处理软件Adobe Project VoCo就是ZEYU主导的项目。

技术“太吓人”
最后,在这个项目的主页地址,里面还有研究人员的专门声明:
这个基于文本的视频编辑方法,为更好的电影后期编辑打下了基础。
原本,电影里的对话要重新定时或者修改,需要繁琐的手动工作。但现在AI可以依靠文本,更好地调整视频里的图像和音频。
除了影视作品,技术也可以用于教学视频,或者给儿童讲故事的应用。
但这种技术,也有被滥用的隐患。行为不良的人可能用这样的方法来来伪造个人陈述,诽谤知名人士。
所以,视频中要有明显证据表明它是合成的,这一点至关重要。比如在视频里直接陈述,或者加入水印标明这一点。
并且,技术社区应该继续发开发识别假视频的技术,在减少滥用的同时,为有创造性的合法使用提供空间。
最后,我们认为有必要进行强有力的公开讨论,建立适当的法规,平衡这类工具的滥用风险与创造力的重要性。
他们强调,这项技术一旦被滥用会造成可怕的后果。
到底多可怕?不光颠覆一行一业,也对现有的伦理和法律提出新挑战,随便举几例:
在deepfake刚刚兴起的时候,就有不少人评论称,娱乐行业,靠脸吃饭的流量小生,使用好这项技术,结合换脸AI deepfake和语音合成,真的就能靠脸吃饭。
台词功力?表情演技?都不重要,甚至有个替身方便换脸就好。
现在,利用这一技术篡改的人物口型几乎一般人难辨真假,如果有人借新闻主播之口制造一段假新闻,就可能引起大众的恐慌。
在安防监控领域,视频里的人说了什么、做了什么,真的就可信吗?这项技术可怖不在于让视频中的人和事“从有变无”,而是有能力“无中生有”。
AI技术进展太快,现有伦理道德和法律法规,是时候重新考量了。
你说呢?
在量子位公众号回复“无破绽”,可查看完整视频展示。
最后,附上论文传送门
论文Text-based Editing of Talking-head Video地址:
https://arxiv.org/abs/1906.01524
— 完 —
相关推荐
斯坦福等新研究:随意输入文本,改变视频人物对白,逼真到让作者害怕
欧洲首例AI诈骗:用CEO声音骗走22万,逼真语音合成只需1分钟录音
英伟达发布最强图像生成器StyleGAN2,生成图像逼真到吓人
Deepfake再现进阶版:输入文字即可修改口型语音
别操心售票员的工作了,斯坦福最新研究:分析师等高薪高学历职位受AI影响最大
脑机接口利器:从脑波到文本,只需要一个机器翻译模型
如何让虚拟人物动起来?「DeepMotionBrain」开发了真人驱动+自主生成的运动智能
爱因斯坦70年前就预言了新冠爆发?这段AI复活视频火爆Reddit
让科技回归人性,李飞飞宣布成立斯坦福“以人为本 AI 研究院”
Adobe的P图新科技:就算丢了半个头,也能逼真复原
网址: 斯坦福等新研究:随意输入文本,改变视频人物对白,逼真到让作者害怕 http://www.xishuta.com/newsview5876.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95228
- 2人类唯一的出路:变成人工智能 21183
- 3报告:抖音海外版下载量突破1 21148
- 4移动办公如何高效?谷歌研究了 20339
- 5人类唯一的出路: 变成人工智 20338
- 62023年起,银行存取款迎来 10336
- 7五一来了,大数据杀熟又想来, 8596
- 8网传比亚迪一员工泄露华为机密 8505
- 9滴滴出行被投诉价格操纵,网约 8215
- 10顶风作案?金山WPS被指套娃 7230



