650亿参数大模型预训练方案开源可商用,LLaMA训练加速38%,来自明星开源项目
650亿参数大模型的预训练方案,发布即开源。
训练速度较传统方案提升38%。
这就是由Colossal-AI最新发布的类LLaMA基础大模型预训练方案。

要知道,在“百模大战”背景下,谁拥有自家大模型,往往被视为核心竞争力。
在这个节点下,愿意开源大模型的公司少之又少。
但自己从头训练一个大模型,对技术、资金都有很高要求。
由此,Colossal-AI最新的开源动作,可以说是应时势所需了。
并且它还不限制商业使用,开箱即用仅需4步。
具体项目有哪些内容?一起往下看~
01 32张A100/A800即可使用
实际上,自从Meta开源LLaMA后,掀起了一波微调项目热潮,如Alpaca、Vicuna、ColossalChat等都是在其基础上打造的。

但是LLaMA只开源了模型权重且限制商业使用,微调能够提升和注入的知识与能力也相对有限。
对于真正想要投身大模型浪潮的企业来说,训练自己的核心大模型非常重要。
开源社区也此前已献了一系列工作:
RedPajama:开源可商用类LLaMA数据集(无训练代码和模型)
OpenLLaMA:开源可商用类LLaMA 7B/13B模型,使用EasyLM基于JAX和TPU训练
Falcon:开源可商用类LLaMA 7B/40B模型(无训练代码)
但这些都还不够,因为对于最主流的PyTorch+GPU生态,仍缺乏高效、可靠、易用的类LLaMA基础大模型预训练方案。
所以Colossal-AI交出了最新的开源答卷。
仅需32张A100/A800,即可搞定650亿参数类LLaMA大模型预训练,训练速度提升38%。
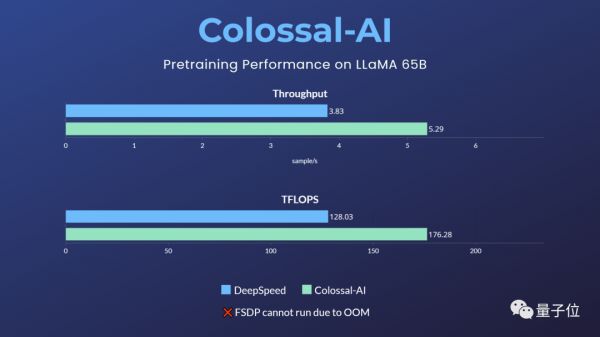
而像原生PyTorch、FSDP等,则因显存溢出无法运行该任务。
Hugging Face accelerate、DeepSpeed、Megatron-LM也未对LLaMA预训练进行官方支持。
02 开箱即用、4步搞定
而这一项目真正上手起来也很简易。共有四步:
1、安装Colossal-AI
2、安装其他依赖项
3、数据集
4、运行命令
具体代码如下:
第一步、安装Colossal-AI。
git clone -b example/llama https://github.com/hpcaitech/ColossalAI.gitcd ColossalAI# install and enable CUDA kernel fusionCUDA_EXT=1 pip install .
第二步、安装其他依赖项。
cd examples/language/llama# install other dependenciespip install -r requirements.txt# use flash attentionpip install xformers
第三步、数据集。
默认数据集togethercomputer/RedPajama-Data-1T-Sample将在首次运行时自动下载,也可通过-d或—dataset指定自定义数据集。
第四步、运行命令。
已提供7B和65B的测速脚本,仅需根据实际硬件环境设置所用多节点的host name即可运行性能测试。
cd benchmark_65B/gemini_autobash batch12_seq2048_flash_attn.sh
对于实际的预训练任务,使用与速度测试一致,启动相应命令即可,如使用4节点*8卡训练65B的模型。
colossalai run --nproc_per_node 8 --hostfile YOUR_HOST_FILE --master_addr YOUR_MASTER_ADDR pretrain.py -c '65b' --plugin "gemini" -l 2048 -g -b 8 -a
如果使用Colossal-AI gemini_auto并行策略,可便捷实现多机多卡并行训练,降低显存消耗的同时保持高速训练。
还可根据硬件环境或实际需求,选择流水并行+张量并行+ZeRO1等复杂并行策略组合。
其中,通过Colossal-AI的Booster Plugins,用户可以便捷自定义并行训练,如选择Low Level ZeRO、Gemini、DDP等并行策略。
Gradient checkpointing通过在反向传播时重新计算模型的activation来减少内存使用。
通过引入Flash attention机制加速计算并节省显存。用户可以通过命令行参数便捷控制数十个类似的自定义参数,在保持高性能的同时为自定义开发保持了灵活性。
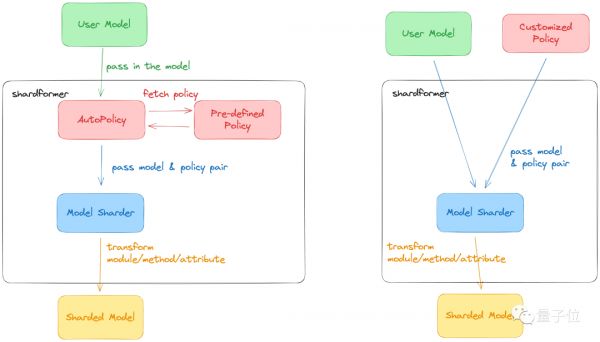
Colossal-AI最新的ShardFormer极大降低了使用多维并行训练LLM的上手成本。
现已支持包括LLaMA的多种等主流模型,且原生支持Huggingface/transformers模型库。
无需改造模型,即可支持多维并行(流水、张量、ZeRO、DDP等)的各种配置组合,能够在各种硬件配置上都发挥卓越的性能。
03 Colossal-AI:大模型系统基础设施
带来如上新工作的Colossal-AI,如今已是大模型趋势下的明星开发工具和社区了。
Colossal-AI上述解决方案已在某世界500强落地应用,在千卡集群性能优异,仅需数周即可完成千亿参数私有大模型预训练。
上海AI Lab与商汤等新近发布的InternLM也基于Colossal-AI在千卡实现高效预训练。
自开源以来,Colossal-AI多次在GitHub热榜位列世界第一,获得 GitHub Star超3万颗,并成功入选SC、AAAI、PPoPP、CVPR、ISC等国际 AI 与HPC顶级会议的官方教程,已有上百家企业参与共建Colossal-AI生态。

它由加州伯克利大学杰出教授 James Demmel 和新加坡国立大学校长青年教授尤洋领导开发。
Colossal-AI基于PyTorch,可通过高效多维并行、异构内存等,主打为AI大模型训练/微调/推理的开发与应用成本,降低GPU需求等。
其背后公司潞晨科技,近期获得数亿元A轮融资,已在成立18个月内已迅速连续完成三轮融资。
本文来自微信公众号“量子位”(ID:QbitAI),作者:关注前沿科技,36氪经授权发布。
相关推荐
650亿参数大模型预训练方案开源可商用,LLaMA训练加速38%,来自明星开源项目
度小满开源千亿参数金融大模型“轩辕”
Meta连甩AI加速大招!首推AI推理芯片,AI超算专供大模型训练
AI画画模型成本被打下来了,预训练成本直降85%,微调只需单张RTX 2070,这个国产开源项目又上新了
万字长文:大模型训练避坑指南
知乎发布最新智能应用“搜索聚合”,面壁智能开源大模型CPM-Bee 10b
OpenAI即将开源新模型,但不是最先进的那个
微信开源「派大星」:4000元游戏电脑能带动7亿参数GPT
中国最强AI研究院的大模型,为何迟到了
中国最强AI研究院的大模型为何迟到了
网址: 650亿参数大模型预训练方案开源可商用,LLaMA训练加速38%,来自明星开源项目 http://www.xishuta.com/newsview83422.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95228
- 2人类唯一的出路:变成人工智能 21183
- 3报告:抖音海外版下载量突破1 21148
- 4移动办公如何高效?谷歌研究了 20339
- 5人类唯一的出路: 变成人工智 20338
- 62023年起,银行存取款迎来 10336
- 7五一来了,大数据杀熟又想来, 8596
- 8网传比亚迪一员工泄露华为机密 8505
- 9滴滴出行被投诉价格操纵,网约 8215
- 10顶风作案?金山WPS被指套娃 7230



