深度学习三巨头之一Yann LeCun:大语言模型带不来AGI
本文来自微信公众号:极客公园 (ID:geekpark),作者:凌梓郡、Li Yuan,编辑:卫诗婕,头图来自:视觉中国
当今世界,Yann LeCun 、Geoffrey Hinton 以及 Yoshua Bengio 三位科学家并称为深度学习三巨头。值得注意的是,三巨头之中,LeCun 对于 AI 发展所持的态度是最为乐观的。此前在马斯克提出“人工智能给人类文明带来了潜在风险”时,LeCun 曾公开反驳,认为人工智能远未发展到给人类构成威胁的程度。关于 AI 接下来该如何发展,在今天上午于北京举行的 2023 智源人工智能大会上,他发表了名为《走向能够学习、推理和规划的大模型》的演讲,表达了系统的思考。
法国当地时间凌晨四点,LeCun 从法国的家中连线智源大会的北京现场。尽管 OpenAI 的 GPT 路线风头正盛,许多人认为大语言模型将通往 AGI,LeCun 却直言不讳:需要放弃生成模型、强化学习方法这样的主流路线。他认为,基于自监督的语言模型无法获得关于真实世界的知识。尽管语言生成的内容质量一直提升,但是这些模型在本质上是不可控的。对于语言模型的局限性理解,也基于他此前的一个基本观点:人类有许多知识是目前无法被语言系统所触达的。
因此,想让 AI 获得如人一般对真实世界学习、应对和规划的能力,他展示了自己在一年前所发表的论文中提出的架构“自主智能”(autonomous intelligence)。这是由一个配置模块控制整个系统,基于输入信息,进行预测、推理、决策的架构。其中的“世界模块”具有估计缺失信息、预测未来外界状态的能力。

极客公园团队在智源大会现场观看了这场演讲,以下为核心观点精彩摘要以及经过编辑的演讲内容。
LeCun 核心观点精彩摘要:
1. AI 的能力距离人类与动物的能力,还有差距——差距主要体现在逻辑推理和规划,大模型目前只能“本能反应”。
2. 什么是自监督学习?自监督学习是捕捉输入中的依赖关系。训练系统会捕捉我们看到的部分和我们尚未看到的部分之间的依赖关系。
3. 目前的大模型如果训练在一万亿个 token 或两万亿个 token 的数据上,它们的性能是惊人的。我们很容易被它的流畅性所迷惑。但最终,它们会犯很愚蠢的错误。它们会犯事实错误、逻辑错误、不一致性,它们的推理能力有限,会产生有害内容。由此大模型需要被重新训练。
4. 如何让 AI 能够像人类一样能真正规划?可以参考人类和动物是如何快速学习的——通过观察和体验世界。
5. Lecun 认为,未来 AI 的发展面临三大挑战,并由此提出“世界模型(World Model)”。

图片来自:作者提供
以下为演讲全文的部分摘要,经极客公园编辑后发布:
很抱歉我不能亲自到场,已经很久没有去中国了。
今天我将谈一下我眼中的人工智能的未来。我会分享一下 AI 在未来十年左右的方向,以及目前的一些初步结果,但还没有完整的系统。
本质上来说,人类和动物的能力和今天我们看到的AI的能力之间,是有差距的。简单来说,机器学习和人类动物相比并不特别好。AI 缺失的不仅仅是学习的能力,还有推理和规划的能力。
过去几十年来,我们一直在使用监督学习,这需要太多的标注。强化学习效果不错,但需要大量的实验。最近几年,我们更多使用机器自我监督,但结果是,这些系统在某种程度上是专业化和脆弱的。它们会犯愚蠢的错误,它们不会推理和规划,它们只是快速地反应。
那么,我们如何让机器像动物和人类一样理解世界的运作方式,并预测其行动的后果?是否可以通过无限步骤的推理执行链,或者将复杂任务分解为子任务序列来规划复杂任务?
这是我今天想讲的话题。
但在此之前,我想先谈一下什么是自我监督学习?自我监督学习是捕捉输入中的依赖关系。在最常见的范例中,我们遮盖输入的一部分后将其反馈送到机器学习系统中,然后揭晓其余的输入——训练系统会捕捉看到的部分和尚未看到的部分之间的依赖关系。有时是通过预测缺失的部分来完成的,有时不完全预测。
这种方法在自然语言处理的领域取得了惊人的成功(如翻译、文本分类)。最近大模型的所有成功都是这个想法的一个版本。
同样成功的是生成式人工智能系统,用于生成图像、视频或文本。在文本领域这些系统是自回归的。自监督学习的训练方式下,系统预测的不是随机缺失的单词,而是仅预测最后一个单词。系统不断地预测下一个标记,然后将标记移入输入中,再预测下一个标记,再将其移入输入中,不断重复该过程。这就是自回归 LLM。
这就是我们在过去几年中看到的流行模型所做的事情:其中一些来自 Meta 的同事,包括开源的 BlenderBot、Galactica、LLaMA、Stanford 的 Alpaca(Lama 基于 LLaMA 的微调版)、Google 的 LaMDA 、Bard、DeepMind 的 Chinchilla,当然还有 OpenAI 的 ChatGPT 和 GPT-4。如果你将这些模型训练在一万亿个 Token 或两万亿个 Token 的数据上,它们的性能是惊人的。但最终,它们会犯很愚蠢的错误。它们会犯事实错误、逻辑错误、不一致性,它们的推理能力有限,会产生有害内容。
因为它们没有关于基础现实的知识,它们纯粹是在文本上进行训练的。这些系统在作为写作辅助工具、帮助程序员编写代码方面非常出色。但是它们可能会产出虚构的故事或者制造幻觉。
我同事给我开了一个玩笑。他们说,你知道 Yann Lecun(杨立昆)去年发行了一张说唱专辑吗?我们听了一下(AI 根据这个想法生成的假专辑),当然这是不真实的,但如果您要求它这样做,它会这样做。目前的研究重点是,如何让这些模型系统能够调用搜索引擎、计算器、数据库查询等这类工具。这被称为扩展语言模型。
我和我的同事合作撰写过一篇关于扩展语言模型的论文。我们很容易被它们的流畅性所迷惑,认为它们很聪明,但它们实际上并不那么聪明。它们非常擅长检索记忆,但它们没有任何关于世界运作方式的理解。这种自回归的生成,存在一种主要缺陷。
如果我们想象所有可能答案的集合,即标记序列的树(tree),在这个巨大的树中,有一个小的子树对应于给定提示的正确答案。因此,如果我们想象任何产生标记的平均概率 e 都会将我们带出正确答案的集合,而且产生的错误是独立的,那么它们可能会看到 n 的答案的相似度是(1-e)的 n 次方。这意味着会存在一个指数级的发散过程将我们带出正确答案的树。这就是自回归的预测过程造成的。除了使 e 尽可能小之外,没有其他修复方法。
因此,我们必须重新设计系统,使其不会这样做。这些模型必须重新训练。
那么如何让 AI 能够像人类一样能真正规划?我们先来看人类和动物是如何能够快速学习的。
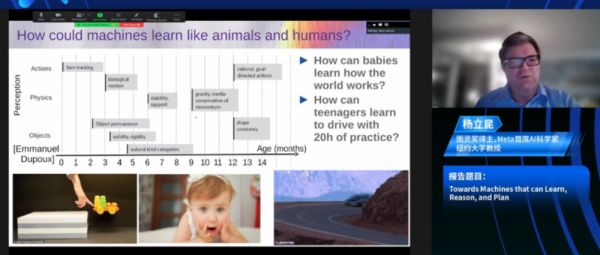
我们看到婴儿在生命的前几个月内掌握了大量关于世界运作方式的基础概念:如物体永恒性、世界是三维的、有机和无机物体之间的区别、稳定性的概念、自然类别的学习以及重力等非常基本的概念。婴儿在 9 个月左右就能会这些。
根据我同事制作的图表,如果您向 5 个月大的婴儿展示下面左下角的场景,其中一个小汽车在平台上,你将小汽车从平台上推下来,它似乎漂浮在空中,5 个月大婴儿不会感到惊讶。但是 10 个月大的婴儿会非常惊讶,因为在此期间,婴儿已经知道了物体不应该停留在空中,它们应该在重力下下落。这些基本概念是通过观察世界和体验世界来习得的。我认为我们应该用机器复制这种通过观察世界或体验世界学习世界运作方式的能力。
我们有流利的系统,可以通过法律考试或医学考试,但我们没有可以清理餐桌并填满洗碗机的家庭机器人,对吧?这是任何孩子都可以在几分钟内学会的事情。但我们仍然没有机器可以接近这样做。
我们显然在当前拥有的 AI 系统中缺少了非常重要的东西。我们远远没有达到人类水平的智能,那么我们该如何做到这一点?实际上,我已经确定了未来几年 AI 面临的三个主要挑战。
首先是学习世界的表征和预测模型,当然可以采用自我监督的方式进行学习。
其次是学习推理。这对应着心理学家丹尼尔·卡尼曼的系统 1 和系统 2 的概念。系统 1 是与潜意识计算相对应的人类行为或行动,是那些无需思考即可完成的事情;而系统 2 则是你有意识地、有目的地运用你的全部思维力去完成的任务。目前,人工智能基本上只能实现系统 1 中的功能,而且并不完全;
最后一个挑战则是如何通过将复杂任务分解成简单任务,以分层的方式运行来规划复杂的行动序列。
所以大约一年前,我发布了一篇论文,是关于我认为未来 10 年人工智能研究应该走向的愿景,你可以去看一下,内容基本上是你们在这个演讲中听到的提议。在我提出的这个系统中,核心是世界模型(World Model)。世界模型可以为系统所用,它可以想象一个场景,基于这样的场景作为依据,预测行动的结果。因此,整个系统的目的是找出一系列根据其自己的世界模型预测的行动,能够最小化一系列成本的行动序列。
(编者注:有关 Lecun 关于世界模型的论述,感兴趣的读者可以自行搜索 Lecun 的这篇论文《A Path Towards Autonomous Machine Intelligence》。)

问答环节 Q & A:
提问人:朱军|清华大学教授,智源首席科学家
Q:生成式模型通常将输出定义为多个选择的概率。当我们应用这些生成模型时,我们通常也希望它们拥有创造力,产生多样化的结果。这是否意味着这些模型实际上无法避免事实错误或逻辑的不一致性呢?即使您拥有平衡的数据,因为在许多情况下,数据会产生冲突的影响,对吗?您之前提到了输出的不确定性,您对此有何看法?
A:我认为,通过保留自回归生成来解决自回归预测模型生成模型的问题是不可行的。这些系统本质上是不可控的。所以,它们将必须被我提出的那种架构所取代,在推理过程中,你需要让系统优化某种成本和某些准则。这是使它们可控、可操纵和可规划的唯一方法。这样的系统将能够计划其回答。
就像我们像现在这样讲话,我们都会计划讲话的过程,怎样从一个观点到另一个观点,怎么解释事物,这些都在你的脑海里。当我们设计演讲时,不是一字一句地即兴发挥。也许在低层次上,我们在即兴发挥,但在高层次上,我们一定是在规划。所以规划的必要性是非常明显的。人类和许多动物都具备规划能力,我认为这是智能的一项重要特征。所以我的预测是,在相对短的几年内,理智的人肯定不会再使用自回归元素。这些系统将很快被放弃,因为它们是无法修复的。
Q:您之后将参与一个辩论,探讨人工智能会不会成为人类生存的威胁。
参会者还有 Yoshua Bengio,Max Tegmark 和 Melanie Mitchell。您能讲讲您届时将阐述什么观点吗?

A:在这场辩论中,Max Tegmark 和 Yoshua Bengio 将站在“是”的一边,认为强大的 AI 系统可能对人类构成存在风险。而我和 Melanie Mitchell 将站在“否”的一边。我们的论点不是说没有风险,而是这些风险虽然存在,但通过谨慎的工程设计可以轻易地加以减轻或抑制。
我对此的论点是,今天问人们是否能够使超智能系统对人类安全,这个问题无法回答,因为我们还没有超智能系统。所以,直到你能基本设计出超智能系统,你才能讨论如何让它变得安全。这就好比你在 1930 年问一位航空工程师,你能使涡喷发动机安全可靠吗?工程师会说,什么是涡喷发动机?因为涡喷发动机在 1930 年还没有被发明出来,对吧?所以,我们处于一种有点尴尬的境地。现在,宣称我们无法使这些系统安全还为时过早,因为我们还没有发明出它们。一旦我们发明了它们,或许就是按照我所提出的设计蓝图,再讨论如何使它们安全也许是值得的。
本文来自微信公众号:极客公园 (ID:geekpark),作者:凌梓郡、Li Yuan,编辑:卫诗婕
相关推荐
深度学习三巨头之一Yann LeCun:大语言模型带不来AGI
图灵奖颁给深度学习三巨头,他们曾是一小撮顽固的“蠢货”
图灵奖颁给深度学习三巨头,他们曾是顽固的“蠢货”
机器学习圣杯:图灵奖得主Bengio和LeCun称自监督学习可使AI达到人类智力水平
2202年了,AI还是不如猫,图灵奖得主Yann LeCun:3大挑战依然无解
神仙打架激辩深度学习:LeCun出大招,马库斯放狠话,机器学习先驱隔空“互怼”
终于,Yann LeCun发文驳斥Gary Marcus:别把一时的困难当撞墙
深度学习三巨头:AI需要新硬件,万亿突触神经网络或成可能
语言与大模型:通向AGI之路
图灵奖得主LeCun及7位华人博士当选美国科学院2021院士
网址: 深度学习三巨头之一Yann LeCun:大语言模型带不来AGI http://www.xishuta.com/newsview78151.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95273
- 2人类唯一的出路:变成人工智能 21579
- 3报告:抖音海外版下载量突破1 21553
- 4移动办公如何高效?谷歌研究了 20718
- 5人类唯一的出路: 变成人工智 20712
- 62023年起,银行存取款迎来 10377
- 7五一来了,大数据杀熟又想来, 8945
- 8网传比亚迪一员工泄露华为机密 8569
- 9滴滴出行被投诉价格操纵,网约 8567
- 10顶风作案?金山WPS被指套娃 7258



