从不温不火到炙手可热:语音识别技术简史
编者按:本文来自微信公众号“AI科技大本营”(ID:rgznai100),作者陈孝良、冯大航、李智勇,36氪经授权发布。
【导读】语音识别自半个世纪前诞生以来,一直处于不温不火的状态,直到 2009 年深度学习技术的长足发展才使得语音识别的精度大大提高,虽然还无法进行无限制领域、无限制人群的应用,但也在大多数场景中提供了一种便利高效的沟通方式。 本篇文章将从技术和产业两个角度来回顾一下语音识别发展的历程和现状,并分析一些未来趋势,希望能帮助更多年轻技术人员了解语音行业,并能产生兴趣投身于这个行业。
语音识别,通常称为自动语音识别,英文是Automatic Speech Recognition,缩写为 ASR,主要是将人类语音中的词汇内容转换为计算机可读的输入,一般都是可以理解的文本内容,也有可能是二进制编码或者字符序列。但是,我们一般理解的语音识别其实都是狭义的语音转文字的过程,简称语音转文本识别( Speech To Text, STT )更合适,这样就能与语音合成(Text To Speech, TTS )对应起来。
语音识别是一项融合多学科知识的前沿技术,覆盖了数学与统计学、声学与语言学、计算机与人工智能等基础学科和前沿学科,是人机自然交互技术中的关键环节。但是,语音识别自诞生以来的半个多世纪,一直没有在实际应用过程得到普遍认可,一方面这与语音识别的技术缺陷有关,其识别精度和速度都达不到实际应用的要求;另一方面,与业界对语音识别的期望过高有关,实际上语音识别与键盘、鼠标或触摸屏等应是融合关系,而非替代关系。
深度学习技术自 2009 年兴起之后,已经取得了长足进步。语音识别的精度和速度取决于实际应用环境,但在安静环境、标准口音、常见词汇场景下的语音识别率已经超过 95%,意味着具备了与人类相仿的语言识别能力,而这也是语音识别技术当前发展比较火热的原因。
随着技术的发展,现在口音、方言、噪声等场景下的语音识别也达到了可用状态,特别是远场语音识别已经随着智能音箱的兴起成为全球消费电子领域应用最为成功的技术之一。由于语音交互提供了更自然、更便利、更高效的沟通形式,语音必定将成为未来最主要的人机互动接口之一。
当然,当前技术还存在很多不足,如对于强噪声、超远场、强干扰、多语种、大词汇等场景下的语音识别还需要很大的提升;另外,多人语音识别和离线语音识别也是当前需要重点解决的问题。虽然语音识别还无法做到无限制领域、无限制人群的应用,但是至少从应用实践中我们看到了一些希望。
本篇文章将从技术和产业两个角度来回顾一下语音识别发展的历程和现状,并分析一些未来趋势,希望能帮助更多年轻技术人员了解语音行业,并能产生兴趣投身于这个行业。
语音识别的技术历程
现代语音识别可以追溯到 1952 年,Davis 等人研制了世界上第一个能识别 10 个英文数字发音的实验系统,从此正式开启了语音识别的进程。语音识别发展到今天已经有 70 多年,但从技术方向上可以大体分为三个阶段。
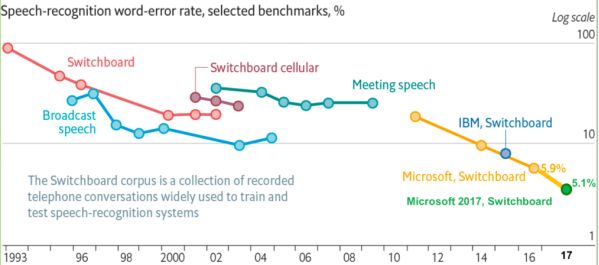
下图是从 1993 年到 2017 年在 Switchboard 上语音识别率的进展情况,从图中也可以看出 1993 年到 2009 年,语音识别一直处于 GMM-HMM 时代,语音识别率提升缓慢,尤其是 2000 年到 2009 年语音识别率基本处于停滞状态;2009 年随着深度学习技术,特别是 DNN 的兴起,语音识别框架变为 DNN-HMM,语音识别进入了 DNN 时代,语音识别精准率得到了显著提升;2015 年以后,由于“端到端”技术兴起,语音识别进入了百花齐放时代,语音界都在训练更深、更复杂的网络,同时利用端到端技术进一步大幅提升了语音识别的性能,直到 2017 年微软在 Swichboard 上达到词错误率 5.1%,从而让语音识别的准确性首次超越了人类,当然这是在一定限定条件下的实验结果,还不具有普遍代表性。
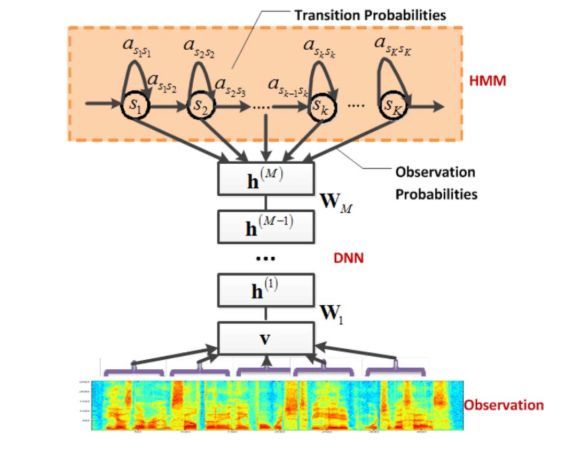
 GMM-HMM时代
GMM-HMM时代70 年代,语音识别主要集中在小词汇量、孤立词识别方面,使用的方法也主要是简单的模板匹配方法,即首先提取语音信号的特征构建参数模板,然后将测试语音与参考模板参数进行一一比较和匹配,取距离最近的样本所对应的词标注为该语音信号的发音。该方法对解决孤立词识别是有效的,但对于大词汇量、非特定人连续语音识别就无能为力。因此,进入 80 年代后,研究思路发生了重大变化,从传统的基于模板匹配的技术思路开始转向基于统计模型(HMM)的技术思路。
HMM 的理论基础在 1970 年前后就已经由 Baum 等人建立起来,随后由 CMU 的 Baker 和 IBM 的 Jelinek 等人将其应用到语音识别当中。HMM 模型假定一个音素含有 3 到 5 个状态,同一状态的发音相对稳定,不同状态间是可以按照一定概率进行跳转;某一状态的特征分布可以用概率模型来描述,使用最广泛的模型是 GMM。因此 GMM-HMM 框架中,HMM 描述的是语音的短时平稳的动态性,GMM 用来描述 HMM 每一状态内部的发音特征。
基于 GMM-HMM 框架,研究者提出各种改进方法,如结合上下文信息的动态贝叶斯方法、区分性训练方法、自适应训练方法、HMM/NN 混合模型方法等。这些方法都对语音识别研究产生了深远影响,并为下一代语音识别技术的产生做好了准备。自上世纪 90 年代语音识别声学模型的区分性训练准则和模型自适应方法被提出以后,在很长一段内语音识别的发展比较缓慢,语音识别错误率那条线一直没有明显下降。
DNN-HMM时代
2006年,Hinton 提出深度置信网络(DBN),促使了深度神经网络(DNN)研究的复苏。2009 年,Hinton 将 DNN 应用于语音的声学建模,在 TIMIT 上获得了当时最好的结果。2011 年底,微软研究院的俞栋、邓力又把 DNN 技术应用在了大词汇量连续语音识别任务上,大大降低了语音识别错误率。从此语音识别进入 DNN-HMM 时代。
DNN-HMM主要是用 DNN 模型代替原来的 GMM 模型,对每一个状态进行建模,DNN 带来的好处是不再需要对语音数据分布进行假设,将相邻的语音帧拼接又包含了语音的时序结构信息,使得对于状态的分类概率有了明显提升,同时DNN还具有强大环境学习能力,可以提升对噪声和口音的鲁棒性。
 简单来说,DNN 就是给出输入的一串特征所对应的状态概率。由于语音信号是连续的,不仅各个音素、音节以及词之间没有明显的边界,各个发音单位还会受到上下文的影响。虽然拼帧可以增加上下文信息,但对于语音来说还是不够。而递归神经网络(RNN)的出现可以记住更多历史信息,更有利于对语音信号的上下文信息进行建模。
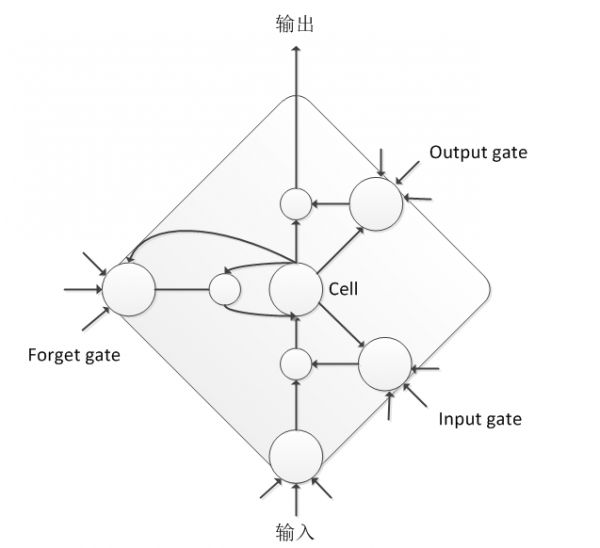
简单来说,DNN 就是给出输入的一串特征所对应的状态概率。由于语音信号是连续的,不仅各个音素、音节以及词之间没有明显的边界,各个发音单位还会受到上下文的影响。虽然拼帧可以增加上下文信息,但对于语音来说还是不够。而递归神经网络(RNN)的出现可以记住更多历史信息,更有利于对语音信号的上下文信息进行建模。由于简单的 RNN 存在梯度爆炸和梯度消散问题,难以训练,无法直接应用于语音信号建模上,因此学者进一步探索,开发出了很多适合语音建模的 RNN 结构,其中最有名的就是 LSTM 。LSTM 通过输入门、输出门和遗忘门可以更好的控制信息的流动和传递,具有长短时记忆能力。虽然 LSTM 的计算复杂度会比 DNN 增加,但其整体性能比 DNN 有相对 20% 左右稳定提升。
 BLSTM 是在 LSTM 基础上做的进一步改进,不仅考虑语音信号的历史信息对当前帧的影响,还要考虑未来信息对当前帧的影响,因此其网络中沿时间轴存在正向和反向两个信息传递过程,这样该模型可以更充分考虑上下文对于当前语音帧的影响,能够极大提高语音状态分类的准确率。BLSTM 考虑未来信息的代价是需要进行句子级更新,模型训练的收敛速度比较慢,同时也会带来解码的延迟,对于这些问题,业届都进行了工程优化与改进,即使现在仍然有很多大公司使用的都是该模型结构。
BLSTM 是在 LSTM 基础上做的进一步改进,不仅考虑语音信号的历史信息对当前帧的影响,还要考虑未来信息对当前帧的影响,因此其网络中沿时间轴存在正向和反向两个信息传递过程,这样该模型可以更充分考虑上下文对于当前语音帧的影响,能够极大提高语音状态分类的准确率。BLSTM 考虑未来信息的代价是需要进行句子级更新,模型训练的收敛速度比较慢,同时也会带来解码的延迟,对于这些问题,业届都进行了工程优化与改进,即使现在仍然有很多大公司使用的都是该模型结构。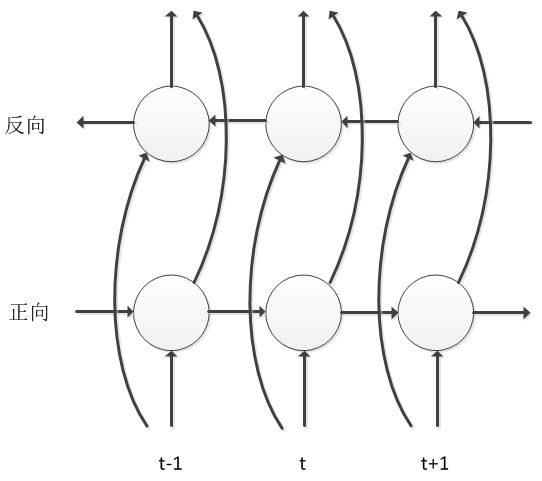 图像识别中主流的模型就是 CNN,而语音信号的时频图也可以看作是一幅图像,因此 CNN 也被引入到语音识别中。要想提高语音识别率,就需要克服语音信号所面临的多样性,包括说话人自身、说话人所处的环境、采集设备等,这些多样性都可以等价为各种滤波器与语音信号的卷积。而 CNN 相当于设计了一系列具有局部关注特性的滤波器,并通过训练学习得到滤波器的参数,从而从多样性的语音信号中抽取出不变的部分,CNN 本质上也可以看作是从语音信号中不断抽取特征的一个过程。CNN 相比于传统的 DNN 模型,在相同性能情况下,前者的参数量更少。
图像识别中主流的模型就是 CNN,而语音信号的时频图也可以看作是一幅图像,因此 CNN 也被引入到语音识别中。要想提高语音识别率,就需要克服语音信号所面临的多样性,包括说话人自身、说话人所处的环境、采集设备等,这些多样性都可以等价为各种滤波器与语音信号的卷积。而 CNN 相当于设计了一系列具有局部关注特性的滤波器,并通过训练学习得到滤波器的参数,从而从多样性的语音信号中抽取出不变的部分,CNN 本质上也可以看作是从语音信号中不断抽取特征的一个过程。CNN 相比于传统的 DNN 模型,在相同性能情况下,前者的参数量更少。综上所述,对于建模能力来说,DNN 适合特征映射到独立空间,LSTM 具有长短时记忆能力,CNN 擅长减少语音信号的多样性,因此一个好的语音识别系统是这些网络的组合。
端到端时代
语音识别的端到端方法主要是代价函数发生了变化,但神经网络的模型结构并没有太大变化。总体来说,端到端技术解决了输入序列的长度远大于输出序列长度的问题。端到端技术主要分成两类:一类是 CTC 方法,另一类是 Sequence-to-Sequence 方法。传统语音识别 DNN-HMM 架构里的声学模型,每一帧输入都对应一个标签类别,标签需要反复的迭代来确保对齐更准确。
采用 CTC 作为损失函数的声学模型序列,不需要预先对数据对齐,只需要一个输入序列和一个输出序列就可以进行训练。CTC 关心的是预测输出的序列是否和真实的序列相近,而不关心预测输出序列中每个结果在时间点上是否和输入的序列正好对齐。CTC 建模单元是音素或者字,因此它引入了 Blank。对于一段语音,CTC 最后输出的是尖峰的序列,尖峰的位置对应建模单元的 Label,其他位置都是 Blank。
Sequence-to-Sequence 方法原来主要应用于机器翻译领域。2017 年,Google 将其应用于语音识别领域,取得了非常好的效果,将词错误率降低至5.6%。如下图所示,Google 提出新系统的框架由三个部分组成:Encoder 编码器组件,它和标准的声学模型相似,输入的是语音信号的时频特征;经过一系列神经网络,映射成高级特征 henc,然后传递给 Attention 组件,其使用 henc 特征学习输入 x 和预测子单元之间的对齐方式,子单元可以是一个音素或一个字。最后,attention 模块的输出传递给 Decoder,生成一系列假设词的概率分布,类似于传统的语言模型。
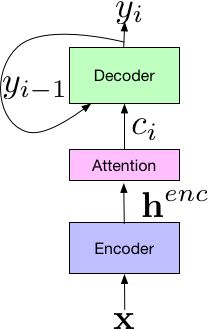 端到端技术的突破,不再需要 HMM 来描述音素内部状态的变化,而是将语音识别的所有模块统一成神经网络模型,使语音识别朝着更简单、更高效、更准确的方向发展。
端到端技术的突破,不再需要 HMM 来描述音素内部状态的变化,而是将语音识别的所有模块统一成神经网络模型,使语音识别朝着更简单、更高效、更准确的方向发展。语音识别的技术现状
目前,主流语音识别框架还是由 3 个部分组成:声学模型、语言模型和解码器,有些框架也包括前端处理和后处理。随着各种深度神经网络以及端到端技术的兴起,声学模型是近几年非常热门的方向,业界都纷纷发布自己新的声学模型结构,刷新各个数据库的识别记录。由于中文语音识别的复杂性,国内在声学模型的研究进展相对更快一些,主流方向是更深更复杂的神经网络技术融合端到端技术。
2018年,科大讯飞提出深度全序列卷积神经网络(DFCNN),DFCNN 使用大量的卷积直接对整句语音信号进行建模,主要借鉴了图像识别的网络配置,每个卷积层使用小卷积核,并在多个卷积层之后再加上池化层,通过累积非常多卷积池化层对,从而可以看到更多的历史信息。
2018年,阿里提出 LFR-DFSMN(Lower Frame Rate-Deep Feedforward Sequential Memory Networks)。该模型将低帧率算法和 DFSMN 算法进行融合,语音识别错误率相比上一代技术降低 20%,解码速度提升 3 倍。FSMN 通过在 FNN 的隐层添加一些可学习的记忆模块,从而可以有效的对语音的长时相关性进行建模。而 DFSMN 是通过跳转避免深层网络的梯度消失问题,可以训练出更深层的网络结构。
2019 年,百度提出了流式多级的截断注意力模型 SMLTA,该模型是在 LSTM 和 CTC 的基础上引入了注意力机制来获取更大范围和更有层次的上下文信息。其中流式表示可以直接对语音进行一个小片段一个小片段的增量解码;多级表示堆叠多层注意力模型;截断则表示利用 CTC 模型的尖峰信息,把语音切割成一个一个小片段,注意力模型和解码可以在这些小片段上展开。在线语音识别率上,该模型比百度上一代 Deep Peak2 模型提升相对 15% 的性能。
开源语音识别 Kaldi 是业界语音识别框架的基石。Kaldi 的作者 Daniel Povey 一直推崇的是 Chain 模型。该模型是一种类似于 CTC 的技术,建模单元相比于传统的状态要更粗颗粒一些,只有两个状态,一个状态是 CD Phone,另一个是 CD Phone 的空白,训练方法采用的是 Lattice-Free MMI 训练。该模型结构可以采用低帧率的方式进行解码,解码帧率为传统神经网络声学模型的三分之一,而准确率相比于传统模型有非常显著的提升。
远场语音识别技术主要解决真实场景下舒适距离内人机任务对话和服务的问题,是 2015 年以后开始兴起的技术。由于远场语音识别解决了复杂环境下的识别问题,在智能家居、智能汽车、智能会议、智能安防等实际场景中获得了广泛应用。目前国内远场语音识别的技术框架以前端信号处理和后端语音识别为主,前端利用麦克风阵列做去混响、波束形成等信号处理,以让语音更清晰,然后送入后端的语音识别引擎进行识别。
语音识别另外两个技术部分:语言模型和解码器,目前来看并没有太大的技术变化。语言模型主流还是基于传统的 N-Gram 方法,虽然目前也有神经网络的语言模型的研究,但在实用中主要还是更多用于后处理纠错。解码器的核心指标是速度,业界大部分都是按照静态解码的方式进行,即将声学模型和语言模型构造成 WFST 网络,该网络包含了所有可能路径,解码就是在该空间进行搜索的过程。由于该理论相对成熟,更多的是工程优化的问题,所以不论是学术还是产业目前关注的较少。
语音识别的技术趋势
语音识别主要趋于远场化和融合化的方向发展,但在远场可靠性还有很多难点没有突破,比如多轮交互、多人噪杂等场景还有待突破,还有需求较为迫切的人声分离等技术。新的技术应该彻底解决这些问题,让机器听觉远超人类的感知能力。这不能仅仅只是算法的进步,需要整个产业链的共同技术升级,包括更为先进的传感器和算力更强的芯片。
单从远场语音识别技术来看,仍然存在很多挑战,包括:
(1)回声消除技术。由于喇叭非线性失真的存在,单纯依靠信号处理手段很难将回声消除干净,这也阻碍了语音交互系统的推广,现有的基于深度学习的回声消除技术都没有考虑相位信息,直接求取的是各个频带上的增益,能否利用深度学习将非线性失真进行拟合,同时结合信号处理手段可能是一个好的方向。
(2)噪声下的语音识别仍有待突破。信号处理擅长处理线性问题,深度学习擅长处理非线性问题,而实际问题一定是线性和非线性的叠加,因此一定是两者融合才有可能更好地解决噪声下的语音识别问题。
(3)上述两个问题的共性是目前的深度学习仅用到了语音信号各个频带的能量信息,而忽略了语音信号的相位信息,尤其是对于多通道而言,如何让深度学习更好的利用相位信息可能是未来的一个方向。
(4)另外,在较少数据量的情况下,如何通过迁移学习得到一个好的声学模型也是研究的热点方向。例如方言识别,若有一个比较好的普通话声学模型,如何利用少量的方言数据得到一个好的方言声学模型,如果做到这点将极大扩展语音识别的应用范畴。这方面已经取得了一些进展,但更多的是一些训练技巧,距离终极目标还有一定差距。
(5)语音识别的目的是让机器可以理解人类,因此转换成文字并不是最终的目的。如何将语音识别和语义理解结合起来可能是未来更为重要的一个方向。语音识别里的 LSTM 已经考虑了语音的历史时刻信息,但语义理解需要更多的历史信息才能有帮助,因此如何将更多上下文会话信息传递给语音识别引擎是一个难题。
(6)让机器听懂人类语言,仅靠声音信息还不够,“声光电热力磁”这些物理传感手段,下一步必然都要融合在一起,只有这样机器才能感知世界的真实信息,这是机器能够学习人类知识的前提条件。而且,机器必然要超越人类的五官,能够看到人类看不到的世界,听到人类听不到的世界。
语音识别的产业历程
语音识别这半个多世纪的产业历程中,其中共有三个关键节点,两个和技术有关,一个和应用有关。第一个关键节点是 1988 年的一篇博士论文,开发了第一个基于隐马尔科夫模型(HMM)的语音识别系统—— Sphinx,当时实现这一系统的正是现在的著名投资人李开复。
从 1986 年到 2010 年,虽然混合高斯模型效果得到持续改善,而被应用到语音识别中,并且确实提升了语音识别的效果,但实际上语音识别已经遭遇了技术天花板,识别的准确率很难超过 90%。很多人可能还记得,在 1998 年前后 IBM、微软都曾经推出和语音识别相关的软件,但最终并未取得成功。
第二个关键节点是 2009 年深度学习被系统应用到语音识别领域中。这导致识别的精度再次大幅提升,最终突破 90%,并且在标准环境下逼近 98%。有意思的是,尽管技术取得了突破,也涌现出了一些与此相关的产品,比如 Siri、Google Assistant 等,但与其引起的关注度相比,这些产品实际取得的成绩则要逊色得多。Siri 刚一面世的时候,时任 Google CEO 的施密特就高呼,这会对 Google 的搜索业务产生根本性威胁,但事实上直到 Amazon Echo 的面世,这种根本性威胁才真的有了具体的载体。
第三个关键点正是 Amazon Echo 的出现,纯粹从语音识别和自然语言理解的技术乃至功能的视角看这款产品,相对于 Siri 等并未有什么本质性改变,核心变化只是把近场语音交互变成了远场语音交互。Echo 正式面世于2015年6月,到 2017 年销量已经超过千万,同时在 Echo 上扮演类似 Siri 角色的 Alexa 渐成生态,其后台的第三方技能已经突破 10000 项。借助落地时从近场到远场的突破,亚马逊一举从这个赛道的落后者变为行业领导者。
但自从远场语音技术规模落地以后,语音识别领域的产业竞争已经开始从研发转为应用。研发比的是标准环境下纯粹的算法谁更有优势,而应用比较的是在真实场景下谁的技术更能产生优异的用户体验,而一旦比拼真实场景下的体验,语音识别便失去独立存在的价值,更多作为产品体验的一个环节而存在。
所以到 2019 年,语音识别似乎进入了一个相对平静期,全球产业界的主要参与者们,包括亚马逊、谷歌、微软、苹果、百度、科大讯飞、阿里、腾讯、云知声、思必驰、声智等公司,在一路狂奔过后纷纷开始反思自己的定位和下一步的打法。
语音赛道里的标志产品——智能音箱,以一种大跃进的姿态出现在大众面前。2016 年以前,智能音箱玩家们对这款产品的认识还都停留在:亚马逊出了一款叫 Echo 的产品,功能和 Siri 类似。先行者科大讯飞叮咚音箱的出师不利,更是加重了其它人的观望心态。真正让众多玩家从观望转为积极参与的转折点是逐步曝光的 Echo 销量,2016 年底,Echo 近千万的美国销量让整个世界震惊。这是智能设备从未达到过的高点,在 Echo 以前除了 Apple Watch 与手环,像恒温器、摄像头这样的产品突破百万销量已是惊人表现。这种销量以及智能音箱的 AI 属性促使 2016 年下半年,国内各大巨头几乎是同时转变态度,积极打造自己的智能音箱。
未来,回看整个发展历程,2019 年是一个明确的分界点。在此之前,全行业是突飞猛进,但 2019 年之后则开始进入对细节领域渗透和打磨的阶段,人们关注的焦点也不再是单纯的技术指标,而是回归到体验,回归到一种“新的交互方式到底能给我们带来什么价值”这样更为一般的、纯粹的商业视角。技术到产品再到是否需要与具体的形象进行交互结合,比如人物形象;流程自动化是否要与语音结合;酒店场景应该如何使用这种技术来提升体验,诸如此类最终都会一一呈现在从业者面前。而此时行业的主角也会从原来的产品方过渡到平台提供方,AIoT 纵深过大,没有任何一个公司可以全线打造所有的产品。
语音识别的产业趋势
当语音产业需求四处开花的同时,行业的发展速度反过来会受限于平台服务商的供给能力。跳出具体案例来看,行业下一步发展的本质逻辑是:在具体每个点的投入产出是否达到一个普遍接受的界限。
离这个界限越近,行业就越会接近滚雪球式发展的临界点,否则整体增速就会相对平缓。不管是家居、酒店、金融、教育或者其他场景,如果解决问题都是非常高投入并且长周期的事情,那对此承担成本的一方就会犹豫,这相当于试错成本过高。如果投入后,没有可感知的新体验或者销量促进,那对此承担成本的一方也会犹豫,显然这会影响值不值得上的判断。而这两个事情,归根结底都必须由平台方解决,产品方或者解决方案方对此无能为力,这是由智能语音交互的基础技术特征所决定。
从核心技术来看,整个语音交互链条有五项单点技术:唤醒、麦克风阵列、语音识别、自然语言处理、语音合成,其它技术点比如声纹识别、哭声检测等数十项技术通用性略弱,但分别出现在不同的场景下,并会在特定场景下成为关键。看起来关联的技术已经相对庞杂,但切换到商业视角我们就会发现,找到这些技术距离打造一款体验上佳的产品仍然有绝大距离。
所有语音交互产品都是端到端打通的产品,如果每家厂商都从这些基础技术来打造产品,那就每家都要建立自己云服务稳定,确保响应速度,适配自己所选择的硬件平台,逐项整合具体的内容(比如音乐、有声读物)。这从产品方或者解决方案商的视角来看是不可接受的。这时候就会催生相应的平台服务商,它要同时解决技术、内容接入和工程细节等问题,最终达成试错成本低、体验却足够好的目标。
平台服务并不需要闭门造车,平台服务的前提是要有能屏蔽产品差异的操作系统,这是 AI+IOT 的特征,也是有所参照的,亚马逊过去近 10 年里是同步着手做两件事:一个是持续推出面向终端用户的产品,比如 Echo,Echo Show等;一个是把所有产品所内置的系统 Alexa 进行平台化,面向设备端和技能端同步开放SDK和调试发布平台。虽然 Google Assistant 号称单点技术更为领先,但从各方面的结果来看 Alexa 是当之无愧的最为领先的系统平台,可惜的是 Alexa 并不支持中文以及相应的后台服务。
国内则缺乏亚马逊这种统治力的系统平台提供商,当前的平台提供商分为两个阵营:一类是以百度、阿里、讯飞、小米、腾讯为代表的传统互联网或者上市公司;一类是以声智等为代表的新兴人工智能公司。新兴的人工智能公司相比传统公司产品和服务上的历史包袱更轻,因此在平台服务上反倒是可以主推一些更为面向未来、有特色的基础服务,比如兼容性方面新兴公司做的会更加彻底,这种兼容性对于一套产品同时覆盖国内国外市场是相当有利的。
类比过去的 Android,语音交互的平台提供商们其实面临更大的挑战,发展过程可能会更加的曲折。过去经常被提到的操作系统的概念在智能语音交互背景下事实上正被赋予新的内涵,它日益被分成两个不同但必须紧密结合的部分。
过去的 Linux 以及各种变种承担的是功能型操作系统的角色,而以 Alexa 为代表的新型系统则承担的则是智能型系统的角色。前者完成完整的硬件和资源的抽象和管理,后者则让这些硬件以及资源得到具体的应用,两者相结合才能输出最终用户可感知的体验。功能型操作系统和智能型操作系统注定是一种一对多的关系,不同的 AIoT 硬件产品在传感器(深度摄像头、雷达等)、显示器上(有屏、无屏、小屏、大屏等)具有巨大差异,这会导致功能型系统的持续分化(可以和 Linux 的分化相对应)。这反过来也就意味着一套智能型系统,必须同时解决与功能型系统的适配以及对不同后端内容以及场景进行支撑的双重责任。
这两边在操作上,属性具有巨大差异。解决前者需要参与到传统的产品生产制造链条中去,而解决后者则更像应用商店的开发者。这里面蕴含着巨大的挑战和机遇。在过去功能型操作系统的打造过程中,国内的程序员们更多的是使用者的角色,但智能型操作系统虽然也可以参照其他,但这次必须自己来从头打造完整的系统。(国外巨头不管在中文相关的技术上还是内容整合上事实上都非常薄弱,不存在侵略国内市场的可能性)
随着平台服务商两边的问题解决的越来越好,基础的计算模式则会逐渐发生改变,人们的数据消费模式会与今天不同。个人的计算设备(当前主要是手机、笔记本、Pad)会根据不同场景进一步分化。比如在车上、家里、酒店、工作场景、路上、业务办理等会根据地点和业务进行分化。但分化的同时背后的服务则是统一的,每个人可以自由的根据场景做设备的迁移,背后的服务虽然会针对不同的场景进行优化,但在个人偏好这样的点上则是统一的。
人与数字世界的接口,在现在越来越统一于具体的产品形态(比如手机),但随着智能型系统的出现,这种统一则会越来越统一于系统本身。作为结果这会带来数据化程度的持续加深,我们越来越接近一个百分百数据化的世界。
总结
从技术进展和产业发展来看,语音识别虽然还不能解决无限制场景、无限制人群的通用识别问题,但是已经能够在各个真实场景中普遍应用并且得到规模验证。更进一步的是,技术和产业之间形成了比较好的正向迭代效应,落地场景越多,得到的真实数据越多,挖掘的用户需求也更准确,这帮助了语音识别技术快速进步,也基本满足了产业需求,解决了很多实际问题,这也是语音识别相对其他 AI 技术最为明显的优势。
不过,我们也要看到,语音识别的内涵必须不断扩展,狭义语音识别必须走向广义语音识别,致力于让机器听懂人类语言,这才能将语音识别研究带到更高维度。我们相信,多技术、多学科、多传感的融合化将是未来人工智能发展的主流趋势。在这种趋势下,我们还有很多未来的问题需要探讨,比如键盘、鼠标、触摸屏和语音交互的关系怎么变化?搜索、电商、社交是否再次重构?硬件是否逆袭变得比软件更加重要?产业链中的传感、芯片、操作系统、产品和内容厂商之间的关系又该如何变化?
本文得到众多语音识别领域专家的指导,并引用了一些参考资料的配图,在此表示感谢,本文中的不足之处还请批评指正。
参考资料
[1] W. Minhua, K. Kumatani, S. Sundaram, N. Ström and B. Hoffmeister, "Frequency Domain Multi-channel Acoustic Modeling for Distant Speech Recognition,"ICASSP 2019 - 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, United Kingdom, 2019, pp. 6640-6644.
[2] Li B, Sainath TN, Narayanan A, Caroselli J, Bacchiani M, Misra A, Shafran I, Sak H, Pundak G, Chin KK, Sim KC. Acoustic Modeling for Google Home. InInterspeech 2017 Aug 20 (pp. 399-403).
[3] Chiu CC, Sainath TN, Wu Y, Prabhavalkar R, Nguyen P, Chen Z, Kannan A, Weiss RJ, Rao K, Gonina E, Jaitly N. State-of-the-art speech recognition with sequence-to-sequence models. In2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) 2018 Apr 15 (pp. 4774-4778). IEEE.
[4] Li J, Deng L, Gong Y, Haeb-Umbach R. An overview of noise-robust automatic speech recognition. IEEE/ACM Transactions on Audio, Speech, and Language Processing. 2014 Feb 5;22(4):745-77.
[5] 俞栋,邓力. 解析深度学习:语音识别实践. 电子工业出版社. 2016年.
[6] 韩纪庆,张磊,郑铁然. 语音信号处理. 清华大学出版社. 2005年.
[7] 王东. 语音识别技术的现状与未来. 2017年.
[8]https://developer.amazon.com/zh/blogs/alexa/post/92bb9391-e930-464b-8ece-1fd8b476702a/amazon-scientist-outlines-multilayer-system-for-smart-speaker-echo-cancellation-and-voice-enhancement
[9]https://venturebeat.com/2019/04/01/alexa-researchers-develop-2-mic-speech-recognition-system-that-beats-a-7-mic-array/
[10]https://yq.aliyun.com/articles/704173
[11]http://azero.soundai.com
[12]http://research.baidu.com/Blog/index-view?id=109
相关推荐
从不温不火到炙手可热:语音识别技术简史
阴谋论下的人脸识别简史
小企业不配谈技术门槛?从语音识别巨头Nuance的兴衰说起
中关村简史:从创业有罪到中国硅谷
“寻找贾维斯”简史
借助语音识别技术,这些印度公司要将方言服务进行到底
知料 | 苹果的颜色简史:从性冷淡到五彩斑斓
互联网造神简史:从徐静蕾到李佳琦
2007-2019:手势交互简史
语音识别揭秘:你的手机究竟有多理解你?
网址: 从不温不火到炙手可热:语音识别技术简史 http://www.xishuta.com/newsview8897.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95228
- 2人类唯一的出路:变成人工智能 21183
- 3报告:抖音海外版下载量突破1 21148
- 4移动办公如何高效?谷歌研究了 20339
- 5人类唯一的出路: 变成人工智 20338
- 62023年起,银行存取款迎来 10336
- 7五一来了,大数据杀熟又想来, 8596
- 8网传比亚迪一员工泄露华为机密 8505
- 9滴滴出行被投诉价格操纵,网约 8215
- 10顶风作案?金山WPS被指套娃 7230



