微信翻译闹笑话蔡徐坤躺枪,AI翻译为何总“翻车”?
编者按:本文来自微信公众号“ AI前线”(ID:ai-front),作者 AI前线小组,36氪经授权发布。
昨天,有人发现微信的翻译功能出现 bug,翻译质量让人哭笑不得,比如把流量明星们的名字翻译成“傻蛋”等风马牛不相及的字眼。对此,微信团队做出回应,称微信翻译引擎出现误翻问题,现正在修复。经 AI 前线测试,截至发稿时,微信的翻译功能还未恢复正常。
昨天,微信翻译出现故障,得出了很多让人啼笑皆非的翻译结果。比如明星们的名字被翻译成各种风马牛不相及的字眼,Cai Xukun 被翻译成“傻蛋”也真是非常尴尬了。

相比之下,谷歌翻译的同四个句子虽然效果也一言难尽,但是基本句式还是有据可循的:
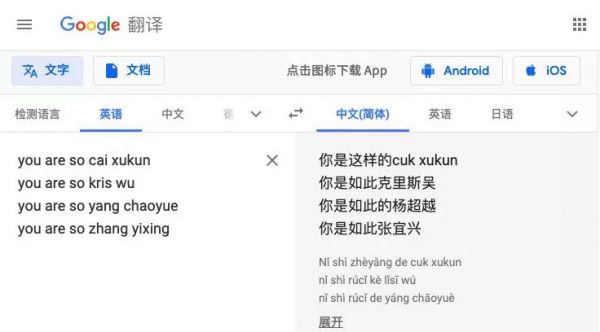
但粉丝可就不干了,直接把这个话题顶上了微博热搜。截至发稿,“微信翻译是认真的吗”这个话题仍然挂在微博热搜榜上,热度不减。
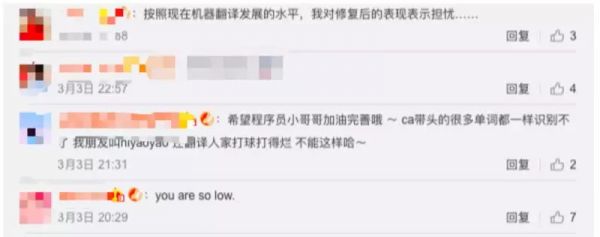
网友的评论区重点也是有点跑偏,俨然变成大型“反黑”现场,大量粉丝蜂拥而来表示“搬走”自家爱豆,众网友则是看热闹不嫌事大。当然,也有少数人没有偏离主题,把重点放在了翻译本身,有人对机器翻译水平表示担忧,有人给程序员小哥哥打气~
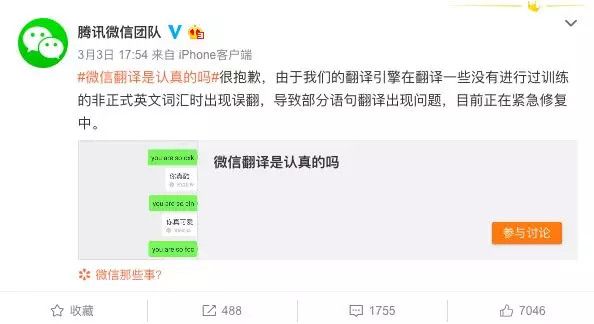
微信回应:翻译引擎误翻
事件发生后,微信团队迅速做出回应,称这是微信翻译引擎在翻译一些没有进行过训练的非正式英文词汇时出现误翻,导致部分语句翻译出现问题,目前正在紧急修复中。
经 AI 前线测试,目前正常的句式以及单词是可以正常翻译的,但是遇到不认识的词语,微信翻译干脆就“罢工”了,不知道仍然是故障状态还是说这是一个临时的解决方案?

全新神经网络翻译引擎
热闹看完了,本着严谨的态度,我们还是来看一下这里提到的微信翻译引擎。在早些时候,有消息称微信的英译汉功能由有道实现,其他语种则由微软负责。而据微信相关方面说法,目前微信聊天对话及朋友圈的英中、中英翻译已经替换成其自行开发的全新神经网络翻译引擎,但该神经网络的具体信息无从得知,AI 前线只找到关于它的零星信息。
据知乎一位自称是微信翻译引擎开发团队成员的用户透露,微信翻译功能是由一个不到 10 人的小团队开发,但是上线之时非常低调,甚至很多人不知道这个功能的存在。
当初上线之时,这位工程师就承认产品是有一定局限性的,很多翻译还不完善。
而在“如何评价微信翻译功能”这一话题之下,大部分评论对微信翻译功能的评价都不太友好,尤其是在姓名的翻译上,微信甚至会给你起一个英文名...

当然,也有人表示对微信翻译功能的支持,并真诚提出希望微信团队可以改善,甚至有人认为微信比百度、有道的翻译水平高。

虽然我们无从得知微信所使用的机器翻译引擎具体信息,但是可以通过机器学习翻译引擎的基本工作原理,了解一下为什么微信会在翻译一些没有进行过训练的非正式英文词汇时出现误翻,以至于部分语句翻译都出现问题。
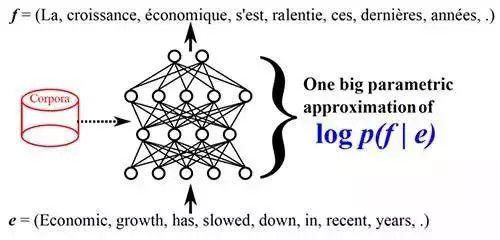
机器翻译的原理可以看作是如下这张图:

翻译机器就是其中带有问号的黑箱,它的作用就是能够将一个语言的序列(如 Economic growth has slowed down in recent years)转化成目标语言序列(如 La croissance economique sest ralentie ces dernieres annees)。其中翻译机器在正式工作之前可以利用已有的语料库(Corpora)来进行学习和训练。
所谓的神经网络机器翻译就是利用神经网络来实现上述的黑箱翻译机器。它的架构如下图所示:
与之前不同的是,这里用一个神经网络替换了上图中的黑箱。在神经网络中存在着大量的链接权重,这些权重就是要通过数据训练、学习的参数。训练好的神经网络可以将输入的源语言转换为输出的目标语言。(来源:知乎 ID:人工智能学习笔记)
那么,翻译机器又是如何编写代码,让计算机翻译人类的语言呢?最简单的方法,就是把句子中的每个单词,都替换成翻译后的目标语言单词。下面是西班牙语 - 英语互译的例子,只需要逐字替代,就能够得到一个完整的翻译句子。但是由于上下文语境的关系,翻译结果并不完美。

为了解决这个问题,机器翻译系统需要使用了不同的方法,通过分析大量文本来分配文本中的规则,以改进结果。 也就是教会计算机语法规则,然后让它根据规则翻译句子。
可惜事情并不是这么简单,饱受学习外语之苦的你肯定知道,规则总是有很多例外。当我们尝试为程序描写所有这些规则及其特例以及特例的特例时,翻译的质量就无从保证。
深度神经网络可以在非常复杂的任务(语音 / 视觉对象识别)中取得优异结果,但尽管它们具有灵活性,却只能用于输入和目标具有固定维数的任务。
在这个过程中,训练的重要性不言而喻,训练数据的多样性、完整性,以及数量、质量、时间等各种维度都会对系统最后产生的结果产生重要影响。
微信的翻译引擎出现误翻,按照官方的回应,是因为原文中出现没有进行过训练的非正式英文词汇,也就是说引擎系统“看到”了以前从未看到过的训练数据,因此影响了翻译的准确性也就不难理解了。
翻车不止一次
实际上,腾讯在翻译上不止翻过一次车。去年博鳌论坛期间,腾讯的翻译君就曾在会上闹过乌龙,AI 前线对此做过报道:《腾讯 AI 同传博鳌会上闹乌龙,技术界和翻译界怎么看?》。当时,翻译错误的地方多为常见的专用术语,如“一带一路”、“道路”等词汇,翻译还出现乱码结果,现场不得不再次聘请人工翻译“接盘”。

事件后腾讯承认,面对博鳌亚洲论坛复杂的语言环境和高大上的专业内容,“腾讯同传”确实出现了错误,答错了几道题。腾讯表示,作为创新孵化和落地的 AI 产品,“腾讯同传”还在不断学习和成长当中,但是不足就是不足,不足的地方就要继续加强学习。
不止腾讯,科大讯飞也曾深陷“AI 同传造假”事件,但事后以双方都确认误会的原因是同声传译人员在工作中把“讯飞听见”的转写功能错当成“机器同传”而告终。
不得不承认,虽然 AI 技术在不断进步,相关的自然语言处理技术也在不断取得突破,但仍然改变不了 AI 的智商不及四岁小孩的现实,尤其是在应用场景要求比较高的翻译领域,目前的技术水平还十分有限。不过,我们不应否认 AI 技术在翻译领域的成果,不积跬步,无以至千里,没有不断试错,就不会有成功。
相关推荐
微信翻译闹笑话蔡徐坤躺枪,AI翻译为何总“翻车”?
“你打篮球像蔡徐坤”:微信翻译这个bug是怎么回事?
“你打篮球像蔡徐坤”:微信翻译这个bug是怎么回事?
惨败给周杰伦后,蔡徐坤粉丝要退出微博所有数据战
谷歌翻译,只是一个没有感情的翻译机器吗?
周杰伦蔡徐坤粉丝之争,最后赢家是社交平台?
B站回应收到蔡徐坤律师函:相信法律自有公断
蔡徐坤1亿转发量幕后推手“星援app”被端
谷歌揭秘自家翻译系统:如何利用AI技术提高翻译质量
爽文+AI翻译,全球老外正在同步修仙
网址: 微信翻译闹笑话蔡徐坤躺枪,AI翻译为何总“翻车”? http://www.xishuta.com/newsview865.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95037
- 2人类唯一的出路:变成人工智能 19948
- 3报告:抖音海外版下载量突破1 19737
- 4移动办公如何高效?谷歌研究了 19179
- 5人类唯一的出路: 变成人工智 19048
- 62023年起,银行存取款迎来 10198
- 7网传比亚迪一员工泄露华为机密 8311
- 8五一来了,大数据杀熟又想来, 7519
- 9顶风作案?金山WPS被指套娃 7143
- 10滴滴出行被投诉价格操纵,网约 7136



