中欧AI立法同期突破:为ChatGPT设置“红绿灯”?
本文来自微信公众号:财经E法 (ID:CAIJINGELAW),作者:杨柳,编辑:郭丽琴,头图来自:视觉中国
伴随人工智能大语言模型ChatGPT在今年的火爆出圈,中欧均在AI领域的立法上取得突破性进展。
当地时间6月14日,欧盟《人工智能法案》(下称“欧盟法案”)以压倒性多数(499票赞成、28票反对和93票弃权)获得欧洲议会表决通过,为后续法案最终条款的磋商铺平道路。该法案已经酝酿约两年,最终条款预计在年底前达成,很可能成为全球首部落地的综合性人工智能立法。
这部法案制定了一整套针对人工智能使用的严格规则,遵循不同风险等级分类监管的思路。其核心落在严格限制面部识别软件的使用(如禁止公共场所面部识别),并要求ChatGPT这类人工智能系统的制造商披露训练大模型所使用的版权数据信息。
欧盟试图通过立法向全球输出AI领域的治理框架和价值观。负责此项立法工作的欧洲议会议员兼联合报告员德拉戈斯·图多拉什(Dragoş Tudorache)就评论称,欧盟法案将为全球人工智能的发展和治理定下基调,确保这项将从根本上改变社会的技术,能够不断发展并遵循欧洲法治的价值观。
6月7日,中国国务院办公厅印发2023年度立法工作计划,其中一句话引发关注:“预备提请全国人大常委会审议人工智能法草案”。此前,中国监管部门多采取“小而灵”的立法范式,针对性地回应特定人工智能领域的治理难题。
一名了解人工智能立法动向的“红圈律所”合伙人向财经E法表示,无论是国际形势还是内部产业发展的压力,中国对通用的综合性人工智能立法均已是箭在弦上。“这不仅是个法律问题,也是个经济问题。”
但暨南大学特聘教授孙远钊则认为,欧盟法案实际执行情况还有待观察,因为“难度会相当大”。此前,欧盟法案已经引发美国高科技企业的反弹。5月底,OpenAI首席执行官阿尔特曼(Sam Altman)警告说,如果无法遵守欧盟法案的规定,OpenAI可能会停止在欧盟的运营。因为按照法案的表述,可能会将OpenAI旗下的大模型认定为“高风险”,从而要求企业负担更多的安全要求。
欧盟法案的参考价值
欧盟已经对外公布了一部长达144页、拥有上千条修正条文的谈判授权草案。中国若推进立法,可以从中借鉴哪些有效经验?
仅从时间线上看,欧盟的立法速度,已经领先其他国家和地区一大步。
按照欧盟立法程序,法案得到欧洲议会议员认可后,欧洲议会、欧盟理事会和欧盟委员会将展开“三方会谈”,敲定最终条款。最终条款预计在年底前达成。当法案的最终版本颁布,受影响的公司和组织将有约两年的宽限期,以了解如何遵守新的规定。
在中国,按照《立法法》的规定,国务院向全国人大常务委员会提出法律案后,由委员长会议决定列入常务委员会会议议程,或者先交有关的专门委员会审议、提出报告,再决定列入常务委员会会议议程,后续一般需经历三次审议。
一个可参考的时间表是,2017年7月,国务院发布的《新一代人工智能发展规划》提到“三步走”战略,其中第二步展望,到2025年人工智能基础理论实现重大突破,部分技术与应用达到世界领先水平,同时初步建立人工智能法律法规、伦理规范和政策体系,形成人工智能安全评估和管控能力。
一位接近监管部门的法学专家表示,欧盟人工智能立法的参考价值或许并不那么高,因为中国人工智能监管需要立足于本国国情,考虑全球战略竞争和综合国力提升,和欧盟相比有不同的侧重。
孙远钊认为,欧盟在AI领域的立法,是个“相当谨慎的第一步尝试”。他基本赞同欧盟的一些做法:一方面,把风险等级先列出,设立相对明确的注意义务和责任;另一方面,兼顾创新发展与社会安全,不冒进,却设置栅栏,“容许子弹只能在设定的范围内继续再飞一会儿”。
但孙远钊也指出,欧盟法案实际的执行效果究竟如何,还有待观察,“因为难度会非常大,灰色地带也会不小,因为同样的工具(人工智能)可以从事多种不同的用途”。
“从很多方面,人工智能与核能开发很像,都是极厉害的双面刃。用得好可以造福人群,稍有差池也可酿成巨灾。”孙远钊表示。
结合欧盟已经公布的草案,前述“红圈所”合伙人则认为,中国即将展开的综合性人工智能立法有三大难点待解决:
确立人工智能发展遵循的原则。人工智能如何发展,会涉及到一个国家或民族价值观的底层,立法需要将这种价值观和人工智能发展耦合起来。
兼顾安全与发展,具体体现为责任主体的划分。欧盟法案中,便分别确立了人工智能系统开发提供者、部署使用者、引入欧盟以外人工智能系统的进口者、分发者的责任义务。
拓展监管工具。中国的监管工具体系目前只有算法备案和算法安全评估,域外的算法认证、“监管沙盒”等做法也值得尝试。
比如,欧盟法案提出了高风险人工智能“CE合格标识”制度,获得该标签则表明人工智能系统符合法案对高风险人工智能的规制要求。给予企业尤其是中小企业和初创企业合格标识,相当于监管部门为产品的基本合规性背书,让企业有个定心丸。但无论欧盟还是中国,现在仍依靠企业自行提交的技术文件、法律文件进行监管,监管部门缺少技术能力进行实质性的技术监管。
以下,是财经E法对欧盟法案的梳理,侧重于可供中国参考的详细内容。
一、“风险金字塔”式分级监管
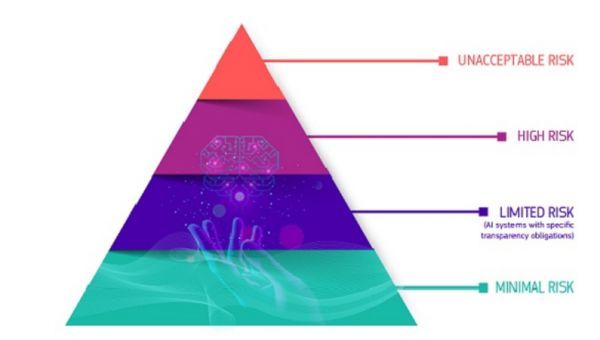
人工智能四个风险等级,来源:欧盟委员会官网
欧盟法案的整体监管架构,将人工智能应用按风险等级分为四类,类似于一个“风险金字塔”,分别建立相应的风险防范机制。
最极端的一类是具有“不可接受风险”的人工智能系统或应用,比如被认为对人们的安全、日常生活和基本权利构成明显威胁,将被完全禁止使用。目前法案相比最初版本的一大显著变化,就是大幅修改负面清单,在第二编中纳入对“人工智能系统的侵入性和歧视性使用”的一揽子禁令。
这些禁令涵盖六类人工智能系统:1. 公共场所的“实时”远程生物特征识别系统;2. “事后”远程生物特征识别系统,但执法机关起诉严重犯罪且取得司法授权的除外;3. 使用性别、种族、民族、公民身份、宗教、政治取向等敏感特征的生物识别分类系统;4. 基于分析、位置或犯罪前科的预测性警务系统;5. 执法、边境管理、工作场所和教育机构中的情绪识别系统;6. 未经相关人员允许,从社交媒体或视频监控中抓取生物识别数据以创建或扩大面部识别数据库。
欧洲议会议员兼联合报告员布兰多·伯尼菲(Brando Benifei)解释说,限制上述人工智能系统的使用,其目的是避免一个被人工智能控制的社会。“我们认为这些技术可以用来代替好的东西,也可以用来做坏事,风险太高了”。
第二类是“高风险”人工智能应用程序,涵盖人工智能在涉及安全和人权的多个领域中的使用,例如执法、司法、教育、就业、出入境等。当前法案扩大了高风险领域的分类,将对人们健康、安全、基本权利或环境构成重大风险的情形纳入其中。另外,影响政治竞选中选民的人工智能系统,以及根据欧盟《数字服务法》拥有超过4500万用户的超大型社交媒体平台的推荐系统,也被列入高风险名单。
高风险的人工智能系统在投放市场之前,将承担严格的法定义务,需要具备更高的透明度和准确性,比如为系统提供高质量的数据集,以及采取适当的人为监督措施,以最大限度地减少风险和歧视性结果。
针对高风险人工智能,法案还引入一项全新要求,人工智能系统部署者有义务进行用户基本权利影响评估,考虑到对边缘化及弱势群体和环境的潜在负面影响等。法案同时还要求欧盟委员会与成员国合作,创建一个高风险人工智能系统的公共数据库,以解释这些人工智能系统在欧盟的部署地点、时间和方式,便于欧盟公民可以了解他们何时以及如何受到该技术的影响。
法案要求:“这个数据库应该可以免费和公开访问、易于理解和可由机器读取。该数据库还应该方便用户使用且易于导航的,至少具有搜索功能,允许公众在数据库中搜索特定的高风险系统及其位置、风险类别和关键字。”
第三类是“风险有限”的人工智能应用程序,具有特定透明度义务,使用户能意识到是在与人工智能系统进行交互操作。第四类为“极小风险”的应用程序,基本上不受监管,比如垃圾邮件过滤器等人工智能应用程序。
对于违规者,欧盟法案设定了高额处罚,最高将被处以4000万欧元或上一财政年度全球年总营业额的7%。对于谷歌、微软这些全年总营收数千亿美元的科技巨头而言,若严格参照规定,罚款可能达数十亿乃至上百亿美元。
突出技术规制的同时,欧盟法案也试图兼顾促进产业创新。法案第1条就明确,支持对中小企业和初创企业的创新举措,包括建立“监管沙盒”等措施,减少中小企业和初创企业的合规负担。
按照法案的解释,所谓“监管沙盒”,即一个受监督、可控的安全空间,让企业尤其是中小企业和初创企业进入“沙盒”,在监管机构的严格监督下,积极参与创新人工智能系统的开发和测试,其后将这些人工智能系统投放到服务市场。如果开发测试过程中发现重大风险,则应理解并加以缓解,倘若不能缓解,便应暂停开放测试。
5月中旬欧盟法案在欧洲议会两个下属委员会的投票结束后,布兰多·伯尼菲曾表示:“我们即将制定具有里程碑意义的立法,必须经受住时间的挑战,至关重要的是要建立公民对人工智能发展的信任。我们相信这部法律会平衡基本权利的保护,并为企业提供法律确定性,刺激欧洲创新。”
但立法对人工智能市场的影响尚不清晰。
6月1日,欧洲智库Digital Europe对九家中小企业和初创科技企业深度访谈的报告显示,有大约三分之二的受访者对欧盟法案仅仅是“有点熟悉”,甚至“不熟悉”。许多受访者提到的一个关键点,法案存在很多不够清晰的地方,尤其是不确定它们的产品应落入何种风险等级。还有受访者担心,法案的实施可能会使在欧洲布局高风险人工智能模型变得更加困难,促使国际投资者回避为高风险的欧洲人工智能公司提供资金。
二、给ChatGPT等大语言模型施加额外要求
如何规范引导通用人工智能技术的发展,是欧盟法案立法之初未曾预料到的一大“变数”。
人工智能大模型的浪潮席卷,带来数据合规、版权合规、虚假信息治理等全新治理难题。
5月16日,OpenAI首席执行官阿尔特曼接受美国参议院司法委员会质询时,就人工智能大模型监管提出建议,可以参照国际原子能机构建立人工智能监管的国际组织,用来为人工智能制定标准。这一倡议于近日得到联合国秘书长古特雷斯应和。当地时间6月12日,古特雷斯表示支持参照国际原子能机构,建立一个人工智能机构的设想。他还宣布,计划在今年年底前启动一个高级人工智能咨询机构,定期审查人工智能治理安排。
这次获得通过的欧盟法案增加了条款以涵盖像ChatGPT这样的基础模型,施加了强制性的透明度要求,使这些基础模型承担一些和高风险系统相同的额外要求。
具体而言,必须披露内容是由人工智能生成的,防止模型生成非法内容,以及发布受版权法保护的训练数据的使用情况摘要。公开训练数据来源,将使内容创作者知道他们原创内容是否已被用于训练人工智能大模型,这可能会驱使创作者因人工智能系统使用他们的作品而寻求报酬。
4月27日,有媒体援引消息人士称,一些欧盟委员会成员最初提议,完全禁止将受版权保护的材料用于训练生成式人工智能模型,但后来改换为施加透明度要求的方案。
无数作品“喂养”了人工智能大模型内容生成,但这一利用是否属于版权法豁免的合理使用饱受争议。
2023年1月,三位艺术家代表所有相同境遇的人,向美国加州地方法院提起集体诉讼,指控Stability AI、Midjourney、DeviantArt三家图像生成器公司侵犯了他们的版权,却未给予任何补偿。同月,图片公司Getty Images 在伦敦高等法院对 Stability AI 提起法律诉讼,声称 Stability AI没有向 Getty Images寻求任何许可,非法复制和处理了数百万受版权保护的图像,侵犯了Getty Images所拥有作品的版权。
面对创作者对人工智能快速发展的担忧,5月17日,美国众议院法院、知识产权和互联网司法小组委员会举行“生成式人工智能技术与版权法”主题听证会,其中讨论的内容涉及受版权保护的作品在生成人工智能模型训练中使用。
国际知名律所Latham & Watkins律师事务所合伙人、前美国版权局总法律顾问赛达摩(Sy Damle)在书面证词中指出,合理使用原则是平衡人工智能领域竞争利益的最佳方式。他警示说,虽然某些团体要求为使用版权内容训练人工智能模型付费,但人工智能开发者不可能与每个版权权利人协商并获得许可。若采用法定或集体许可制度,也是一项糟糕的政策,比如庞大的许可使用费有可能给人工智能公司带来巨大的财务负担,这些公司要么破产,要么被挤出市场。
而日本政府最近的态度表明,不会对人工智能训练中使用的数据实施版权保护。日本文部科学大臣长冈惠子4月底在一次会议上表示:“无论方法如何,无论内容如何,该作品都可以用于‘信息分析’。”“信息分析”是日本《著作权法》合理使用制度的情形之一。
中国方面,在版权内容的训练使用上,4月中旬发布的《生成式人工智能服务管理办法(征求意见稿)》给出的初步态度为:用于生成式人工智能产品的预训练、优化训练数据,不得含有侵犯知识产权的内容。
但在前述接近监管部门的法学专家看来:“为了尽可能让训练数据集更加充分和高质量,人工智能立法有必要放开训练数据输入端的知识产权限制,对于大模型输出端的知识产权侵权,则可以暂时采取一种相对包容审慎的姿态。”
本文来自微信公众号:财经E法 (ID:CAIJINGELAW),作者:杨柳,编辑:郭丽琴
相关推荐
ChatGPT的这个弱点,说明人与AI没有本质区别
ChatGPT警示:不同的中美AI故事
ChatGPT插件重磅上线,不只“联网”,还将打造强大AI生态
押宝ChatGPT,微软“笑到最后”
运行ChatGPT太烧钱,微软为省钱已秘密自研AI芯片4年
ChatGPT连夜登陆iOS,AI战火烧到移动端
王坚院士:世界上为什么有红绿灯?
微软盯上ChatGPT,一场关于生成式AI的豪赌
年轻人的新玩具:AI佛祖,ChatGPT如何“普度众生”?
ChatGPT生成的内容,是否享有版权?
网址: 中欧AI立法同期突破:为ChatGPT设置“红绿灯”? http://www.xishuta.com/newsview78993.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95131
- 2人类唯一的出路:变成人工智能 20593
- 3报告:抖音海外版下载量突破1 20434
- 4移动办公如何高效?谷歌研究了 19775
- 5人类唯一的出路: 变成人工智 19721
- 62023年起,银行存取款迎来 10277
- 7网传比亚迪一员工泄露华为机密 8408
- 8五一来了,大数据杀熟又想来, 8094
- 9滴滴出行被投诉价格操纵,网约 7717
- 10顶风作案?金山WPS被指套娃 7188



