AI大模型,如何保持人类价值观?
AI价值对齐:是什么
人工智能进入大模型时代后,各种“类人”和“超人”能力持续涌现,其自主性、通用性和易用性快速提升,成为经济社会发展的新型技术底座。有机构预测,大模型将深入各行各业,每年为全球经济增加2.6万亿到4.4万亿美元的价值。[1]
然而,随着大模型(又称为基础模型)开始像人类一样从事广泛的语言理解和内容生成任务,人们需要直面一个最根本的、颇具科学挑战的问题:如何让大模型的能力和行为跟人类的价值、真实意图和伦理原则相一致,确保人类与人工智能协作过程中的安全与信任。这个问题被称为“价值对齐”(value alignment,或AI alignment)。价值对齐是AI安全的一个核心议题。
在一定程度上,模型的大小和模型的风险、危害成正相关,模型越大,风险越高,对价值对齐的需求也就越强烈。就当前而言,大模型的核心能力来源于预训练阶段,而且大模型在很大程度上基于整个互联网的公开信息进行训练,这既决定了它的能力,也决定了其局限性,互联网内容存在的问题都可能映射在模型当中。
一个没有价值对齐的大语言模型(LLM),可能输出含有种族或性别歧视的内容,帮助网络黑客生成用于进行网络攻击、电信诈骗的代码或其他内容,尝试说服或帮助有自杀念头的用户结束自己的生命,以及生产诸如此类的有害内容。因此,为了让大模型更加安全、可靠、实用,就需要尽可能地防止模型的有害输出或滥用行为。这是当前AI价值对齐的一项核心任务。
AI价值对齐:为什么
对大模型进行价值对齐,可以更好地应对大模型目前存在的一些突出问题。根据各界对于大模型突出问题的梳理,主要有如下四项:
一是错误信息问题。业内称为人工智能的“幻觉”。OpenAI首席技术官Mira Murati认为,ChatGPT和底层的大型语言模型的最大挑战是它们会输出错误的或者不存在的事实。[2]这可能源于训练数据中的错误或虚假信息,也可能是过度创造的副产物(如虚构事实)。让大模型在创造性和真实性之间踩好跷跷板,这是一个技术难题。
二是算法歧视问题。很多既有研究表明,大语言模型会从训练数据中复制有害的社会偏见和刻板印象。[3]OpenAI首席执行官Sam Altman认为,不可能有哪个模型在所有的领域都是无偏见的。因此,核心问题是如何检测、减少、消除模型的潜在歧视。
三是能力“涌现”的失控风险问题。随着算力和数据的持续增加,大模型预期将变得越来越强大,可能涌现出更多新的能力,其涌现出来的能力甚至可能超过其创造者的理解和控制,这意味着新的风险可能相伴而来,包括涌现出有风险的行为或目标。
目前技术专家的一个普遍担忧是,现在的AI大模型,以及将来可能出现的通用人工智能(AGI)和超级智能(ASI)等更强大先进的AI系统,可能形成不符合人类利益和价值的子目标(sub-goals),如为了实现其既定目标而涌现出追逐权力(power-seeking)、欺骗、不服从等行为。[4]例如,研究人员发现,GPT-4展现出了策略性欺骗人类的能力,可以“欺骗人类去执行任务以实现其隐藏目标”。
四是滥用问题。恶意分子可以通过对抗性输入、“越狱”(jailbreaking)操作等方式,让大模型帮助自己实现不法目的。
因此,价值对齐作为一个需要从技术上找到应对之策的实践性问题,已经成为AI大模型设计开发和部署过程中的一项基本原则,即:通过价值对齐的工具开发和工程化建设,努力确保AI以对人类和社会有益的方式行事,而不会对人类的价值和权利造成伤害或干扰。
AI价值对齐:怎么做
为了实现价值对齐,研发人员需要在模型层面让人工智能理解、遵从人类的价值、偏好和伦理原则,尽可能地防止模型的有害输出以及滥用行为,从而打造出兼具实用性与安全性的AI大模型。
首先,人类反馈的强化学习(RLHF)被证明是一个有效的方法,通过小量的人类反馈数据就可能实现比较好的效果。
2017年,OpenAI研究人员发表《依托人类偏好的深度强化学习》一文,提出将人类反馈引入强化学习。[5]RLHF包括初始模型训练、收集人类反馈、强化学习、迭代过程等几个步骤,其核心思路是要求人类训练员对模型输出内容的适当性进行评估,并基于收集的人类反馈为强化学习构建奖励信号,以实现对模型性能的改进优化。[6]从实践来看,RLHF在改进模型性能、提高模型的适应性、减少模型的偏见、增强模型的安全性等方面具有显著优势,包括减少模型在未来生产有害内容的可能性。

图:RLHF流程图(来源:OpenAI)
OpenAI将RLHF算法发扬光大,ChatGPT籍此取得成功,能够在很大程度上输出有用的、可信的、无害的内容。[7]GPT-4在RLHF训练阶段,通过增加额外的安全奖励信号(safety reward signal)来减少有害的输出,这一方法产生了很好的效果,显著提升了诱出恶意行为和有害内容的难度。
GPT-4相比之前的模型(如GPT-3.5)显著减少了幻觉、有害偏见和违法有害内容等问题。经过RLHF训练之后,GPT-4在相关真实性测试中得分比GPT-3.5高40%,响应禁止性内容请求的可能性比GPT-3.5降低了82%,并且能够更好地回应涉及敏感内容的用户请求。[8]总之,RLHF算法可以为大语言模型建立必要的安全护栏,在大模型的强大性/涌现性和安全性/可靠性之间扮演着“平衡器”这一关键角色。
其次,“宪法性AI”模式,使得价值对齐从低效的“人类监督”转向更高效的“规模化监督”(scalable oversight)。
考虑到将人类反馈用于训练更大规模、更复杂的AI模型所面临的时间和资源投入、人类能力等挑战,业界一直在探索如何借助AI监督(包括AI自我监督,以及一个AI系统监督另一个AI系统)的方法实现AI对齐。美国的AI大模型公司Anthropic提出了“宪法性AI”(constitutional AI)的方法。具体而言,研发一个从属的AI模型,其主要功能在于评估主模型的输出是否遵循了特定的“宪法性”原则(即一套事先确定的原则或规则),评估结果被用于优化主模型。
Anthropic结合自己的实践经验,并借鉴世界人权宣言、苹果公司的服务条款、DeepMind的Sparrow规则[9]等文件,提出了一套覆盖面广泛的原则清单,并以此为评估基准让其大模型Claude自己来评估自己的输出,其目标是在促进模型输出有用回答的同时,将其输出有害内容的可能性最小化。[10]
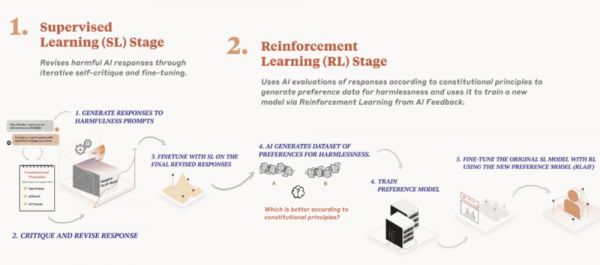
图:宪法性AI路径(来源:Anthropic)
Claude证明了宪法性AI方法的有效性,即帮助Claude减少有害的、歧视性的输出,避免帮助恶意使用者从事违法或不道德的活动,对使用者的“对抗性输入”作出更恰当的回应而非简单采取回避策略。总之,Anthropic认为,宪法性AI方法可以帮助创建一个有用的、诚实的、无害的AI系统,而且具有可拓展性、透明度、兼顾有用性和无害性等优势。
第三,多措并举,保障AI价值对齐的实现。
一是对训练数据的有效干预。大模型的很多问题(如幻觉、算法歧视)来源于训练数据,因此从训练数据切入是可行的方式,如对训练数据进行记录以识别是否存在代表性或多样化不足的问题,对训练数据进行人工或自动化筛选、检测以识别、消除有害偏见,构建价值对齐的专门数据集,等等。
二是对抗测试(adversarial testing)或者说红队测试(red teaming)。简言之就是在模型发布之前邀请内部或外部的专业人员(红队测试员)对模型发起各种对抗攻击,以发现潜在问题并予以解决。
例如,在GPT-4发布之前,OpenAI聘请了50多位各领域学者和专家对其模型进行测试,这些红队测试员的任务是向模型提出试探性的或者危险性的问题以测试模型的反应,OpenAI希望通过红队测试,帮助发现其模型在不准确信息(幻觉)、有害内容、虚假信息、歧视、语言偏见、涉及传统和非传统武器扩散的信息等方面的问题。[11]
三是内容过滤工具。例如OpenAI专门训练了一个对有害内容进行过滤的AI模型(即过滤模型),来识别有害的用户输入和模型输出(即违反其使用政策的内容),从而实现对模型的输入数据和输出数据的管控。
四是推进模型的可解释性和可理解性研究,例如OpenAI利用GPT-4来针对其大语言模型GPT-2的神经网络行为自动化地撰写解释并对其解释打分;[12]有研究人员则从机制解释性(mechanistic interpretability)的角度来应对AI对齐问题。
AI价值对齐:需长期解决的问题
价值对齐这项工作是AI领域最根本的,也是最具挑战性的研究。挑战性在于它需要广泛的学科和社会参与,需要各种各样的输入、方法和反馈;根本性在于它不仅关乎当下大模型的成败,而且事关人类能否实现对未来更加强大的人工智能(如AGI)的安全控制。因此AI领域的创新主体有责任和义务确保其AI模型是以人为本的、负责任的、安全可靠的。
著名人工智能科学家张亚勤教授指出,要解决AI和人类价值观对齐问题,做技术的人要把研究放到对齐上面,让机器理解并遵循人的价值。因此,价值对齐不仅仅是伦理的问题,还有如何实现的问题。做技术和研究的人不能只开发技术能力,不着力解决对齐问题。[13]
虽然AI价值对齐在技术上取得了一定的效果,但人们对最基础的AI价值问题依然没有形成共识:如何确立用以规范人工智能的一套统一的人类价值。目前看,选择哪些原则可能完全取决于研究人员的主观判断和价值观。而且考虑到我们生活在一个人们拥有多元文化、背景、资源和信仰的世界中,AI价值对齐需要考虑不同社会和群体的不同价值和道德规范。进一步而言,完全让研究人员自行选择这些价值是不切实际的,需要更多的社会参与来形成共识。
与此同时,当下的AI价值对齐工作还面临着一个关键问题:在人类的智能基本上保持不变的前提下,随着人工智能的能力持续提升,人类自己对那些前沿AI模型的有效监督将变得越来越困难。因此,为了确保AI安全,我们需要使我们监控、理解、设计AI模型的能力与模型本身的复杂性同步发展。
基于AI辅助或主导的“规模化监督”就体现出这一思路。今年7月,OpenAI宣布成立一个新的AI对齐团队,这个新的超级对齐团队(superalignment)的目标是在4年内弄明白如何让超级智能的AI系统实现价值对齐和安全,OpenAI将投入20%的算力资源来支持这一工程。其核心是探索如何利用AI来帮助人类解决AI的价值对齐问题。[14]

图:OpenAI超级对齐团队(来源:OpenAI)
可以说,只有确保AI系统的目标和行为与人类的价值和意图相一致,才能确保实现AI向善,促进生产力发展、经济增长和社会进步。价值对齐的研究和技术实现,离不开广泛的多学科协作和社会参与。政府、产业界、学术界等利益相关方需要投入更多资源来推动AI价值对齐的研究与实践,让人们监督、理解、控制人工智能的能力和人工智能的发展进步齐头并进,以确保人工智能能够造福全人类和全社会。
参考资料来源
[1]https://www.mckinsey.com/capabilities/mckinsey-digital/our-insights/the-economic-potential-of-generative-ai-the-next-productivity-frontier#introduction
[2]https://time.com/6252404/mira-murati-chatgpt-openai-interview/
[3]https://dl.acm.org/doi/fullHtml/10.1145/3531146.3533088
[4]https://yoshuabengio.org/2023/05/22/how-rogue-ais-may-arise/
[5]https://arxiv.org/abs/1706.03741
[6]https://www.unite.ai/what-is-reinforcement-learning-from-human-feedback-rlhf/
[7]https://venturebeat.com/ai/how-reinforcement-learning-with-human-feedback-is-unlocking-the-power-of-generative-ai/
[8]https://openai.com/research/gpt-4
[9]https://storage.googleapis.com/deepmind-media/DeepMind.com/Authors-Notes/sparrow/sparrow-final.pdf
[10]https://www.anthropic.com/index/claudes-constitution
[11]https://www.ft.com/content/0876687a-f8b7-4b39-b513-5fee942831e8(last visited on May 6, 2023).
[12]https://openai.com/research/language-models-can-explain-neurons-in-language-models
[13]https://mp.weixin.qq.com/s/gSWwj_HzVA3Lq5XZal1a3Q
[14]https://openai.com/blog/introducing-superalignment
本文来自微信公众号:腾讯研究院 (ID:cyberlawrc),作者:张钦坤、曹建峰
相关推荐
AI大模型,如何保持人类价值观?
Google DeepMind:如何将人类价值观融入AI?
4条建议:人类该如何向AI学习?
OpenAI发布炸裂研究:让AI解释AI黑箱,人类无法理解
未来AI生态:少数通用大模型与无数专用模型
大模型的智能,不是人类的智能
人工智能的“高考”时刻,AI大模型打先锋
阿尔法蛋的“大模型”初心:驾驭AI要从娃娃抓起
AI大模型只能沦为“锦上添花”吗?
AGI时代,如何避免人类危机?
网址: AI大模型,如何保持人类价值观? http://www.xishuta.com/newsview87795.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95228
- 2人类唯一的出路:变成人工智能 21183
- 3报告:抖音海外版下载量突破1 21148
- 4移动办公如何高效?谷歌研究了 20339
- 5人类唯一的出路: 变成人工智 20338
- 62023年起,银行存取款迎来 10336
- 7五一来了,大数据杀熟又想来, 8596
- 8网传比亚迪一员工泄露华为机密 8505
- 9滴滴出行被投诉价格操纵,网约 8215
- 10顶风作案?金山WPS被指套娃 7230



