量子计算的chatGPT时刻即将来临?
本文来自微信公众号:返朴 (ID:fanpu2019),作者:金贻荣(北京量子信息科学研究院),原文标题:《IBM量子计算最新进展:量子计算的chatGPT时刻即将来临?》,题图来源:视觉中国
2023年6月,IBM量子部与加州大学伯克利分校、日本理研、劳伦斯伯克利国家实验室等合作单位在Nature发表一篇封面论文。他们通过“错误缓解”方法,在127量子比特的处理器上准确获得复杂量子线路运行结果,在强纠缠区间,这一线路已经无法用经典计算机进行蛮力模拟。不少人认为,这是量子计算(机)领域内的又一里程碑进展。那么,什么是错误缓解?IBM做到了什么,还没做到什么?本文将试图给出解读。
2022年底,我受《物理》期刊之邀,译过一篇IBM量子部门副总裁Jay M. Gambetta的专访,英文标题为“Turning a Quantum Advantage”。如何信雅达地翻译这个标题,着实让我费了些脑筋,最后我和编辑杨老师一致选择了《点亮量子优势》(参见《点亮量子优势丨专访IBM量子部量子部副总裁》)。俗话说得好,自古评论区出才子,读者们如果有更好的译法,欢迎打到评论区。
翻译的时侯,我就为Gambetta的一些言论感到凛然。一方面是他提到的一些数字,包括退相干时间,他说已经达到了100毫秒且即将达到300毫秒,我一度认为是记者搞错了;以及两比特门保真度,已经达到99.9%,并将在23年底达到99.99%。我是做量子硬件的,这两个数字就足以震撼我了,而后面的内容则更令人惊叹。
首先,他说道,“采用更聪明的方法来做事,将比堆指标更重要”。换句话说,未来能否实现量子计算优势,光靠不断提升技术指标——比如比特数、退相干时间、门保真度等——是不够的,我们需要从架构层面去思考如何扩展、如何工程化,引入新的方法来应对量子计算机所不可避免的错误,等等。
其次,提到量子纠错的时候,他说他们正在进行错误缓解方面的方法研究,针对有代表性的错误模型构建大量的线路实例,再对这些线路演化结果进行采样,通过统计学方法对整个量子系统的错误行为进行学习,以此来给出一个量子线路的无错估计。假如这个无错估计的准确率不断趋近于1,那我们不就相当于实现了量子纠错?在这样的思路下,量子纠错将不再是一个跨越式的艰巨挑战(参见《量子计算的下一个超级大挑战》),而变成了一个渐进式进程,如同徒步登山,一步虽小,然夕阳过处,回望或已是山巅。
时隔半年,IBM在Nature上发表了题为“前容错量子计算的效用证据(Evidence for the utility of quantum computing before fault tolerance)”的论文,在学界和工业界瞬间引起很大反响。100+量子比特、无需量子纠错、超越经典计算、新里程碑,这些词汇无不牢牢抓住读者的眼球,或许这真是自Google的“量子霸权”以来量子计算发展的又一高光时刻了吧。仔细读了一遍论文,脑中回想起Gambetta专访中的一些观点,我有些凝神:Gambetta已经将论文中的思想清晰表达过了,且半年前我就译成中文介绍给国内读者。此时论文一出震惊全场,所有人方惊坐而起,原来量子计算还可以这样玩……

IBM成果登上Nature 6月15日刊封面(图片来源:Nature)
无论如何,我还是希望尽可能以自己的专业知识,以尽量冷静的态度来解读一下这项工作。这次,IBM的研究者和合作者们在127位的量子处理器上演示了一个二维横场伊辛(Ising)模型(与量子芯片具有相同的拓扑连接)的Trotter展开时间演化[注1],通过零噪声外推(ZNE)错误缓解方法,对演化结果作出了“准确”[注2]的零噪声外推估计。整个线路涉及到127个量子比特,最多60层两比特门,共2880个CNOT门。在强纠缠情况下,经典的张量网络近似方法已经无法给出正确的结果,换句话说,已经超出了经典蛮力模拟的能力。
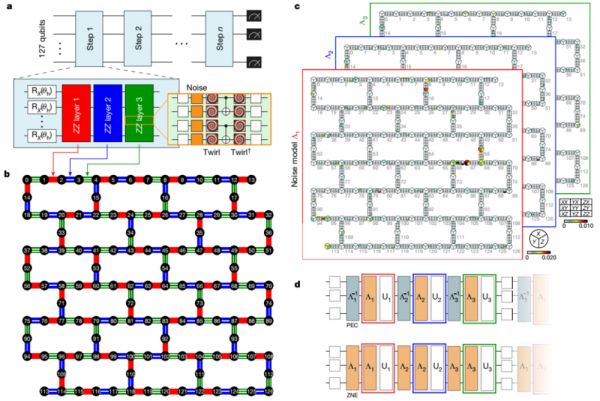
在127比特量子处理器上实现二维横场Ising模型的Trotter时间演化(a, b),以及如何标定整个系统中的错误(c, d)(图片来源:参考资料[1])
文中对量子优势做了一番解释:量子优势可分两步来实现。首先在现有的量子硬件设施上实现超越经典蛮力模拟能力的准确计算,然后在此基础上找(有价值的)问题,实现问题相关量子线路的准确估计(这里我用“估计”而不是计算,因为在含噪声量子线路上,所能给出的永远是统计性结果)。论文涉及的工作算是完成了第一步,因此严格来说并没有实现量子优势。
不过,这一工作相对于Google的“量子霸权”仍前进了一步。倒不是因为比特数更多、线路深度更大、两比特门更多,而是当年Google所执行的随机线路采样给出的保真度极低,而本次IBM的工作,通过错误缓解方法,能够准确地给出一个复杂量子线路的有偏估计[注3]。这就为含噪声量子计算机的效能给出了很强的预期,只要再往前一步,将这次所用到的二维横场伊辛模型演化线路换成一个有价值问题相关的量子线路,尽管这一步依旧很难,量子优势就真的确立了。
那这个错误缓解方法是何方神技,能化腐朽为神奇呢?要知道100+比特规模,60层线路,即便操控和读取的平均保真度都达到了99%以上,得到正确结果的概率也几乎为零。IBM用到了一种叫“零噪声外推”的方法。具体来说,研究人员采用了所谓稀疏Pauli-Lindblad模型,对系统错误进行学习;通过调节其中的参数,可以实现不同的噪声增益G,对大量不同增益下的噪声线路实例进行采样并计算其期望值,进一步,再通过不同噪声增益下的期望值去外推G=0(也就是无噪声的情况)时的期望。这样一来,就相当于推出无错情况下的结果了。学过数值计算的读者大概会知道,相比内插,外推很多时候是不靠谱的,特别在距离真值点较远时。为此,IBM测试了指数外推和线性外推两种方法,并与可经典模拟的特定情况(当线路中所有的门都变成Clifford门时)做了量子-经典对比验证,结果是高度一致的,这也是IBM声称这一方法能给出准确计算结果的底气所在。
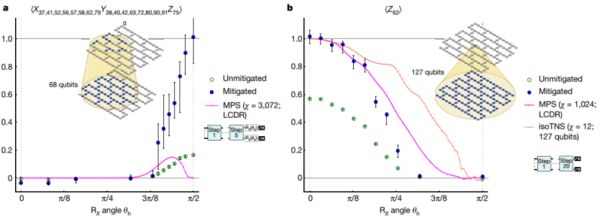
蓝色点为错误缓解后的数据点,绿色为没有做错误缓解的数据点。粉色、橘色线则分别是采用MPS、isoTNS两种张量网络近似方法的计算结果。(图片来源:参考资料[1])
此外,研究人员同时将量子计算机的运行时效与张量网络方法进行了对比。实际上,张量网络在应对深层线路时已无法给出准确的期望值。另一方面,执行同一个线路,张量网络方法获得一个数据点的运行时间分别是8小时和30小时(对应两种演化模型),量子的运行时间则分别是4小时和9.5小时。而这些时间中,真正的量子处理器运行时间只有5分零7秒,且可以通过降低量子比特重置时间来进一步降低运行时间。换言之,量子计算机的运行时效仍有巨大的提升空间。
当然,错误缓解方法是有代价的。零噪声外推相比之前提出的概率性错误消除,在采样开销上已经大幅降低,能够应对100+量子比特规模的复杂量子线路。但以目前透露的消息来看,这种开销随着量子系统规模的增大,仍是指数级增长的,未来更大规模的量子处理器如何高效地进行错误缓解,仍存在挑战。
这一方法的成功验证,就像是照进含噪声量子计算时代的一束光,要让量子计算形成生产力,还有大量的工作要做。一方面我们需要进一步提升量子硬件的性能,文中提到两比特门保真度需要有“数量级”提升,而运行速度也要求大幅提升;另一方面,如何针对比如现在关注度较高的启发式量子算法,包括量子化学计算、近似优化等,进一步验证噪声缓解/消除算法的有效性,也是亟待研究的。
回来再说一下Gambetta的专访,在问到量子计算何时能打败经典计算时,他说了一段令我敬佩的话。他说,与其区分经典和量子,并将二者对立,期待一个量子打败经典的时刻,不如站在一个更一般的角度,将二者统一。计算就是计算。实际的情况是,量子计算需要大量的经典计算辅助,上面提到的错误缓解方法,就是一个典型的例子。我们真正追求的,是解决复杂问题的运行时效,经典辅助量子,量子反过来帮助经典,二者本就是难以区分的统一体。我们需要站在更高的视角去看待量子计算。
最后值得一提的是,优质的量子资源是极其宝贵的。IBM的工作是在一个代号为“ibm_kyiv”的量子云平台上完成的,所用的芯片为“Eagle_r3” 127量子比特处理器。这个处理器的退相干时间T1和T2的中位数分别为288微秒和127微秒,达到了前所未有的水平。临近比特之间的CNOT门通过交叉共振相互作用(Cross-Resonance,简称CR)校准实现。得益于高的退相干时间和其他性能,两比特门操控保真度的中位数超过了99%,读取保真度中位数也超过了99%。这是错误缓解方法得以收敛的重要硬件条件。量子硬件的进一步发展固然要依靠核心的硬件团队来推进,但如何发挥这些有噪声的量子硬件效能,则需要广泛的智力参与,需要来自数学、统计、计算、信息学、软件等多学科的人才共同参与。而鼓励这种广泛的高智力协同创新的最好方式,就是将最好的量子资源共享出去——通过量子云计算平台,IBM一直就是这么做的。
遗憾的是,这些顶尖的量子计算资源对中国已经不开放了,而好消息则是我们自己的100+规模量子计算云平台已经推出,并且对全球开放!随着国内越来越多的人参与其中,随着量子应用需求的预期不断增强,相信属于中国的量子优势“临界时刻”定会加速到来。
注释
[1] Trotter意为小步跑,在这里是指将量子系统的时间演化近似地拆分成很多小步骤,以便处理复杂量子系统的演化问题。
[2] “准确”打上了引号,是因为线路运行结果只有在某些特定情况下是可模拟的,在强纠缠区间无法蛮力模拟,而采用张量网络方法得到的也是近似结果,不能作为计算结果的经典验证。总而言之,强纠缠区间实验结果的准确性,是根据可模拟区域的经典验证推断的。
[3] 有偏估计(biased estimate)是指由样本值求得的估计值与待估参数的真值之间有系统误差,其期望值不是待估参数的真值。
参考资料
1. Kim,Y., Eddins, A., Anand, S. et al. Evidence for the utility of quantum computing before fault tolerance. Nature 618,500–505 (2023).
2. Quafu量子云平台:quafu.baqis.ac.cn;
3. 国盾量子计算云平台:quantumctek-cloud.com
本文来自微信公众号:返朴 (ID:fanpu2019),作者:金贻荣(北京量子信息科学研究院)
相关推荐
量子计算的chatGPT时刻即将来临?
一文读懂:有关量子计算的十个问题
Google“量子优越性”论文正式发表,量子计算到底是什么?
量子计算的到来,会引发怎样的革命?
国产量子计算机长这模样 中国第一家量子计算公司出品
量子计算初创公司「IonQ」完成 5500 万美元融资,计划开发 ToB 的商用量子计算平台
未来之争:量子计算争夺战
AI机器人的ChatGPT时刻还有多远?
紧跟谷歌微软步伐,亚马逊在量子计算领域加速布局
只谈“量子霸权”不谈量子计算到底能干啥的,都是耍流氓
网址: 量子计算的chatGPT时刻即将来临? http://www.xishuta.com/newsview82110.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95178
- 2人类唯一的出路:变成人工智能 20885
- 3报告:抖音海外版下载量突破1 20771
- 4移动办公如何高效?谷歌研究了 20054
- 5人类唯一的出路: 变成人工智 20036
- 62023年起,银行存取款迎来 10307
- 7网传比亚迪一员工泄露华为机密 8456
- 8五一来了,大数据杀熟又想来, 8338
- 9滴滴出行被投诉价格操纵,网约 7960
- 10顶风作案?金山WPS被指套娃 7213



