“假声音”也来了,手把手教你造一只柯南的蝴蝶结变声器
编者按:本文来自微信公众号“大数据文摘”(ID:BigDataDigest),作者 蒋宝尚、魏子敏,36氪经授权发布。
最近,一只“总统洋葱新闻”在Youtube和Reddit上引发了一波讨论。
视频中,特朗普用它一贯懒散的声音播报了一组耐人寻味的新闻——“数据雨“:
民主党人把太多数据存在运上,冷却后成为液体,最后通过降雨落下来,对地球生态造成巨大伤害。想要避免这种致命液体,你需要躲在屋里,不要出门。

视频地址:https://www.youtube.com/watch?v=jzKlTKsHeus
虽然内容荒唐,但整个视频中的声音效果非常真实,以至于不少网友在捧腹大笑的同时也开始调侃,“是不是很快就能接到特朗普给我打的广告电话了。”
再加上近期,“假脸”技术大肆盛行,与之配套的“假声音”上线后,更能生成无缝衔接的假视频,让假戏做足,真假难辨。

靠换脸技术”出演”《射雕英雄传》的杨幂
一键生成“假声音”
关于变音技术,江湖上确实流传了几种,不过加持了机器学习和深度学习,这种技术不再是简单的语音滤波器。
跟”一键变脸“的deepfake软件一样,研究者们也开发了让不懂技术的同学直接易上手的变声软件。
刚刚听到的这个声音就来自这样一个网站Modulate.ai。麻省理工科技评论的资深编辑Will Knight用其轻易就合成了不同的声音。
创建这个网站的三个小伙伴,有两个来自麻省理工,还有一个来自加州大学洛杉矶分校。对于游客,这个网站给出了几个适用的声音,对于想定制名人声音的用户,还得通过官网给出的联系方式联系他们。
据网站介绍,合成的声音是是采用神经网络训练来训练,具有低延迟性以及实时性。
文摘菌试了一把,在网站的提供的接口处录下声音,选择你想要的“性别”或者“名人”,网站会很快生成你想要的声音。
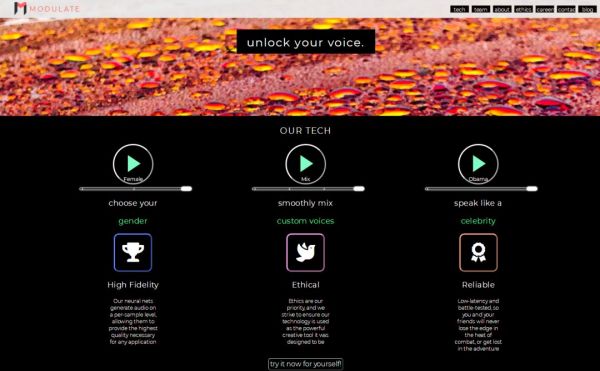
网站地址:https://modulate.ai/
此外,百度在18年的3月份曾经宣布,百度开发的新 AI 算法Deep Voice可以通过3.7秒钟的录音样本数据就能完美的克隆出一个人的声音。Deep Voice是百度AI研究院一个由深度神经网络构建的高质量语音转(TTS )系统。除了利用少量样本克隆声音外,系统还能将女性声音转变成男性,英式声音变成美式。
语音转语音的具体过程
声音的直接转换是比较复杂的,因为一个人的“声音”不仅是由声带定义,声带只是声音的频率,具体来说,还取决于口音和说话风格。另外,音高会受胸腔的物理特性等的影响。这些影响作用在不同的层面上,发音决定了单词和短语是如何在几秒钟或几十秒内被识别出来。
当开始合成语音时,技术人员主要会考虑三个因素。
首先是生物因素,这些因素人们难以自行改变。第二,构建声音认同概念,即任何在语言下明显表现出来的同一性。有了这个定义,就可以很好的建立语音识别模型。第三,建立独立于上下文处理语音片段的模型,这个模型的好处是它比神经网络中所要处理的序列模型要简单的多,并且可以有效的降低语音处理延迟。
总的来说,所要建立的系统是:把一个说话人的声音的频率分布(frequency profile)换成另一个声音的频率分布,同时保持他们讲话的其余属性不变。
所以,自然的将系统分为两个部分:1、语音识别 2、语音转换。这两个部分最主要的区别是,是从语音转换到文本,还是从文本转换到语音。如果这两个部分独立运行,那么整个系丢失“情感模仿”。
语音转文本和文本转语音同属一个极端的情况。语音转换必须使用媒介,由于系统只能给出语音,并且尝试在输出中再现输入的语句。
通过限制某时段通过系统的信息量,系统学习识别功能(identity function),这是系统的瓶颈。在从语音到文本到语音的情况下,瓶颈在于对输入的语音进行文本表示,因此系统必须进行一般性学习,才能根据文本生成可靠的语音。
从通过机器学习构建这样一个系统的角度来看,出现瓶颈自然有其的道理。机器学习,特别是深度学习,当被训练来完成一项特定的任务时,一直表现得非常好。但是瓶颈自动编码器没有接受过语音转换的训练,他们接受的是自动编码训练。
破解瓶颈的主要方法是调整信息瓶颈的带宽。例如文本中间表示,会丢失太多信息。文本可以使用情感标签或其他符号进行注释,但这些需要对监督数据着重进行手动注释。
具体的步骤:
首先尝试在两种不同的损失函数上训练说话人标识符( identifie):真实音频匹配扬声器配置文件和生成音频,以及真实音频匹配扬声器配置文件和真实音频的扬声器配置文件。使得说话人的标识符“寻找”说话人身份,否则它只能关注于检测生成的音频。在实践中,发现只有对两个损失函数中的第一个函数的训练才能起到同样的作用:说话人标识符首先学会区分真实的音频和生成的音频,然后随着生成器开始产生更高质量的输出,自然进化到使用说话人配置文件。
在神经网络的输入层对说话人标识符的大小设置了惩罚。惩罚的大小是一个可调整的参数,通过训练效果进步明显与否,可以判断最优参数。对于真实和假音频,我们最好的训练倾向于快速收敛0.55的交叉熵,然后在大多数训练过程中慢慢爬过0.6。
然后继续改进系统系结构,通过直接优化语音转换目标,通过一个新的说话人标识符,能够产生与目标声音紧密匹配的合成语音,同时保留了通常由瓶颈架构丢失的表达性。
AI合成大事件
通过AI技术合成图片以及视频早已不新鲜,要说最著名的合成案例可能就是下面这个。
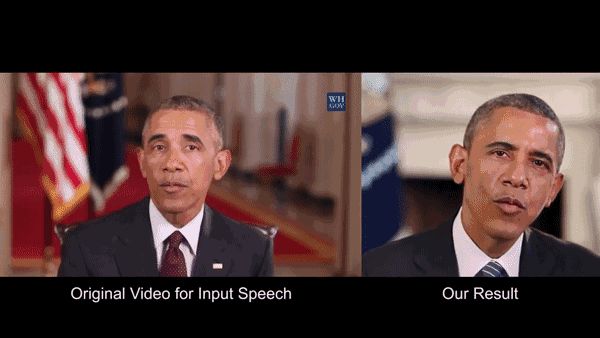
这项技术由华盛顿大学SUPASORN SUWAJANAKORN等三人共同发明,他们坦言,之所以选用奥巴马做研究范例,是因为他的高清视频资源获取非常容易,并且不受版权限制。
因此,研究小组用神经网络分析了数百万帧的视频,来确定奥巴马的面部表情如何变化。开口说话需要整个面部器官的协调,所以研究人员不仅分析了口型变化,还包括他的嘴唇、牙齿和下巴周围的皱纹,甚至还包括脖子与衣领。
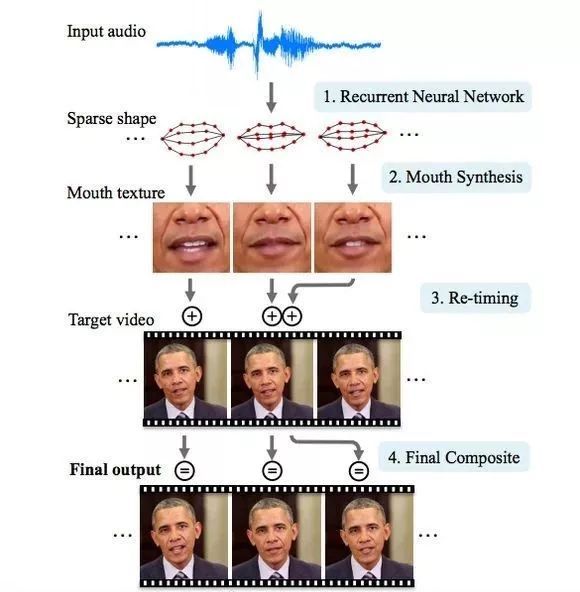
具体的操作过程是:研究人员采集了音频片段(原始音频文件),再把口型和新的音频文件剪辑匹配,再嫁接到新视频。
国内的科技公司也在这一领域各有千秋。拿导航用的语音来说,科大讯飞的董事长刘庆峰在2018世界机器人大会上表示,高德地图导航上面的林志玲、郭德纲的声音都是合成,其实都不是本人原音,而是由他们的机器来完成合成的,压根就不是本人录的。
相关推荐
“假声音”也来了,手把手教你造一只柯南的蝴蝶结变声器
欧洲首例AI诈骗:用CEO声音骗走22万,逼真语音合成只需1分钟录音
手把手教你烧光投资人的钱
在抖音听到梦碎的声音
视频滤镜太强大 用户:直播平台为何不强制关掉
当代骗子分两种:懂AI的和不懂的
AirPods还能无敌多久?“追着你跑的声音”来了
最前线 | iOS 14提前曝光:Apple Pay将支持支付宝,防丢器Air Tag也要来了
用牙齿听声音?「声佗医疗」自研牙骨传导听力系统
AI骗走173万:伪造老板声音要求转账,赃款几经易手,骗子无影无踪
网址: “假声音”也来了,手把手教你造一只柯南的蝴蝶结变声器 http://www.xishuta.com/newsview711.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95037
- 2人类唯一的出路:变成人工智能 19982
- 3报告:抖音海外版下载量突破1 19767
- 4移动办公如何高效?谷歌研究了 19209
- 5人类唯一的出路: 变成人工智 19079
- 62023年起,银行存取款迎来 10202
- 7网传比亚迪一员工泄露华为机密 8315
- 8五一来了,大数据杀熟又想来, 7549
- 9滴滴出行被投诉价格操纵,网约 7166
- 10顶风作案?金山WPS被指套娃 7146



