芯片巨头,都想“干掉”工程师
本文来自微信公众号:半导体行业观察 (ID:icbank),作者:杜芹DQ,题图来自:视觉中国
最近人工智能因为在ChatGPT等自然语言处理器方面的惊人能力而受到更多关注,但除此之外,AI还在其他多个领域慢慢产生影响,譬如将AI用于芯片设计。由于芯片设计复杂度和精度要求的不断提高,传统设计方法已经难以满足需求。人工智能技术的快速发展为芯片设计带来了新的可能性。现在越来越多的芯片产业链的厂商开始探索借助AI的方法来帮助芯片设计,那么芯片工程师该何去何从?
本文将介绍一些芯片巨头利用AI技术在芯片布局中的突破,AI可以在芯片布局中发挥重要作用的原因在于其优异的图像识别能力。
芯片布局越来越耗时
在超大规模集成电路(VLSI)中,布局(Layout)是芯片设计流程中的重要步骤之一。芯片的布局决定了物理布局中标准单元的位置,所有不同的子系统都必须以特定的方式布局,还要使信号和数据以理想的速率在这些区域之间传播。传统上,这项工作往往由工程师手工来完成,芯片工程师们通常会花费数周或数月的时间来不断改进和优化他们的设计,试图找到标准单元的最佳配置。
分析布局(Analytical placement)是目前超大规模集成电路布局的最先进技术,它可以帮助设计师在最小的芯片面积内实现高性能、低功耗和高可靠性的电路设计。分析布局通常包括三个步骤:全局布局(Global Placement,GP)、合理化布局(Legalization,LG)和详细布局(Detailed Placement,DP)。
全局布局(GP)是指将电路元件在芯片上放置的初始阶段,其目的是在不考虑细节的情况下,使得所有元件的位置相对合理,以便后续布局步骤进行。在全局布局中,采用各种算法和技术来解决面积、功耗、时序和连通性等方面的问题。在这三个步骤中,全局布局是分析布局中最耗时的部分。
合理化布局(LG)是指对全局布局的元件位置进行微调,以满足一些硬性的约束条件,例如电路元件之间的最小距离、与芯片边缘的距离、相邻元件的方向等。合理化布局的目的是确保电路元件的位置符合设计规范,并且在不违反设计限制的情况下尽可能接近全局布局的解。
详细布局(DP)是指对元件位置进行更加精细的调整,以进一步提高电路性能和减少功耗。详细布局通常涉及更为复杂的算法和技术,例如网格化布局、全局优化和局部优化等。
但是现在随着芯片的复杂度和密集度不断攀升,一个先进的芯片集成了数百亿个甚至数千亿个晶体管,例如苹果的M1 Ultra中集成了1140亿个晶体管,AMD的instinct MI300加速器芯片中集成了1460亿个晶体管,以及由此产生的功率、性能和面积 (PPA) 之间的现代复杂关系,使得芯片的布局愈发费时费力。
为了加快和优化IC设计流程,行业的芯片厂商正在探索利用深度学习方法来比人类更快、更高效地设计芯片。通过使用AI技术,芯片设计师可以将设计要求输入到计算机中,计算机可以自动识别和处理图像,并根据指定的规则和限制进行布局。AI技术可以更快、更准确地生成芯片布局,同时可以避免设计师在重复和繁琐的任务中的错误。许多公司(包括科技行业的一些最大公司)现在都在投资AI 工具来完成一些繁重的工作。
谷歌用AI进行芯片布局
早在2021年9月,谷歌在《自然》杂志上发表了一篇文章《一种用于快速芯片设计的图形放置方法》,声称利用机器学习软件可以比人类更快地设计出更好的芯片,谷歌表示,它正在使用这款人工智能软件设计其自主研发的TPU芯片。
谷歌在文章中写道:“尽管经过了50年的研究,芯片布局仍然无法实现自动化,物理设计工程师需要数月的艰苦努力才能制作出可制造的布局。在不到6小时的时间里,我们的方法自动生成的芯片布局在所有关键指标上都优于或可与人类绘制的设计图相媲美。”
谷歌将芯片布局规划看作为一个强化学习(RL)问题,并开发了一个基于边缘的图卷积神经网络架构,能够学习芯片的丰富和可转移表示。具体的评估工作流程见图1。该流程允许每个方法访问相同的聚类网络列表超图,在所有方法中(尽可能地)使用相同的超参数。每种方法完成放置后(包括RePlAce的合法步骤),将宏捕捉到电网格中,冻结宏位置,并使用商业EDA工具放置标准单元并报告最终结果。

图1:谷歌利用强化学习产生结果的评估工作流程(来源:谷歌)
将谷歌的方法与最先进的方法(RePlAce14)以及使用行业标准EDA工具的手动放置进行比较。具体比较的指标有花费的时间、总的面积、功耗、线长等等,对于该表中的所有指标,越低越好。可以看出,谷歌的强化学习方法均优于其他两种。
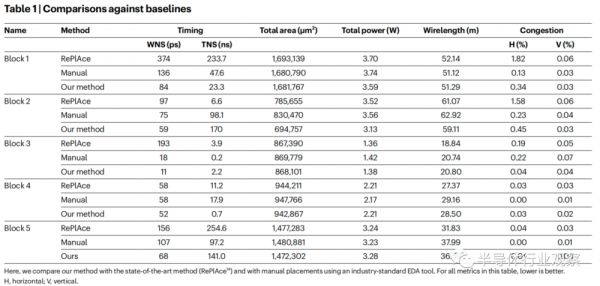
(来源:谷歌)
谷歌的研究团队表示,随着人工智能接触到更多数量和种类的芯片,它可以通过不断地培训学习,会更快更好地为新芯片块生成优化布局,虽然我们主要在谷歌加速器芯片 (TPU) 上生成优化的布局,但我们的方法适用于任何类型ASIC芯片。
英伟达DREAMPlace商业化推进有望
在加速布局方面,现有的并行化工作主要是使用分区的多线程CPU。随着线程数量的增加,速度在5倍左右就饱和了,而且典型的质量下降2%~6%。英伟达的工程师探索了利用GPU来加速分析位置布局。
传统的分析布局引擎开发需要花费大量的精力用C++构建整个软件堆栈,因此,由于开发成本的问题,设计和验证新布局算法的门槛非常高。于是,英伟达利用深度学习工具包PyTorch,通过少量的软件开发工作,开发了一个新的具有GPU加速的开源布局引擎——DREAMPlace,这是一个比较出名的开源布局器。它通过高效的GPU实现的关键内核的分析布局,如电线长度和密度计算等。
该框架是用Python开发的,PyTorch用于优化程序和API, C++ /CUDA用于低级操作人员。DREAMPlace程序运行在基于Volta架构的40核Intel E5-2698 v4 @2.20GHz和一个NVIDIA Tesla V100 GPU的Linux服务器上,它通过抛出分析布局问题来训练神经网络。
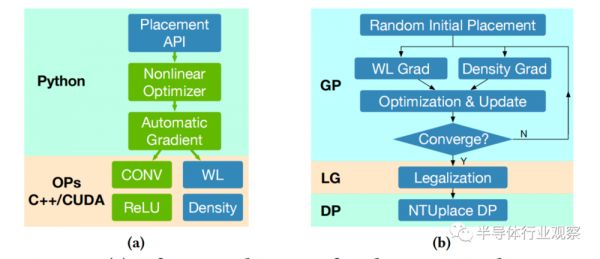
DREAMPlace的软件架构如图a所示,整体布局流程图如下图b所示(图源:英伟达)
在与最先进的全球布局算法家族ePlace/RePlAce的对比中,DREAMPlace在全局布局和合理化方面实现了30倍以上的加速,且没有理论和工业基准的质量下降。更具体地来说,它能使100万个单元的设计在1分钟内就能完成。英伟达探索了用于向前和向后传播的低级操作符的不同实现(前向传播来计算目标,后向传播来计算梯度),以提高整体效率。
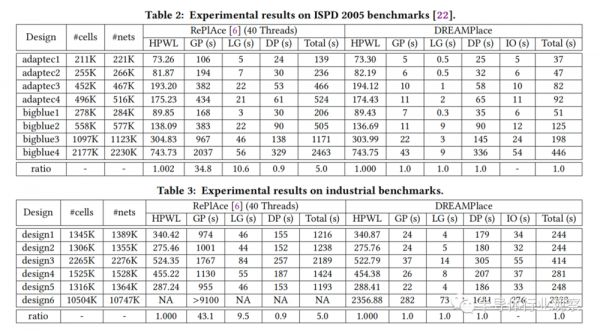
上表2和表3分别显示了ISPD 2005和工业基准的HPWL和运行时细节。表2显示,在几乎相同的解决方案质量(平均0.2%的差异)下,与RePlAce的40个线程相比,DREAMPlace在GP的两个基准套件上能够实现35倍和43倍的加速。
此外,DREAMPlace是高度可扩展的,可以通过简单地编写高级编程语言(如Python)来合并新的算法/求解器和新的目标,其工业设计可达1000万个单元。英伟达计划进一步研究单元膨胀的可路由性和时间优化的净加权,以及GPU加速的详细布局。它还可以扩展到利用多GPU平台来进一步加速。由于DREAMPlace分离了高级算法设计符号和低级加速工作,因此它显著降低了开发和维护开销。英伟达的这项工作将为重新审视经典的EDA问题开辟新的方向。
但是,由于其对线长和密度的关注有限,DREAMPlace的布局质量无法与商业工具相比,这使得它很难适用于工业设计流程。为了解决这一问题,英伟达科学家近日的一项研究文章中提出了一种新方法——DREAM-GAN,这是一种使用生成对抗学习推进 DREAMPlace的布局优化框架。DREAM-GAN的最大优势在于,它使DREAMPlace能够朝着工具验证(和优化)的方向优化底层位置,而无需明确了解商业工具的黑盒算法。DREAMPlace通过优化鉴别器的输出,提高了其商业化的位置。

DREAM-GAN
实验表明DREAM GAN不仅在放置阶段立即改善了主要的PPA指标,而且还证明了这些改进一直持续到路由后阶段,在路由后阶段,无线长度提高了8.3%,总功率提高了7.4%。

DREAMPlace与DREAM-GAN在各主要PD阶段的详细PPA比较结果。在这项工作中,我们使用Synopsys ICC2执行整个PD,除了全局放置由DREAMPlace(左列)或DREAM-GAN(右列)执行。在所有商业和OpenCore基准测试中,两种方法在全局布局上的运行时差异不超过2分钟。
此外,Nvidia科学家近日在国际物理设计研讨会上展示了AutoDMP的研究论文,AutoDMP 是使用 TILOS AI 研究所的宏布局基准进行评估的,其中包括带有大量宏的CPU和AI加速器设计。为了进行评估,AutoDMP与商业EDA工具集成在一起,如下图所示。
首先,在NVIDIA DGX系统上运行多目标贝叶斯优化。该系统有4个A100 GPU,每个都配备了80Gb的HBM内存。生成16个并行进程以采样参数并在优化期间运行DREAMPlace。然后,从Pareto前端选择的宏位置被提供给运行在CPU服务器上的TILOS提供的EDA Flow。在大多数设计中,AutoDMP的PPA指标结果——线长、功率、最差负裕量 (WNS)和总负裕量 (TNS)——等于或优于商业流程。
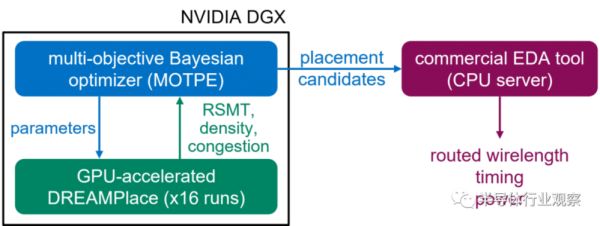
AutoDMP的计算流程
写在最后
技术的发展是把“双刃剑”。一方面,人工智能可以通过学习已有的芯片设计数据来发现规律,并通过分析数据,提供更快速、更准确的芯片设计方案。同时,人工智能技术还可以提高芯片设计的效率,缩短开发时间,减少成本。
但另一方面,随着AI技术的不断发展和成熟,一些没有那么有创意的低级、平凡的工作可能会被人工智能取代。正如上文所述,在芯片布局这项工作中,过往主要是靠人工来完成,虽然目前的AI技术还有一些局限性,但随着技术的不断改进和突破,将或多或少的减少芯片设计过程中对手动方面的需求,虽然这提高了整体效率,但有可能会端掉部分工程师的饭碗。
不过我们也不必焦虑,回看四次工业革命,每一次工业革命都有一些工作、工人或工程师被取代,但是也会创造出新型工程师,最终提升了我们的生产力。回归到芯片设计这一行业,AI的介入不会完全取代人工,因为就实际情况而言,行业仍需要能够在设计过程中准确验证和利用 AI 工具和算法的个人。这一发展对于人才的深远影响是,提高IC设计人员在行业中的价值,使他们腾出更多的时间来专注于更复杂和更具创造性的设计方面,并最终生产出更好的产品。
利用人工智能技术来帮助设计和制造芯片已经成为大势所趋。不仅是谷歌和英伟达,EDA软件工具提供商Synopsys、西门子和Cadence等公司也在其最新工具中使用了AI技术,三星将AI技术引入芯片制造等等。这些AI/ML技术方法的引入,将为推进超大规模集成电路布局提供新的方向,也将成为摩尔定律再运行几年的潜在途径之一。
参考资料
【1】《A graph placement methodology for fast chip design》
【2】《DREAMPlace: Deep Learning Toolkit-Enabled GPU Acceleration for Modern VLSI Placement》
【3】《DREAM-GAN: Advancing DREAMPlace towards Commercial-Quality using Generative Adversarial Learning》
本文来自微信公众号:半导体行业观察 (ID:icbank),作者:杜芹DQ
相关推荐
芯片巨头,都想“干掉”工程师
芯片工程师的薪水,没有股价那么高
中国芯片工程师的黄金时代
中国芯片工程师,迎来了黄金时代?
芯片抢人大战:涨薪50%起,工程师比老板贵
iPhone 12能买了?听说“刘海”要被干掉
全球芯片缺货,巨头们纷纷下注以色列
用AI设计芯片,谷歌会"干"掉工程师吗?
芯片短缺催生创业热潮,去年芯片行业风投超120亿美元
为啥科技公司都想养只机器狗?
网址: 芯片巨头,都想“干掉”工程师 http://www.xishuta.com/newsview70447.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95228
- 2人类唯一的出路:变成人工智能 21183
- 3报告:抖音海外版下载量突破1 21148
- 4移动办公如何高效?谷歌研究了 20339
- 5人类唯一的出路: 变成人工智 20338
- 62023年起,银行存取款迎来 10336
- 7五一来了,大数据杀熟又想来, 8596
- 8网传比亚迪一员工泄露华为机密 8505
- 9滴滴出行被投诉价格操纵,网约 8215
- 10顶风作案?金山WPS被指套娃 7230



