2万字复盘:OpenAI的技术底层逻辑
本文来自微信公众号:OneMoreAI(ID:OneMoreAI1956),作者:Kiwi,头图来源:视觉中国
自 ChatGPT 发布以来,AI 领域的技术、产品和创业生态几乎在以周为单位迭代。OpenAI 作为这次 AI 热潮的导火索和行业事实的领先者(且可能长期保持),对行业生态有广泛和深远的影响。
本文从 OpenAI 的 AGI 愿景出发,首先分析了在该愿景的驱动下 OpenAI 是如何一步步依据 Scale、Generative Model 两个重要技术判断形成了我们所能观察到的 LLM 发展路线,并对此技术路线的底层逻辑进行了分析;在对愿景和技术选型分析的基础上,报告将 OpenAI 的历史行为与此技术路线进行了拟合,尝试解释了许多让人困惑的历史行为,并更进一步对其未来的行为进行了推演;最后报告对基于大模型的生态和产业链的发展给出了自己的分析并提出了一些供大家思考的问题。
这是我们对 OpenAI 进行全面、系统、深度逆向工程后的产物,提供了一种从底层愿景出发来分析 OpenAI 历史行为和未来行动预测的独特视角,希望能够对国内正在从事大模型研究、开发、投资的工作者们带来帮助。
一、OpenAI 的 AGI 愿景和对 GPT 技术路径的坚持
1. 1 OpenAI 的 AGI 愿景
在开始分析前,我们将 OpenAI 不同时期对自己 AGI 目标的描述进行回顾:
“Our goal is to advance digital intelligence in the way that is most likely to benefit humanity as a whole, unconstrained by a need to generate financial return.”——2015年12月11日《Introducing OpenAI》
“Our mission is to ensure that artificial general intelligence—AI systems that are generally smarter than humans—benefits all of humanity.”——2023年2月14日《Planning for AGI and beyond》
第一个变化是增加了对 AGI 的描述,指明了 AGI 的智慧程度会高于人类智能。
第二个变化是由不以财务回报为目的改为了普惠人类。
AGI 的概念目前并没有已形成共识的精准定义。前者变化是 OpenAI 基于过去几年的探索给出的判断,其追求 AGI 的本质没有改变。后者则是 OpenAI 在更深入的技术探索后,进行了股权结构和商业化策略的调整,背后逻辑后续会详细展开。
总体而言,鉴于 OpenAI 的历史言论和行动保持高度一致性,我们有理由相信:OpenAI 一直并将继续以追求普惠的 AGI 为第一目标——这个假设是本文后续进行生态推演的基本前提。
1.2 OpenAI 过去 5 年展现的外界难以理解的GPT“信仰”
在 AGI 愿景下,我们看到 OpenAI 在过去 5 年坚定地选择了用 GPT(Generative Pre-trainning Transformer)架构持续加注 LLM(Large Language Model)的技术路径。这个期间 OpenAI 孤独且惊人的巨大投入,让外部觉得这是信仰的程度。但如果理解了 OpenAI 的技术选择本质回头看,我们会发现这其实是 OpenAI 在对技术的深刻洞见下的理性判断。
OpenAI 在发展上可大致分为三个阶段:
1.2.1 阶段一: AGI 实现路径探索(2015年11月~2017年6月)
这个时期的 OpenAI 走向 AGI 的技术路径并没有收敛,开展了包括 OpenAI Gym(Robotics),OpenAI Five(Dota2)和一系列 Generative Model(生成式模型)的项目探索。
值得注意的是,这些项目使用的是 Unsupervised Learning(无监督学习)或RL(Reinforcement Learning, 强化学习),都不需要标注数据,有较好的可拓展性。Unsupervised Learning 和 RL 在 OpenAI 成立之初是一个难以实践更难以 Scale(规模化)的算法路径,OpenAI 却似乎只关注这个工业上不成熟的技术路径并尝试 Scale 。
研究这期间 OpenAI 的文章和 Ilya Sutskever(OpenAI 首席科学家)的演讲,可以窥见 OpenAI 当两个重要的技术判断:
重要技术判断1:Scale
Ilya 此期间的所有演讲都强调了 Scale 的重要性。其实回溯 2012 年让 Ilya 等人一战成名的 AlexNet,其算法核心本质也是利用 GPU 的并行计算能力将神经网络 Scale 。将基础算法规模化的理念贯穿了 Ilya 近十年的研究。合理推测,正因为对 Scale 的追求,Ilya 和 OpenAI 才会如此强调 RL 和 Generative Model 的重要性。
举例来说,同样是在 2015 年前后打 Dota2,AlphaGo 选择了结合搜索技术的变形式 RL 来提高算法表现,而 OpenAI Five 选择了纯粹的 RL 上 Scale 的方法(期间发布的RL Agent 在后来也起到了巨大的作用)。
后来 2019 年 Rich Sutton 发布的知名文章《The Bitter Lesson》也指出:“纵观过去70年的AI发展历史,想办法利用更大规模的算力总是最高效的手段。”
也正是在算法 Scale 的理念下,OpenAI 极度注重算法的工程化和工程的算法思维,搭建了工程算法紧密配合的团队架构和计算基础设施。
重要技术判断2: Generative Model
在 OpenAI 2016 年 6 月的发文《Generative Model》中分析指出:“ OpenAI 的一个核心目标是理解世界(物理和虚拟),而 Generative Model(生成式模型)是达成这个目标的最高可能性路径。”
而在 2017 年 4 月发布 Unsupervised Sentiment Neuron 算法的文章《Learning to Generate Reviews and Discovering Sentiment》中指出,“真正好的预测与理解有关”,以及“仅仅被训练用于预测下一个字符之后,神经网络自动学会了分析情感” 。
这篇文章在当时没有受到太多关注甚至被 ICLR 2018 拒稿,但我们分析认为,这个研究成果对 OpenAI 后续的研究产生了深远的影响,也为下一阶段 OpenAI all-in GPT 路线打下了基础。
1.2.2 阶段二:技术路径收敛,探索GPT路径工程极限(2017年6月~2022年12月)
2017 年 Transformer 横空出世,Transformer 对 language model 的并行训练更友好,补齐了 OpenAI 需要的最后一环。自此,OpenAI 确立了以 GPT 架构的 LLM 为主要方向,逐渐将资源转移至 LLM,开启了 GPT 算法路径的工程极限探索之途。这个阶段 OpenAI 对于 GPT 路径的巨额押注在当时外界看来是不可思议的举动。
2018 年 6 月 OpenAI 发布 GPT-1,两个月后 Google 发布 BERT 。BERT 在下游理解类任务表现惊人,不仅高于 GPT-1(117M),且基本导致 NLP 上游任务研究意义的消失。
在整个 NLP 领域学者纷纷转向 BERT 研究时, OpenAI 进一步加码并于 2019 年 2 月推出 GPT-2(1.5B)。GPT-2 虽然在生成任务上表现惊艳,但是在理解类任务的表现上仍然全面落后于 BERT。
在这样的背景下,OpenAI 依然坚持 GPT 路线并且大幅度加大 Scale 速度,于 2020 年 5 月推出了 GPT-3(175B)。GPT-3 模型参数 175B(百倍于 GPT-2),训练数据量 500B Tokens( 50 倍于 GPT-2)。
GPT-3 直接导向了 OpenAI 股权架构的重构和商业化策略的转型。2019 年 3 月,OpenAI 由非盈利组织改组为有限盈利组织(所有股东 100x 盈利上限)。Sam Altman 在发文中指出“We’ll need to invest billions of dollars in upcoming years into large-scale cloud compute, attracting and retaining talented people, and building AI supercomputers. We want to increase our ability to raise capital while still serving our mission, and no pre-existing legal structure we know of strikes the right balance. Our solution is to create OpenAI LP as a hybrid of a for-profit and nonprofit—which we are calling a ‘capped-profit’ company.”由此可见 OpenAI 此时对于通过 GPT 探索 AGI 的技术路径的坚定程度。
商业化上,OpenAI 推出了商业化 API 接口。GPT-3 不仅生成式任务表现优越,在理解类任务上已经开始赶超,尤其是 few-shot-learning(少样本学习)和 zero-shot-learning(零样本学习)的能力引起了大量创业公司的注意。之后两年,基于 GPT-3 API 构建的应用生态持续发展并逐渐繁荣,诞生了一系列明星公司:Jasper( 2022 年 ARR 达 9000 万美金),Repl.it,Copy.ai 等。GPT-3 发布及生态成型期间(2020-2022),OpenAI 一直没有推出下一代模型,而是开始重点研究 Alignment 问题。
GPT-3 对语言已经展现了很强的理解能力,如果被有效使用可以做很多任务。但是 GPT-3 的理解能力不是 human-like 的,换句话说,让 GPT-3 做你要求它做的事情很难,即使它可以。随着模型底座的理解和推理能力增强,OpenAI 认为 Alignment 变得尤为重要。为了让模型准确且忠实地响应人类的诉求,OpenAI 于 2022 年 1 月发布 InstructGPT,并于 2022 年 3 月发布相关文章《Training Language Models to Follow Instructions with Human Feedback》详细阐述了用指令微调 align 模型的方法,后续 InstructGPT 迭代为被大家熟知的 GPT-3.5。GPT-3.5 上线后收到广泛好评,后来 OpenAI 直接将 GPT-3.5 替换掉 GPT-3 成为默认API接口。
至此,OpenAI 的 LLM 产品均以 API 的产品形态提供,并主要面向 B 端、研究人员和个人开发者市场。
1.2.3 阶段三:后 ChatGPT 阶段(2022.12至今)
2022 年 11 月 30 日,就在行业预期 GPT-4 即将发布之际,OpenAI 突然发布了开发用时不到 1 个月的对话式产品 ChatGPT,引爆了这一轮的 AI 热潮。据多方消息源称,ChatGPT 是 OpenAI 得知 Anthropic 即将发布 Claude(基于 LLM 的对话式产品,于2023 年 3 月 14 日发布 Early Access)后临时紧急上线发布的。我们有理由认为,ChatGPT 的火爆和随之引发的 AI 热潮,是在 OpenAI 预期和规划之外的。
GPT-4 的基础模型其实于 2022 年 8 月就已完成训练。OpenAI 对于基础理解和推理能力越来越强的 LLM 采取了更为谨慎的态度,花 6 个月时间重点针对 Alignment、安全性和事实性等问题进行大量测试和补丁。2023 年 3 月 14 日,OpenAI 发布 GPT-4 及相关文章。文章中几乎没有披露任何技术细节。同时当前公开的 GPT-4 API 是限制了 few-shot 能力的版本,并没有将完整能力的基础模型开放给公众。
ChatGPT 发布引发了一系列连锁反应:
C 端:ChatGPT 第一次让没有编程能力的 C 端用户有了和 LLM 交互的界面,公众从各种场景全面对 LLM 能力进行挖掘和探索。以教育场景举例,美国媒体的抽样调查称, 89% 的大学生和 22% 的 K-12 学生已经在用 ChatGPT 完成作业和论文。截止 2023 年 3 月,ChatGPT 官网的独立访客量超过 1 亿(未进行设备去重)。2023 年 3 月 23 日,ChatGPT Plugin 的发布,让更多的人认为 ChatGPT 可能会发展为新的超级流量入口(这是一个非常值得单独讨论的问题,由于本文主题今天暂不展开讨论)。
科技巨头。与 OpenAI 合作深度最深的 Microsoft 一方面裁撤整合内部的 AI 部门,一方面全产品线拥抱 GPT 系列产品。Google 多管齐下,原 LaMDA 团队发布对话产品 Bard,PaLM 团队发布 PaLM API 产品,同时投资 OpenAI 最主要竞对 Anthropic 3 亿美金。Meta 发布 LLaMA 模型并开源,LLaMA+LoRA 模式是当前开源 LLM 中最活跃的生态(Alpaca-13B 与 Vicuna-13B)。Amazon 则和开源社区 HuggingFace 基于 LLM 生态展开更积极的合作。我们分析认为 OpenAI 目前与 Meta 的竞争更多在技术层面,对 Meta 的主营业务短期内没有冲击。然而 OpenAI+Microsoft 组合对于 Google 和 Amazon 却有业务层面的潜在巨大影响,后续会展开分析。
创业生态。一方面,ChatGPT 在 C 端迅速渗透激发了新一轮的 AI 创业热情,海量的 C 端应用案例也启发并加速了创业生态的发展。另一方面,LLM 能力边界与 OpenAI 产品边界的不确定性,让基于 GPT 模型基座构建的应用和传统应用担心自己的产品价值被湮没——我们会在后文拆解 OpenAI 行为逻辑以及 LLM 产业链生态后,对这个问题展开进一步讨论。
OpenAI:行业和生态的一系列连锁反应显然超出了 OpenAI 的预期,从 OpenAI 随后的动作我们推测核心影响有三:
(1)OpenAI 可能产生了做 C 端的野心
C 端流量提供的商业化潜力和收集更多非公开数据的能力,对于 OpenAI 的模型训练、基础研究和生态发展都展现很高的价值。本月发布的 ChatGPT Plugin 就是典型的 C 端布局动作。
(2)OpenAI 可以通过适度商业化减少对巨额资本投入的依赖
OpenAI 的愿景之一是让 AGI 普惠人类社会,但是 AGI 研发需要的巨大投入导致 OpenAI 不得不向科技巨头谋求资本投入——这里的矛盾冲突引来了学界对 OpenAI 的诟病,并直接或间接导致了其大量人才流失。适度的商业化有机会让 OpenAI 减少甚至摆脱对科技巨头的依赖。我们推测 OpenAI 的商业化战略会持续在普惠与可持续独立发展之间找平衡。这里的平衡点判断对后续的产业链分析至关重要。
(3)加强 Alignment 和安全性的研究投入和动作
LLM 能力在 C 端和 B 端的迅速渗透也导致了 LLM 能力被恶意使用的风险及影响迅速扩大,安全问题的紧迫性增加。
同时当前 LLM 严重的 Hallucination(真假难辨的一本正经胡说八道)问题,阻碍了 B 端的深度应用,也对 C 端内容环境产生了不良影响。与人类的互动可以减少 Hallucination,但不一定是最本质的解决方案。通过 Alignment 研究,让模型准确且忠实得响应人类诉求,会成为 OpenAI 下一步研究的重点。
二、OpenAI 的技术路径选择(GPT 架构的 LLM )是基于什么?
首先给结论,经过对大量的访谈、课程、论文和访谈学习,我们大胆推测:OpenAI 认为,AGI 基础模型本质是实现对最大有效数据集的最大程度无损压缩。
2.1 OpenAI 认为:AGI 的智能 ≈ 泛化能力
泛化能力(Generalization)是一个技术术语,指一个模型能够正确适应新的、以前未见过的数据的能力,这种能力来源于对训练数据学习并创建的分布。
Generalization refers to your model's ability to adapt properly to new, previously unseen data, drawn from the same distribution as the one used to create the model。
更通俗地说,泛化就是从已知推到未知的过程。所有深度学习模型进步的基础都是提升模型的泛化能力。
OpenAI 认为:AGI 智能的本质在于追求更强的泛化能力。泛化能力越强,智能水平越高。
需要特别注意的是,泛化能力不等于泛化效率,下一章节会进一步展开。这也是 OpenAI 成立之初与业界最大的非共识。
2.2 模型泛化能力 ≈ 模型泛化效率 × 训练数据规模
我们认为:如果模型的泛化效率越高,训练数据的规模越大,则模型的智能程度越高。
这一结论可以由严格的数学推导得到,但是由于笔者的数学能力限制了第一性的理解,在请教了专业人士后,给出了以下抽象理解公式:
模型智能程度(泛化能力) ≈ 模型泛化效率 × 训练数据规模
这里的数学和抽象论证建议阅读冠叔、周昕宇(https://zhuanlan.zhihu.com/p/619511222)和欣然(https://zhuanlan.zhihu.com/p/616903436)的相关文章/知乎,这里不展开。
2.2.1 模型泛化效率 ≈ 模型压缩效率
对完成某个任务有效方法的最小描述长度代表了对该任务的最大理解。因此一个模型的压缩效率可以近似量化为模型的泛化效率。
AGI 的任务可以理解为:通过对训练数据集的压缩,实现对训练数据集所代表真实世界的最大程度泛化。
一个 AGI 模型的最小描述长度可以量化为模型的压缩效率。
在这个理解下,GPT 模型参数量越大,模型的智能水平越高。(模型参数量大→模型压缩效率高→模型泛化效率高→模型智能水平高)
(1)GPT 模型是对训练数据的无损压缩(数学推论)
(2)GPT 模型参数量越大,压缩效率越高(数学推论)
(3)GPT 模型是 SOTA(state-of-the-art,最好/最先进)的无损文本压缩器(现状)
2.2.2 训练数据的规模化和多元化对提高模型泛化能力至关重要
前文中我们提到:AGI 的任务是对训练数据集的最大程度泛化。那为什么模型的泛化能力不等于泛化效率呢?
因为模型的泛化效率只追求了“最大程度泛化”,而忽略了“训练数据集”。传统学术界只认为算法的创新才值得追求,训练数据集的 Scale 只是工程问题,不具备研究价值。因此主流学术界长期追求的目标其实是:模型获得智能的高效方法,而不是模型的智能能力。
而 OpenAI 则在深刻理解泛化能力的本质后,选择同时追求更大的训练数据集(训练数据集的 Scale )和更大程度的泛化(模型参数的 Scale )。
希望最快的 Scale 训练数据集,文本数据自然成了 OpenAI 的首选。因此过去五年, OpenAI 首先做的是在最容易 Scale 的单一模态文本上,把训练数据规模和模型参数量的极限拉满。LLM 只是起点,当文本数据被极限拉满后,我们有理由相信 OpenAI 会进一步扩大训练数据模态,其中包括可观测数据(特殊文本、图像、视频等)和不可观测数据(与虚拟世界和物理世界的互动数据)。
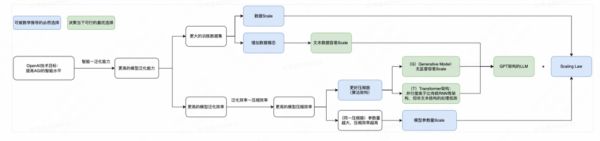
2.3 OpenAI 的技术路径选择逻辑总结
前面对于 OpenAI 技术理念本质的分析非常抽象,我们尝试对技术路径选择逻辑和历史行为进行了整体的梳理总结,如下图:
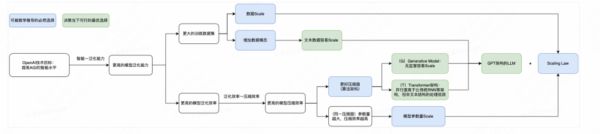
总结起来,OpenAI 认为:AGI 基础模型本质是实现对最大有效数据集的最大程度无损压缩。
在这个技术理解下,GPT 架构的 LLM 路线是过去 5 年的最优技术路径选择,模型参数量和训练数据量的 Scale 则是必然行为。
2.4 OpenAI 的技术路径选择争议
报告原文中对 OpenAI 技术路径的选择提出了一些具有启发性的问题,由于篇幅问题,我们在此仅提出问题,更详细的信息欢迎大家到报告的原文进行进一步阅读并参与讨论。
AGI 的智能是否等于泛化能力?即对于通用任务的理解与泛化能力( OpenAI 为代表),与复杂困难的科学任务的研究能力( DeepMind 为代表),谁更能代表 AGI 的智能水平。
LLM 学到的是 Book AI?一些学者认为,LLM 在语言中学习到的知识和理解,和物理世界无法形成有效的映射,因此 LLM 的智能是浅薄的智能。
One Model Rules ALL?虽然 GPT 路线的大模型的泛化理解能力很高且在不断迭代,但是此路线导致了 Hallucination 的问题也会持续存在,那么在容错率接近0的高可靠性要求场景(如垂直复杂场景的API调用等)是否必须有不同垂直模型的空间?
指令微调和 RLHF 是不是解决 Alignment 问题的正确路径?一方面,指令微调和RLHF对于基础能力越来越强的LLM基座的Alignment的帮助有限。另一方面,指令微调通过牺牲reasoning性能换取与Alignment(Alignment Tax)。
GPT 路线是没有 Memory?当前的 GPT 系列模型在处理一些单次任务时表现出色,与 GPT 模型的前序交互信息无法自动写入下一次交互的 token。而AutoGPT等目前只能暴力回放历史,导致太多 token cost。这就导致 GPT 模型对于大量复杂的系统工程和连续的生产行为不友好。
三、基于 OpenAI 的技术选择本质,理解 OpenAI 的过去和未来
3.1 拟合:OpenAI 的历史行为解释
综合前文所述,OpenAI 的愿景是追求普惠的 AGI。而 OpenAI 的技术理念为:AGI 智能本质是追求的泛化性,因此 AGI 基础模型本质是实现对最大有效数据集的最大程度无损压缩。
基于此我们尝试对 OpenAI 的历史行为进行解释。过程中我们更感受到,Sam Altman (商业)+ Ilya Sutskever(算法) + Greg Brockman(工程)组合的稀缺性。OpenAI 今天的成果是算法、工程、数据、产品、GTM 团队密切配合的结果。
3.1.1 技术
(1)为什么 Bert 在下游理解类任务表现出色(远高于 GPT-1 和 GPT-2 )时,OpenAI 仍然坚持 GPT 路线?
如前文分析,OpenAI 追求的是模型的泛化能力。所有的有监督学习都是无监督语言模型的一个子集。那么为了特定任务短期效果提升而选择有监督学习无疑是不本质的做法。
早期 BERT 在理解类子任务上的高表现,是因为对特定数据集通过有监督学习,可以更快速得到对该任务的理解。当 GPT 等无监督模型的参数足够大且语料足够丰富时,通过无监督语言学习就可以完成其他有监督学习的任务。
因此 OpenAI 坚持 GPT 路线就是必然的简单选择。
(2)为什么过去持续 Scale,未来还会持续大幅 Scale 吗?
GPT-1 至 GPT-3 的 Scale 是在文本模态上的训练数据量和模型参数量的双重 Scale。其中
训练数据量 Scale 是提升 AGI 泛化能力的必然选择。当前最容易 Scale 的是文本数据,但当文本模态的理解能力被逐渐拉满后,OpenAI 必然会开始相对不容易的数据 Scale 方式,即增加数据模态并进一步上量。可以看到 GPT-3.5 增加了特殊文本数据(代码)进行训练,GPT-4 引入了图像等数据模态。
模型参数量 Scale 是当前最优算法架构 Transformer 和最优算法路径 GPT 组合下,提升 AGI 泛化能力的副产物。如果未来 OpenAI 找到了更高效更优的算法,同样智能水平的 AGI 基础模型的参数量未必更大。
(3)为何将工程能力的建设放到极高的优先级?
在与传统学术界的非共识下,OpenAI 很早就意识到了模型 Scale 的重要性。因此搭建了有工程能力的算法团队(Pretraining 组与 Alignment 组)和有算法理解的工程团队(Scaling 组)。并搭建了算法与工程紧密配合的组织架构。工程团队为算法团队做好高拓展性的基础设施,算法团队以工业化的方式设计算法训练。
一些可以窥见其工程能力(工业化的模型生产能力)的事实:
OpenAI 已经具备工业化训练并准确预测超大规模模型表现的能力。2021~2022 年,OpenAI 与 Azure 合作重构了 OpenAI 的基础设施。GPT-3 的训练是对这套基础设施的第一次使用,过程中发现并修复了一些 bug。基础设施的 bug 修复后,GPT-4 的训练就稳定且一气呵成了。并且利用这套基础,OpenAI 团队在 GPT-4 训练的初期,仅用了 1/10000 的算力进行小模型实验,就通过小模型实验的 loss 准确预测了 GPT-4 大模型的最终 loss。
开源 OpenAI Triton:没有CUDA经验也能够自动完成GPU编程的各种优化(内存合并,共享内存管理,SM 内调),用 Python 也能写出高效 GPU 代码。
我们认为,OpenAI 和目前大部分 LLM 团队的工程能力可以用工业化模型工厂和模型作坊对比。工程能力的巨大差距会导致大部分 LLM 公司对 SOTA 模型追赶的难度进一步拉大。
(4)为什么砍掉 Robotics 等项目 all in LLM?
简单来说,是因为 Robotics 技术的发展暂时落后于 AI 导致 RL 很难 Scale。
其实 Robotics 项目中使用的 RL 也是符合 OpenAI 技术审美的算法。并且 RL 和世界(虚拟与物理世界)的交互以及其中能够学习到的高维表征是 OpenAI 非常渴望探索的。但是当时受限于 Robotics 技术本身在发展初期,机器人无法 Scale 限制了 RL 算法和数据的 Scale。因此 OpenAI 选择了砍掉 Robotics 等项目 all in LLM。
但我们有理由判断这是一个阶段性选择。当时机成熟,大模型与 Robotics 或其他能与世界交互的终端结合,在与世界互动中习得更高的 AGI 智能,是必然会发生的。事实上,OpenAI 于 2023 年 3 月对人形机器人公司 1X 进行了约 2000 万美金的 A 轮投资。
(5)为什么会有 Hallucination 问题?
OpenAI 追求的 AGI 智能是最大程度的模型泛化能力。LLM 的目的,并不是尝试“拟合”训练集,而是无损地找到训练集所代表的本质规律(概率分布),从而理解训练集以外的数据。因此 LLM 会生成出训练集之外的内容,造成 Hallucination 问题。
可以预期的是,随着 AGI 基础模型能力的逐步提升,Hallucination 问题会逐渐减轻。不过在当下,OpenAI 会采用预处理和后处理模型等补丁方案,临时减轻 Hallucination 问题以便让 LLM 具备更高的可用性和更低的有害性。
同时需要的注意的是,LLM 的文本训练语料中本身就存在谬误和价值观冲突,如何为 LLM 构建“价值判断”也是一个值得深入研究的问题。
3.1.2 产品
我们认为 OpenAI 在产品方向的所有行为都可以被其在产品工作的两个目标及其衍生的两个业务飞轮来进行解释。其中两个核心目标:
设计出能够帮助 OpenAI 收集更多有效数据的产品形态,以追求更高的 AGI 智能。
设计出基于当前 AGI 模型能力,更普惠大众的产品。
根据目标衍生出了两个业务飞轮:
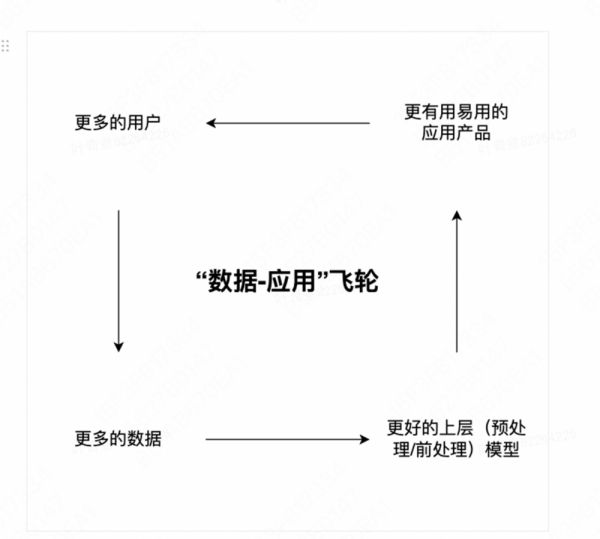
(1)更普惠的 AGI 产品与“数据-应用”飞轮
此类产品的目标是:围绕 AGI 模型的能力,搭建能被友好、有效地被 C 端大众和 B 端公司使用的产品,以将 AGI 赋能并普惠人类社会。其中:
ChatGPT
GPT-1-4 系列的 API
Codex API
等都是此类产品。C 端用户可以通过此类产品提升日常生活的各类任务效率,解决各类问题;而 B 端用户则能通过此类产品获得 AGI 模型的能力,帮助自己搭建垂直场景的产品解决方案,并通过“数据-应用”飞轮迭代自己的数据壁垒和产品优势。
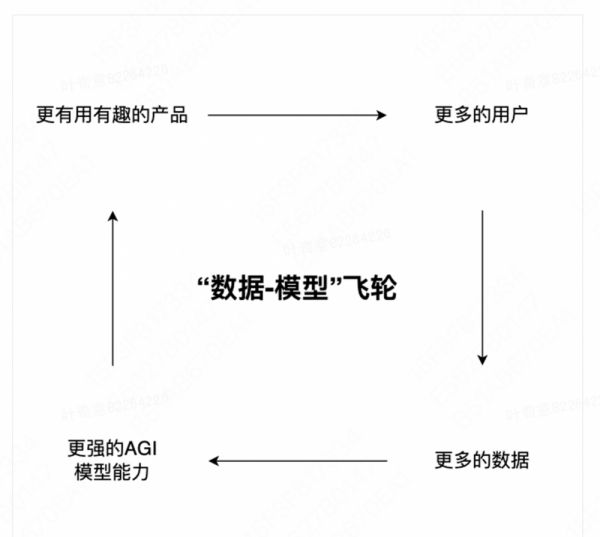
(2)收集更多有效数据反哺基础模型与“数据-模型”飞轮
此类产品的目标是:基于 OpenAI 的模型能力和技术储备,搭建特定产品场景,吸引特定能力或兴趣的用户,通过用户行为反馈积累特定的有效数据,反哺 AGI 基础模型。这类产品由于所需的数据、能贡献数据的用户群体不同,产品形态和面向的市场各有差异。
DALL·E 与 Clip:图-文数据
ChatGPT Plugin:用户通过应用及 API 构建复杂任务处理方案的数据
OpenAI Codex Playground:用代码构建不同应用程序数据
OpenAI Universe:各类强化学习任务及训练数据
Rubik's Cube:模型与物理世界互动数据
(3)两个数据飞轮之间的迁移与博弈
一个关键并且有趣的事实:上述这两个目标及其衍生的业务飞轮事实上存在一些微妙的结构性矛盾,而这正是一些让人困惑的现象和行为背后的底层原因。OpenAI 自身产品与其上层生态应用产品会在两个数据飞轮间迁移和博弈。
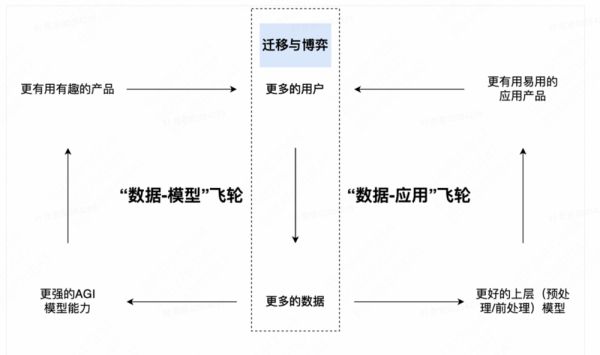
迁移一:OpenAI 自身产品的产品目标,可能会由收集数据反哺大模型,迁移至构建生态普惠大众
典型案例如 GPT 系列模型的 API 产品。GPT-1 与 GPT-2 是 OpenAI 在 LLM 模型上的初期产物,这个阶段的 OpenAI 需要更多的高质量文本数据,因此只向有限高质量用户开放 API,并且以免费和极低的浮动价格提供给用户。到了 GPT-3 发布时,OpenAI 在 LLM 能力上逐渐拉满,通用的文本数据对模型本身的能力提升 ROI 降低,因此 OpenAI 此时对产品进行标准定价并开放给更多用户。到今日,该系列产品已为不需要 waitlist 的标准产品。迁移二:OpenAI 基础模型的能力提升,会导致部分层生态应用产品的用户向 OpenAI 自身产品迁移典型案例如 Jasper 与 ChatGPT。由于 GPT 系列模型的 Alignment 问题,和 API 本身对 C 端用户的易用性问题,在 ChatGPT 发布前普通用户难以使用 LLM 的语言理解与生成能力。因此 Jasper 基于对 GPT 模型能力的理解和使用经验,打造了优于市面所有竞品的营销内容生成平台,并用一年多的时间迅速涨至 9000万 美金的 ARR。然而 ChatGPT 的面市将 Jasper 的优势迅速拉低,模型能力之上过薄的产品令市场质疑其业务的护城河。虽然目前公司的营收仍在高速增长,但是 Jasper 也不得不从营销内容生成平台向营销链路 SaaS 转型,以获取更安全的生态位。这类迁移不是 OpenAI 主观设计的,却是基础模型能力提升必然会发生的。博弈一:有助于提升 AGI 通用能力的场景与用户行为数据的争夺典型案例如 ChatGPT Plugin与 Langchain。Langchain 是一个基于 GPT 生态的工具层开源项目,为开发者用户提供了将私有数据和实时搜索结果与 LLM 能力结合构建应用的方案,是 GPT 生态的重要组件。Langchain 是当前生态最活跃的玩家之一,公司于 2023 年 3 月获得 Benchmark Capital 1000 万美金的首轮投资。然而就在 Langchain 宣布融资消息一周后,OpenAI 推出 ChatGPT Plugins 插件集。Plugins 能够:(1)调用互联网数据解决实效性问题; (2)接入第三方私有数据; (3)操作外部应用。 丰富有用的能力组件直接挤压了 Langchain 的生存空间。然而与市场上认为“Plugins 是 OpenAI 出于商业化目的为构建 LLM 时代的应用商店而推出的”主流观点不同。我们认为 OpenAI 推出 Plugins 的本质原因是为了获取“用户为了解决特定任务时会如何使用应用程序和 API 的行为数据”。
值得注意的是,“正确理解用户意图,准确选择并使用合适的工具可靠地完成任务”这个场景目前竞争激烈。除了 OpenAI 外,Adept AI、Inflection AI 以及 Meta 的 Toolformer 模型都在竞争此领域的生态位。进一步讨论,如果 LLM 未来真的成为新一代的人机交互界面,准确性和可靠性是必要条件。
博弈二:深度垂直场景的数据与用户争夺
典型案例如 BloomBergGPT。2023 年 3 月 30 日,BloomBerg 发布自研垂直领域 GPT 模型 BloombergGPT,模型参数 50B,训练 Token 700B,其中私有金融数据和公开数据各一半。在私有金融任务上的表现远高于当前的 GPT 模型。
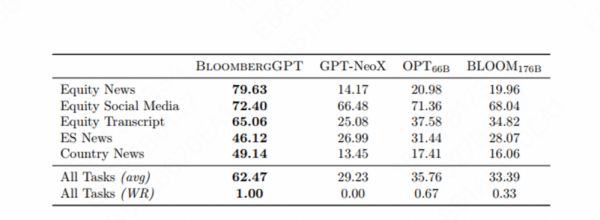
换言之,如果垂直领域的任务复杂度足够深、数据足够独特且数据量足够大,不拥抱通用 LLM 生态而自研垂直领域大模型,可能是一个至少短期内合理的博弈。
整体而言,这两个数据飞轮之间的产品迁移和博弈将会持续存在。
3.1.3 GTM(Go-To-Market)与商业化
整体而言,我们认为 OpenAI 的 GTM 和商业化策略是普惠大众与保持自身独立性间的 trade-off,且公司会在权衡中持续摇摆。
(1)从 OpenAI 到 OpenAI LP:非盈利向有限盈利的转型
OpenAI 在成立之初只有探索普惠 AGI 的愿景,并没有想清楚技术实现路径,大大低估了需要的资金投入。在 OpenAI 以非盈利组织运营的 2 年期间,总融资金额估算只有 1000~3000 万美元左右。2018 年~2019 年是 OpenAI 资金最为困难的阶段。在 2017 年确认 GPT 架构的 LLM 技术路径后,GPT-1 与 GPT-2 的训练烧尽了几乎所有资金。他们不仅无法继续承担下一代模型训练的天价费用,也无法招聘行业优秀人才(实际上已经有研究人才被谷歌挖走)。
在此背景下,非盈利的 OpenAI 于 2019 年 3 月改制为有限盈利的 OpenAI LP。股权改制后,OpenAI 先后接受微软约 130 亿美金投资。此后,OpenAI 不仅可以开出高薪吸引行业顶级人才,承担高昂的 AI 训练费用,打造超级 AI 基础设施,还加快了算法探索和产品研发的速度。
然而对于科技巨头的高度依赖,导致 OpenAI 内部和外部都出现了对其普惠愿景和丧失独立性的质疑,甚至导致了部分核心员工的流失。
我们认为,AGI 是个资金密集型行业,OpenAI 必须要找到可持续探索 AGI 的运营模式。获得外部资金支持和自身产品商业化是当前的两条可选路径。自身产品商业化对于 OpenAI 来说是一个更可控且可以保持自身独立性的模式。因此我们判断,OpenAI 会进一步开展商业化进程,但不会以收入或利润最大化为目标。OpenAI 最根本的目标还是探索 AGI 智能的极限。
有限盈利的商业化策略,会使 OpenAI GTM 和商业化决策不同于传统的科技巨头,进而影响行业生态。
(2)微软与 OpenAI 的合作蜜月期
自 2019 年微软首次投资 OpenAI 以来,双方展开了教科书级别的战略合作。
OpenAI 得到了什么:
资金:2019 年和 2021 年两轮投资总计约 30 亿美元,2023 年 1 月据悉追加了 100 亿美元投资;
工程 Infra 的助力:Azure 对 OpenAI 模型的训练和推理投入了专门的团队支持。更重要的是 2021-2022 年,Azure 和 Greg 带领的 Infra 团队重构了 OpenAI 的整个基础设施,得到了稳定性和可拓展性都极高的模型训练 Infra(可预测的 Scale 对 OpenAI 很重要);
多元优质的特殊数据:GitHub 和 Bing 等特殊的文本数据;
C 端心智占领和丰富的通用应用场景:GitHub(7300 万开发者用户)、Office 套件(1.45 亿的日活)、Xbox(Xbox Live 9000 万月活)分别为 OpenAI 试水 LLM 应用提供了开发者、通用生产力和营销工具、游戏等优质的通用应用场景,与 LLM 形成独有的数据飞轮;
B 端的客户资源和垂直场景:Azure 拥有 95% 的财富 500 强企业,有超过 25 万家公司使用 Microsoft Dynamics 365 和 Microsoft Power Platform;
微软得到了什么:
首先要注意的是,Microsoft 是营收最多元化的科技巨头,第一大业务 Azure 营收占比31%,第二大业务 Office 营收占比 24%。而 Google、Amazon、Meta、Apple 等硅谷大厂的单一主营业务营收占比均超过 50%。
Azure(进攻):作为 OpenAI 的云服务供应商,Azure 是 OpenAI产品 在公有云场景的独家使用平台。如果我们认为未来人类数字活动的 AI 含量将大幅提升,且 OpenAI 的产品会占据大部分份额。那么 Azure 很有可能会获得大部分云计算增量推理市场。同时,Azure 与 OpenAI 共同研发的大规模训练基础设施若开放,则还能获得大部分云计算训练市场。长期来看,这对 AWS 会造成不小的挑战和冲击。
办公套件(防守):Office 套件中所有单品都在受到新型玩家的挑战(Notion、Airtable 等),OpenAI Copilot 与 Office 套件的结合既升级了单品,也放大了 Office 各单品间联动的优势。
Bing Search(防守):很多投资者认为 Bing Search 会颠覆Google。我们在这里有不同的观点。Bing 与 ChatGPT 补丁式的合作其实不改变搜索体验本质,但却是会抢走部分 Google 的搜索流量。真正有可能颠覆 Google 搜索是类似 Perplexity 的 LLM 原生的全新搜索产品。在搜索中增加 LLM 其实反过来会增加单 query 的成本(根据各类推算,不优化的话,当前可能2~3倍于传统搜索),进而降低传统搜索业务的利润空间。而 Google 对于搜索业务的依赖远高于 Microsoft,战略上也就更难受。但不管对于 Bing 还是 Google Search,原本极高的搜索广告营收都阻碍了它们真正在 LLM 语境下像 Perplexity 一样构建全新的信息和知识获取引擎。
现阶段是 OpenAI 和微软合作的蜜月期。不过值得注意的是,模型厂商和云服务厂商在产业链上的价值分配在未来仍然会产生博弈,微软与 OpenAI 的蜜月期能持续多久未可知。
(3)ChatGPT 意外收获的 C 端市场,从基础模型层向应用层的扩展
ChatGPT 让 OpenAI 意外收获了 C 端市场,近 4 个月的时间 ChatGPT 官网总访问量超过 10 亿,独立访客数超过 1 亿。从生态繁荣的角度,基础层涉足应用层在任何产业链中都是大忌,这会极大打击生态位上层玩家对基础层的信任,但是 OpenAI 在此问题上展现出了极大的“无所顾忌”,而这种行为从 AGI 愿景以及更好的数据 Scale 角度可以得到解释:
更低成本的数据获取:通过对 C 端的流量与心智占领,如今 ChatGPT 与 OpenAI 已成为了当前 LLM 的代名词和行业标准。作为一项全新的技术和产品,心智占领可以让 OpenAI 持续以更低的 GTM 成本获得用户数据。
更丰富场景有效数据的获取:比如 Plugin,我们推测,通用的对话数据对于 GPT-4 的边际价值已经不大,但是 Plugin 所收集的通过使用工具完成用户任务的数据非常有价值。这个可能是未来成为真正的新一代人机交互界面的关键(前文提到这个领域竞争激烈)。
通过更多长尾对话和应用场景来优化模型能力:一方面可以加快 Alignment 和安全性的研究,一方面也可以挖掘更多潜力场景。
最大限度保持普惠 AGI 的初心:通过商业化得到巨大的造血潜力,有机会让 OpenAI 未来减少对巨头的依赖并健康的可持续发展
(4)通过投资构建生态和补齐 AGI 探索需要的技术伙伴
2021 年,OpenAI 宣布启动一个 1 亿美元的创业基金,名为 OpenAI Startup Fund。主要投资标的有以下几类:
应用层公司
初创企业可以在 OpenAI 公开发布新工具之前先使用新能力,这会让他们在竞争对手前占据优势。OpenAI 可以深度获得各类场景的数据或早期反馈。
未来的 LLM 生态不会只有 OpenAI 一个模型层玩家,而会有多家模型厂商和大量垂直应用。通过投资的强合作关系可以让 OpenAI 和它的合作伙伴们的飞轮更大且更快。
芯片、机器人等前沿科技公司
OpenAI 在 AGI 上的探索预计将长期领跑于行业,这会导致 OpenAI 需要探索更多先进的产品和工具来满足自身的研究需要。如,新架构的芯片服务更大规模更多模态的模型训练,更先进更低成本的机器人让 OpenAI 未来有机会做与物理世界互动的 RL 的 Scale 等。
3.2 预测:OpenAI 的未来行为推演
3.2.1 技术
如前文分析,在 OpenAI 的技术理解和审美下,数据和参数量的 Scale 是必然选择,而 Generative Model 和 Transformer 则是当下的最优选择。基于此,我们大胆对 OpenAI 接下来的技术行动做一些预测:
(1)进一步增加 LLM 没见过的有效数据,拥抱多模态
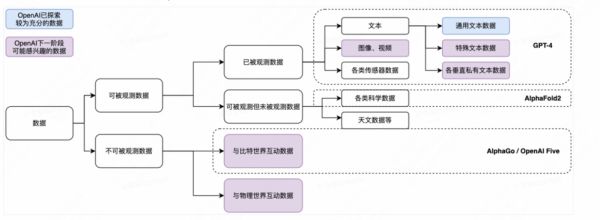
通用文本数据:边际收益变低,引入更多其他类型的文本数据,如代码、其他可计算语言
图像视频等模态数据:图像和视频数据在 Transformer 架构下训练效率很低, Scale 的训练成本会以平方或平方以上级上升
与比特世界的互动数据:如前文所述,OpenAI 一直想做 RL(强化学习),但过去 Robotics 的RL很难Scale,但在比特世界有大量的用户场景可以尝试
与物理世界的互动数据:通过机器人等与物理世界互动做 RL 的 Scale,这里的进度很大程度取决于机器人技术的发展速度
(2)RL 的 Scale
与 Genrative Model 相似,RL 也是符合 OpenAI 审美的算法。虽然 RL 对于目前已发布的 GPT 系列模型贡献较小,但 GPT-3.5 初步将 Instruction Tunning(指令微调)和 RL 结合放大,已经显示出了令人惊喜的效果。未来预计 OpenAI 会用更 Scale 的 RL(RLHF,RLAIF)手段辅助基础模型训练。并且如今有了更多 C 端流量在手,不排除未来 OpenAI 会把一些产品变成 RL 的 Agent 来辅助训练的可能(如用 ChatGPT Plugin 做“开发者行为相关和工具使用”的 RL 训练)。
(3)Robotics 与 Embodied AGI(具身智能)
我们认为在当前时间点,比起 AGI for Robotics,OpenAI 更关心的是 Robotics for AGI。通过 Robotics 与环境互动和感知感官信息的能力,来增加 AGI 基础模型对物理世界的理解和认知推理能力。
(4)寻求能更高效 Scale 更多模态数据的新算法架构
Transformer 仍为当前 OpenAI 算法架构的最优选。它对于文本模态的 Scale 很高效,但是对于图像视频等模态很低效。因此 GPT-4 之后,OpenAI 寻求更高效的算法架构的需求变得更紧迫。我们有理由相信 OpenAI 内部正在做 Transformer 变体甚至更新的算法架构的模型训练实验。
(5)对于模型的推理和涌现能力的深度理解
现在学术界对于 LLM 的涌现和推理能力的理解还在早期。我们相信下一个词预测的准确性和推理能力在高维空间必然存在数学联系,但复杂难以研究。技术领域最好的创新其实都来自于对已知的本质理解。对这个领域的深度研究会很有价值。
(6)增加模型的可靠性、可控性和安全性
可靠性:Hallucination 问题的弱化;
可控性:准确的理解并执行任务。今天 ChatGPT 引入了 Wolfram,用第三方组件的方式给了过渡方案。未来一定会努力在模型本身增加可控性;
安全性:不作恶以及不被恶人利用。
在这三点上,如何做好 Alignment 很重要。RLHF(Reinforcement Learning from Human Feedback)只是第一步。
3.2.2 产品
我们相信在现阶段,OpenAI 的产品策略会继续以“进一步提高 AGI 模型能力”为首要目标,以“让 AGI 产品被更广泛地合理使用”为次要目标。
(1)为了进一步提高 AGI 模型能力,OpenAI 会设计更多能获得有效数据、进行模型实验、与用户互动迭代的产品
这里的关键是有效数据。之前提到 Ilya 过去的技术审美喜欢“基础算法规模化”。同样的在数据侧,我们认为 OpenAI 会优先选择容易 Scale 的,容易训练的数据。未来 OpenAI 可能会将产品与模型训练过程结合,将用户行为变成模型训练的一部分。
(2)为了让 AGI 产品被更广泛地合理使用,OpenAI 会更小心的控制模型能力释放给公众的节奏
AGI 不只是提升社会生产力,而是提升社会生产力进步的速度。Sam 已在多篇文章和访谈中强调了AI安全性、AI带来的未来贫富差距拉大等一系列社会问题。GPT-3.5 以上的模型事实上已经开始影响人类社会许多工种的生态。GPT-4 目前发布的是降级版。可以预测,OpenAI 未来可能会和更多的社会研究机构对模型能力可能造成的潜在影响进行预测,并放缓模型能力释放的节奏,给相关行业缓冲期。
3.2.3 GTM 和商业化
(1)GTM 策略上,OpenAI 会持续捕捉 C 端的 Attention,同时与 B 端展开更多元的生态合
C 端流量同时为 OpenAI 提供了各类收集数据的有效渠道和变现造血能力,预测 OpenAI 会持续谋求更大的 C 端流量、更长的用户停留和更深的用户行为。Attention 和心智占领对于 C 端产品尤为重要。Anthropic 的对话产品 Claude 与 ChatGPT 能力上不分伯仲,但在 C 端的认知度和流量都远低于 ChatGPT 和 Bard。
B 端则会持续通过与微软的生态全方面合作、创业公司的使用激励、投资等角度,加速“数据-模型”飞轮的转动。
(2)有限商业化
根据前文对 OpenA I做普惠 AGI 的愿景及有限盈利架构的分析,我们认为 OpenAI 的产品定价会根据普惠和组织可持续发展为纲领制定。具体表现为:
有强反哺模型目标的产品免费;
C 端通用产品贴成本定价(未来甚至可能免费);
B 端产品有限盈利;
总体而言,OpenAI 有限盈利的架构会使其 GTM 和商业化不同于商业化公司。但作为事实的产业链链主和行业标准,它的 GTM 和商业化策略会对行业有很大的影响。
四、LLM 产业链分析
4.1 宏观视角下 LLM 生态
4.1.1 当前行业增量营收分布推测:应用层 30%~40%,模型层 0%~10%,计算基础设施服务 50-70%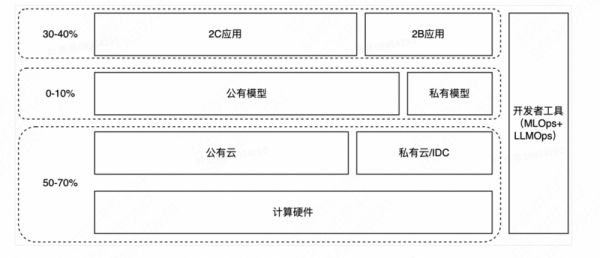
(1)应用层拿走 30%~40% 价值
根据 A16Z 对美国 LLM 创业调研,纯应用厂商毛利约 60%~80%,20%~40% 的营收用于推理和模型 fine-tuning;
应用厂商当前用户和营收增长迅速,当前已经多厂商 ARR 达 1 亿美金;
虽然用户数量和营收都在高速增长,但很多应用厂商都面临用户留存率低、竞争加剧和护城河浅等关键问题;
(2)模型层拿走 0%~10% 价值
根据 GPT-3.5 的模型参数量和价格测算,推测 OpenAI 几乎是以成本或极低的毛利对 API 定价。且根据对海外竞品 LLM 公司的访谈,竞品同类能力模型都在做推理成本优化以匹配 GPT-3.5 的价格(尚未达到);
未来纯模型厂商若模型能力与 OpenAI 的标准产品同质化,推理价格必然需要长期匹配有限盈利的 OpenAI 普惠大众的商业化策略。LLM 的训练成本又极高,纯模型厂商面临极大的商业化压力;
(3)计算基础设施服务层(计算硬件+云计算)拿走 50%~-70% 价值
推理上拿到 20%~40% 的价值;
训练成本极高:以当前的 A100 价格计算,千亿模型(GPT-3.5)训练成本约 2000 万人民币;在 LLM 进入多模态阶段后,预计 SOTA 的模型训练计算量增长会超过单位计算成本的下降速度,且短期内会有更多模型层玩家进入市场,预计 1~3 年内 LLM 的训练市场会增长迅速。
训练侧更多 LLM 玩家的入场及多模态模型进一步 Scale,推理侧 LLM 在进入爆发式增长起点,云计算和计算硬件市场将加速增长。云计算厂商行业格局可能发生较大变动。
(4)由于当前 LLM 生态在发展初期,开发者工具的生态位还不稳定,本文暂不展开讨论。
4.1.2 未来应用层高速增长且毛利可能改善,模型层竞争加剧,计算基础设施厂商将持续高速增长
需要注意的是,现阶段 LLM 仍处于大规模研发期,很多 LLM 新玩家才刚入场。且 LLM 在应用层的潜力还没有被挖掘,大规模渗透还没有开始,LLM 的训练成本未被摊销。因此云计算和硬件厂商成了这一时期的最大玩家。我们认为此时的价值链分布为 LLM 行业发展早期的状态。行业生态真正成型后的价值链分布将与现阶段大相径庭。
(1)应用层:随着 LLM 在各类应用场景的潜力被挖掘,应用层将加速增长。同时由于模型层竞争加剧可能导致的价格战,预期应用层毛利会改善。不过同质化的应用同样会导致价格战,这就要求应用层公司将壁垒建立在基础模型能力之外,我们认为能够差异化产品或建立网络效应的应用层公司会真正获得最大的产业链价值。
(2)模型层:OpenAI 的定价策略将会成为纯模型 API 的定价标准。预计 OpenAI 会坚持普惠大众的有限盈利商业化策略(如:2023 年 3 月 ChatGPT 降价 90% ),不具备显著技术优势的 LLM 公司靠卖模型 API 盈利预计会很艰难。只有真正掌握全球 SOTA 模型及成本控制能力的公司才掌握模型定价权。
3)计算基础设施服务层(计算硬件+云计算):训练推理双增长,全行业获得新的增长曲线。新的增长可能也是行业洗牌的机会,如何与 LLM 配合获得主动权对云计算厂商至关重要。同时要注意一些应用层公司或硬件层公司做新云的可能性。
在盘点了当前 LLM 生态的宏观格局后,我们放大讨论各个局部,开放式地提出一些值得探讨的话题。但是现在行业处于剧烈变化的阶段,我们基于当前的理解给出一观点,更多的是为了激发大家的讨论。
4.2 LLM 是否会进入价格战,模型层价格收否终将收敛到云计算的价格?
讨论这个问题前,首先需要提出两个问题:
(1)LLM 的价值点到底是什么?是 LLM 提供的信息获取、理解与推理能力,还是新的人机交互界面的革新?
前者模型的发展目标是进一步提升的复杂推理和高级智能能力。后者模型的当务之急是增加对人类任务的理解力,加强使用工具应用的可靠性和准确性。两者当前的模型发展重点是有细微分岔的。
(2)新入场的 LLM 公司的自我定位是什么?是探索 AI 智能极限的 AGI 公司,还是地域版的 OpenAI 镜面公司,还是商业化 LLM 公司?
我们认为现阶段,复刻 GPT-3.5 和 ChatGPT 本质是工程问题,复刻 GPT-4 以后的 OpenAI SOTA 模型需要的则是算法科研能力。而要探索 AGI,则需要极强的技术洞见,独立的技术判断(OpenAI 不一定是正确答案),真正的 AGI 信仰和长期有耐心。
不可否认,GPT-3.5 和 ChatGPT 就已经具备充分的商业化潜力了。
但是我们认为从模型能力角度,GPT-3.5 和 ChatGPT 级别的模型能力将在 1~2 年在各个 LLM 团队内拉平。如果公司的模型能力停留在这个水平,模型 API 的价格战不可避免,终将趋向于成本。而真正能独占性地持续迭代出 SOTA 模型的厂商才能掌握定价权。
另一方面从产品形态角度,API本身不会成为平台,只会成为通道。以 AGI 模型能力为基础打造具有聚合能力的平台型产品,占据有利的生态位,才可能摘取更多的价值。
需要声明的是,长期来看,我们不认为这一波 AI 浪潮的价值都会被基础设施厂商消化。与国内 2010 年后的第一波 CV(Computer Vision)浪潮不同,现今 LLM 的下游高价值场景非常发散,并不会收敛到 1~3 个(人脸识别在安防、身份认证等)标准场景上。LLM 模型层将获得更多溢价。
4.3 路径不同的 LLM 公司是会分岔还是收敛?
如上个问题所述,不同自我定位和目标的 LLM 公司会在下一个赛段短期内分岔发展。而长期的工作需要时间才会有阶段性成果(GPT 路线走了 5 年)。
我们认为 LLM 模型发展发向很有可能是一个“收敛-发散-再收敛”的过程。短期工作有很多会收敛,接下来在垂直领域会分岔,当长期工作有了阶段性成果后会再收敛。
4.4 LLM:开源 VS 闭源?
观察文生图领域,Stable Diffusion 和 MidJourney 仍然在拉锯竞争。而 LLM 领域, LLaMA+LoRA 项目遍地开花,人人都可以训练一个大模型。两个生态会如何演化?
我们提供一个分析角度:开源本质是产品研发和 GTM 的一种方式。社区的活跃程度不能等同于商业价值。对于 LLM 的研发,开源是否能提供闭源不具备的价值?无论 GTM 的路径是什么,客户最后买单的是产品价值。开源闭源产品能力或服务体验是闭源产品无法满足的?
4.5 计算基础设施层的增量会有多大?是否有新云的机会?
2023 年 4 月 5 日, ChatGPT Plus 停止新的付费注册,据称是因为微软的计算资源不够了。不管消息是否属实,LLM 已经并且将持续增加对计算基础设施的需求显而易见,甚至可能导致云计算行业的洗牌。关于AI对于云计算的增量有多大,取决于人类在比特世界的活动会多大程度被 AI 渗透。这需要对模型能力进行预测及对每个细分场景进行分析,今天暂不详细展开。
英伟达 2023 年 3 月的 GTC 大会发布的四款推理平台中,H100-NVL(2卡,显存94GB*2HBM3)——为什么不是 80G(单卡平台的显存)*2?因为放不下GPT-3 176B 的参数量。同时,英伟达发布 DGX Cloud 产品,企业可以直接租用集群进行各类 AI 模型训练和 fine-tune,消除了部署和搭建基础设施的复杂性,越过了传统云计算厂商。这让我们不禁怀疑,AI 带来巨大计算增量是不是让英伟达燃起了做云计算的野心?
另一个角度,真正远超竞争对手模型能力的 LLM 公司,是否有机会向下延伸,打出一朵新云?正如前文分析,计算基础设施是当前生态中确定性最高的可持续获利且有壁垒的的环节。如果 SOTA LLM 和某家云服务独家绑定,下游客户对 SOTA LLM 的粘性很可能高于云服务商,这里的潜在机会非常值得深入研究。
毋庸置疑的是,无论是新老玩家,与 LLM 的竞和战略对云计算服务厂商至关重要(就在发文当天,AWS 发布 Amazon Bedrock,正式加入战局)。
4.6 下游应用和工具是否有稳定的生存空间
Jasper 和 Langchain 的遭遇引发了创业者的巨大争论:能力快速升级的 OpenAI 会不会逐步蚕食下游应用和工具的生存空间?
我们认为创业者可以拆成 2 层看这个问题:
(1)问题1: AGI 不停升级的基础模型能力,是否会自然覆盖我的产品核心竞争力?
如果产品的核心竞争力完全是模型能力的浅层封装,公司的生存空间自然不稳定。应用层公司应努力构建自有业务的网络效应或数据积累。以 Jasper 举例,如果公司能够将核心产品竞争力从单一的“智能化营销内容生产”转为“最智能的 All-in-One 营销平台”,那与 ChatGPT 的竞争担心就会大大减弱。当然这就让 Jasper 面临和 Salesforce、Hubspot 等传统营销平台的竞争。各个垂直场景新老玩家谁能胜出,也是一个值得展开研究的话题。
(2)问题2: OpenAI 为了不断发展 AGI,是否希望获得我场景中的数据?
这个问题就回到了两个数据飞轮间的博弈,且不仅仅是技术的博弈。OpenAI 会持续希望获得自己模型没有学习过的非同质化有效数据。
Langchain 的场景拥有 OpenAI 希望获得的“开发者通过使用各类工具构建应用,来完成用户任务”的数据,而场景高度依赖 GPT 生态,自然场景和数据都被 OpenAI 回收了;
Bloomberg 则不然。我们相信拿 Bloomberg 的数据 fine-tune GPT 模型,无论是效果还是成本都会优于 BloombergGPT。但 Bloomberg 掌握了金融的深度场景、量足够大且足够独特的私有数据,便掌握了和 OpenAI 博弈的能力。当然另一个层面的囚徒困境是:如果你选择不拥抱通用模型生态,是否会输给搭建于大模型之上的竞争对手?
4.7 模型层与应用层的价值分配
首先,由于 OpenAI 实际掌握了 LLM 模型的行业定价权,基于我们对 OpenAI 会持续追求普惠 AGI 愿景和有限盈利架构的判断,我们认为 OpenAI 不会主观侵占下游应用的利润空间。
那么当底层 LLM 模型的参数量逐年上升,模型的推理成本会不会让上游应用无法承受?
我们判断不会。因为不同智能含量的场景,需要的模型能力和能承受的模型价格都是不同的。举例来说,写 10 条小红书的营销文案可能需要月工资 5000 元的员工 1 小时,而 10 条跨国法律合同修改意见则需要小时工资 400 美元的海外律师 1 小时。二者对模型成本的敏感性显然差很多。
4.8 C 端的超级流量入口?平台还是管道(Platform VS Pipeline)?
OpenAI 无疑展现了新一代 C 端流量入口的潜力。然而流量可以成为管道也可以成为平台,二者的商业价值不可同日而语。
正如 Packy McCormick 在 Attention is All You Need 文章中指出,OpenAI 率先吸引了Attention with Intelligence。ChatGPT 现在已经和亿级用户建立了直接的联系,为服务用户提供了较低的边际成本,且可以以递减的边际成本获得需求驱动的多方网络效应,成为了一个最有潜力的超级 C 端聚合平台。Plugin 的交互界面和传统 API 完全不同,对 C 端可能产生更深远的影响,今天暂不展开。
同时 Google 仍然不容小觑,最近 Bard 将底层模型替换成 PaLM 后,能力大幅提升。当前 Bard 和 ChatGPT 相比,仍然很 Nerdy。但是我们预期,以 Google 的技术深度和各类 10 亿量级用户的 C 端产品,它充分具备打造新一代以 LLM 为基础的新一代 C 端聚合平台的潜力。
相比之下,Anthropic 的 Claude 被认为具备 ChatGPT 同等水平的智能,其平台潜力却远没有被激发出来。
并不是所有 LLM 追随者都能成功复刻 GPT 模型+ChatGPT+Plugin 路径的。正如前文分析 OpenAI 今天的成就是技术+产品+ GTM 综合的结果。即使如中国般相对独立的区域市场,也需要真正领先的技术能力与战略能力结合才能成功。
写在最后
以上是 OneMoreAI 根据原报告整理的压缩版,报告原文中除了对上文提到的信息有更深入和具体的分析外,也留下了很多问题待进一步研究和讨论。
LLM 行业还在起步阶段,生态仍未稳定,未来充满了不确定性。我们从逆向工程 OpenAI 的思路出发,尝试解释并预测行业最关键玩家的行为,希望建立一个能够对 LLM 生态进行系统性讨论的宏观框架供大家讨论,一起迎接这个历史性的 AI 浪潮。
Reference:
Introducing OpenAI https://openai.com/blog/introducing-openai
Planning for AGI and Beyond https://openai.com/blog/planning-for-agi-and-beyond
Generative models https://openai.com/research/generative-models
Unsurpervised Sentiment Neuron https://openai.com/research/unsupervised-sentiment-neuron
Improving Language Understanding by Generative Pre-Training https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
Language Models are Unsupervised Multitask Learners https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
Language Models are Few-Shot Learners https://arxiv.org/abs/2005.14165
OpenAI LP https://openai.com/blog/openai-lp
Aligning language models to follow instructions https://openai.com/research/instruction-following
Training Language Models to Follow Instructions with Human Feedback https://arxiv.org/abs/2203.02155
ChatGPT https://openai.com/blog/chatgpt
GPT-4 Technical Report https://cdn.openai.com/papers/gpt-4.pdf
https://www.forbes.com/sites/chriswestfall/2023/01/28/educators-battle-plagiarism-as-89-of-students-admit-to-using-open-ais-chatgpt-for-homework/
https://openai.com/blog/chatgpt-plugins
https://www.similarweb.com
Bard https://bard.google.com/
PaLM API https://blog.google/technology/ai/ai-developers-google-cloud-workspace/
LLaMA: Open and Efficient Foundation Language Models https://arxiv.org/abs/2302.13971
Alpaca: A Strong, Replicable Instruction-Following Model https://crfm.stanford.edu/2023/03/13/alpaca.html
Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality https://vicuna.lmsys.org/
Compression for AGI - Jack Rae | Stanford MLSys #76 https://www.youtube.com/watch?v=dO4TPJkeaaU&t=247s
AI Today and Vision of the Future (Ilya Sutskever interviewed by NVIDIA's Jensen Huang) https://youtu.be/ZZ0atq2yYJw
OpenAI Meta-Learning and Self-Play https://www.youtube.com/watch?v=9EN_HoEk3KY
Minds, brains, and programs https://www.cambridge.org/core/journals/behavioral-and-brain-sciences/article/abs/minds-brains-and-programs/DC644B47A4299C637C89772FACC2706A
Mastering the game of Go with deep neural networks and tree search https://storage.googleapis.com/deepmind-media/alphago/AlphaGoNaturePaper.pdf
Highly accurate protein structure prediction with AlphaFold https://www.nature.com/articles/s41586-021-03819-2
Improving alignment of dialogue agents via targeted human judgements
https://arxiv.org/pdf/2209.14375.pdf
https://alphacode.deepmind.com/
Aligning language models to follow instructions https://openai.com/research/instruction-following
Constitutional AI: Harmlessness from AI Feedback https://arxiv.org/pdf/2212.08073.pdf
Evaluating Large Language Models Trained on Code https://arxiv.org/pdf/2107.03374.pdf
GPT-4 Technical Report
https://cdn.openai.com/papers/gpt-4.pdf
https://www.linkedin.com/posts/weights-biases_peter-welinder-of-openai-on-how-they-use-activity-7042149010198974464-28DP
OpenAI Triton
https://github.com/openai/triton
BloombergGPT: A Large Language Model for Finance https://arxiv.org/pdf/2303.17564.pdf
https://fortune.com/2023/03/27/altman-vs-musk-openai-treads-on-teslas-robot-turf-with-investment-in-norways-1x/
https://www.reuters.com/technology/microsoft-talks-invest-10-bln-chatgpt-owner-semafor-2023-01-10/
Technology and wealth inequality
https://blog.samaltman.com/technology-and-wealth-inequality
Introducing Claude
https://www.anthropic.com/index/introducing-claude
Who Owns the Generative AI Platform?
https://a16z.com/2023/01/19/who-owns-the-generative-ai-platform/
本文来自微信公众号:OneMoreAI(ID:OneMoreAI1956),作者:Kiwi
相关推荐
2万字复盘:OpenAI的技术底层逻辑
MIT万字报道:竞争压力裹挟下的OpenAI,理想如何安置?
更强的GPT-4,更封闭的OpenAI
万字深度:A股半导体全景再复盘
沣扬资本杨希:复盘「映翰通」投资逻辑,解析物联网企业成长路径
阿里靠复盘,复出了什么?
万字长文复盘2022:陨落篇
万字复盘2020:8个趋势、3个洞察、1种信仰
创业中,复盘的力量
ChatGPT的底层逻辑与未来边界
网址: 2万字复盘:OpenAI的技术底层逻辑 http://www.xishuta.com/newsview71594.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95067
- 2人类唯一的出路:变成人工智能 20174
- 3报告:抖音海外版下载量突破1 19974
- 4移动办公如何高效?谷歌研究了 19396
- 5人类唯一的出路: 变成人工智 19282
- 62023年起,银行存取款迎来 10229
- 7网传比亚迪一员工泄露华为机密 8346
- 8五一来了,大数据杀熟又想来, 7727
- 9滴滴出行被投诉价格操纵,网约 7350
- 10顶风作案?金山WPS被指套娃 7158



