一文读懂“多模态基础模型”
视觉是人类和其他生物感知世界的主要渠道之一。
人工智能(AI)的一个核心愿景是开发 AI 代理,模仿感知、生成视觉信号,与视觉世界进行互动。
近日,微软研究团队发布了一份多模态基础模型分类和演化的综述,展示了视觉和视觉语言能力。值得注意的是,该研究还重点探讨了多模态基础模型从专业化到通用视觉助手转变的方法。
相关研究论文以“Multimodal Foundation Models: From Specialists to General-Purpose Assistants”为题,已发布在预印本网站 arXiv 上。

从视觉理解到视觉生成
随着广泛数据训练模型(如 BERT、GPT 家族、CLIP 和 DALL-E)的出现,AI 领域经历了一次范式转变。这些模型能够适应各种不同的下游任务,因此被称为基础模型。这一模型的兴起主要集中在自然语言处理领域,从 BERT 到 ChatGPT 等都是明显的例证。
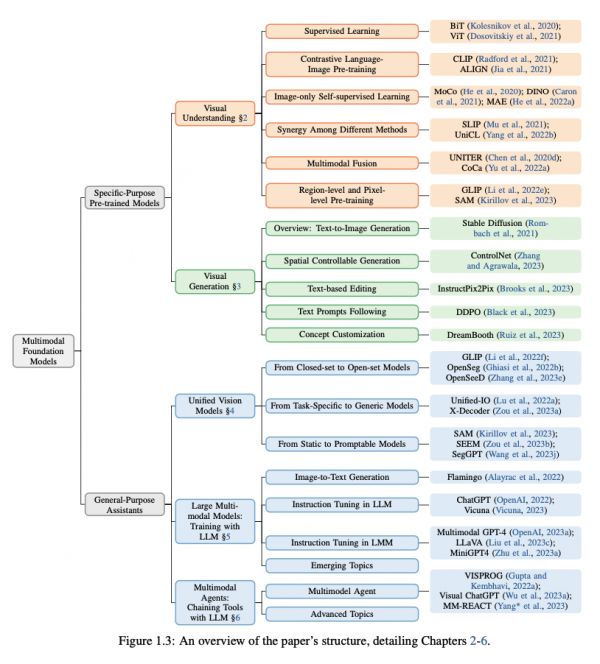
根据多模态基础模型的功能和通用,先前的研究将其分为视觉理解模型、视觉生成模型、通用界面模型。基于此,该研究将多模态基础模型分为两类:特定目的的预训练视觉模型(Specific-Purpose Pre-trained Vision Models)和通用型助手(General-Purpose Assistants)。
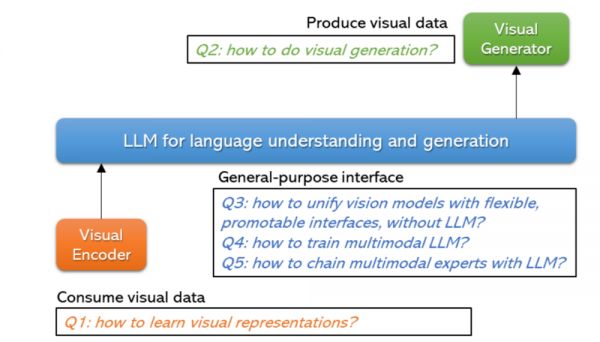
在视觉理解模型章节中,该研究首先讨论了监督学习和 CLIP,随后转向仅图像的自监督学习,其中包括对比学习、非对比学习以及掩膜图像建模。接着,研究又探讨了增强多模态融合、区域级和像素级图像理解的预训练方法。
另外,研究详细介绍了图像表示的学习方法,可以通过在图像中挖掘的监督信号进行学习,也可以通过利用从网络中挖掘的图像文本数据集进行语言监督学习。
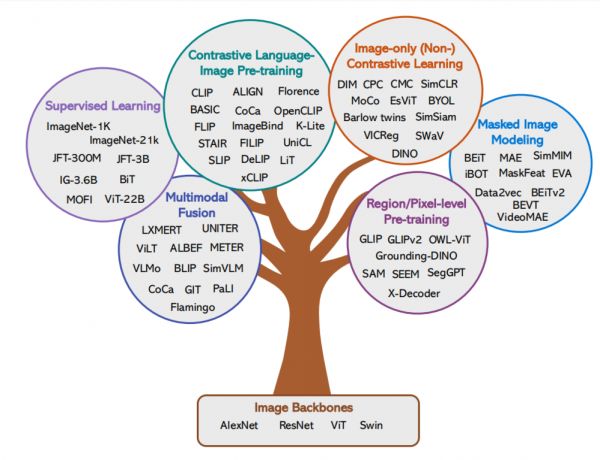
在视觉生成模型章节中,该研究详细介绍了与调整 T2I 模型以更准确地与人类意图保持一致相关的文献。其中包括增强空间可控性、编辑现有图像以改善对齐、更有效地遵循文本提示,以及为新的视觉概念个性化 T2I 模型。

基于以往研究,研究人员设想了未来的 T2I 模型将拥有一个统一的对齐调整阶段,可以将一个预训练的 T2I 模型转化为更贴近人类意图的模型。这样的模型能够无缝处理文本和图像输入,生成所期望的视觉内容,人类无需再为不同的对齐挑战定制多个模型。
开发通用统一的视觉系统
值得注意的是,计算机视觉任务的差异导致构建统一的视觉模型面临巨大挑战。
不同的视觉任务涉及各种不同类型的输入,包括图像、视频以及视觉与语言等多模态输入。不同任务还需要不同的粒度,如图像级别、区域级别和像素级别的任务。这导致视觉系统的输出具有不同的格式,包括空间信息和语义信息。
此外,数据方面也存在挑战,因为不同类型的标签注释成本差异巨大,而且收集图像数据通常比文本数据更昂贵,因此视觉数据的规模通常较小。
目前,计算机视觉领域对于开发通用统一的视觉系统,特别是用于视觉理解任务,越来越感兴趣,但一些开放性问题亟待解决。
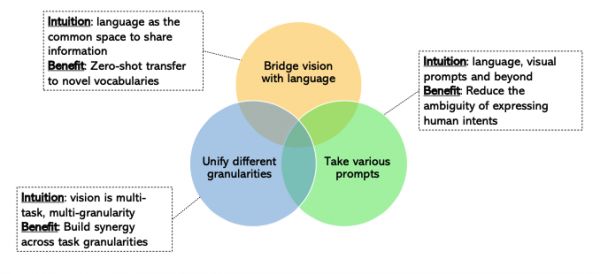
计算机视觉在应用方面面临一些挑战。由于视觉数据的异质性,目前用于训练模型的数据几乎无法涵盖物理世界的全部情况。而且,目前扩展视觉模型的正确路径尚不明晰。另外,由于视觉和语言之间固有的差异,目前仍然不清楚应该进一步扩展视觉模型并集成语言模型,还是中等规模的视觉模型和大型语言模型(LLMs)的组合已足以解决大多数的问题。
除此之外,该综述全面研究了大型多模态模型,包括它们的背景、重要性以及最新发展。研究重点关注了图像到文本生成模型的基础知识和各种案例研究中的代表性模型实例。同时,探讨了 OpenAI 多模态 GPT-4 以及领域内的研究差距。此外,研究还触及了多模态模型领域的高级主题。最后,通过评估距离实现多模态 GPT-4 的进展总结了该领域的现状。
值得一提的是,目前开源社区已经开发了各种模型和原型,用于不同的新功能。例如,LLaVA/Mini-GPT4 为构建多模态聊天机器人铺平了道路,其中一些示例可以复制 GPT-4 技术报告中的结果。从启用新功能的角度来看,开源社区似乎已经接近了 OpenAI 多模态 GPT-4,通过探索朝着构建通用多模态助手迈出了初步的探索。

然而,就扩展给定的功能而言,仍然存在明显的巨大差距,例如研究在 LLaVA 中观察到的视觉推理能力。模型需要理解多个高分辨率图像和图像中所示的长序列文本,并以领域知识进行回应,这需要更多的计算资源和更强大的语言模型。
另外,研究还回顾了有关将不同的多模态专家与 LLMs 相结合以解决复杂多模态理解问题的文献,其中涵盖建模范式的演变,多模态代理的概述以及如何构建多模态代理的详细内容。

以多模态代理 MM-REACT 为例,介绍了它的能力和如何扩展到整合最新的 LLMs 和其他工具中。最后,研究还讨论了如何改进或评估多模态代理以及多模态代理的多样化应用。
研究在构建基于 LLMs 的高级多模态系统方面涵盖了两个方向:训练多模态模型的方法仅利用 LLMs 来生成基于多模态输入的文本,以及多模态代理利用 LLMs 的高级规划能力来分配各种多模态工具。
两种方法各有利弊,但研究设想了一种中间领域,可以融合这两种范例的优势,并提出以下问题:既然已经有了像 LLaVA 这样的开源 LLMs,那么我们是否可以用 LLaVA 替代 LLMs 作为工具分配器?如果可以,需要哪些功能才能启用一个工具?以及指导调整可以解决哪些问题?

构建通用 AI 代理
尽管像 Flamingo 和多模态 GPT-4 等现有视觉助手已经非常强大,但与构建通用多模态 AI 代理的宏伟愿景相比,它们仍处于初步形态。为此,论文重点介绍了朝着这个目标迈进的若干研究趋势。
通用代理与多模态一体化。这与构建一个像人类一样通过多个渠道(如语言、视觉、语音和行为)与世界互动的单一通用代理的宏伟目标是一致的。从这个角度来看,多模态基础模型的概念变得有些模糊。相反,它作为代理的关键组成部分,用于感知和综合视觉信号。
与人类意图保持一致。AI 对齐研究侧重于引导 AI 系统朝向人类预期目标、价值观或伦理准则发展。尽管语言在表达人类意图方面表现出其普遍性,但并不总是最佳选择。构建包含多模态人机交互界面的基础模型是解锁新使用场景的关键步骤,其中人类意图最好以视觉方式表示。例如,场景内元素的空间排列,以及视觉艺术作品的艺术风格和视觉吸引力。
另外,根据以往研究框架,该研究预见了多模态基础模型在 AI 代理系统中的作用。其中包括计划、记忆和工具使用。
计划:为了在现实世界情境中完成复杂任务,代理应该能够将大型任务分解为较小、可管理的子目标,从而实现对复杂任务的高效处理。在理想情况下,AI 代理应该具备自我改进的能力,进行对以前行动的自我评估和反思,使其能够从错误中学习,并改进其方法以进行后续尝试,最终实现更好的结果。
记忆:对于短期记忆,采用上下文学习(或提示)作为模型的短期记忆,以便学习。交织的多模态提示可以使新情景更清晰地表达人类意图。对于长期记忆,它为代理提供了在长时间会话中召回外部知识的能力,可以通过从多模态向量空间快速检索来实现。在建模方面,基础模型需要学习新的技能,以有效地利用这两种类型的记忆。
工具使用:代理学会利用外部 API 获取基础模型权重中缺失的知识。在几种情境下,需要新的能力来处理视觉模态。例如,基于输入的视觉信号和指令,模型决定并计划是否需要某些外部API 来完成目标,例如执行检测/分割/OCR/生成专家的代码执行。
多模态基础模型领域正在以快速的速度发展,新的方向和方法经常涌现。由于每日不断更新的研究创新,该论文还有许多未讨论的研究主题。但是,总体而言,该论文提供了一份全面而及时的综合调查,涵盖了现代多模态基础模型的各个方面,为读者提供深入了解多模态基础模型开发领域的视角。
作者在文中表示:“我们对多模态基础模型的未来充满信心,这不仅因为我们确信,通过追随 LLMs 的道路,可以在不久的将来实现个别领域中可预见的研究创新和思想,还因为将计算机视觉与更广泛的 AI 社区联系起来,构建通用 AI 代理将显著提升人类的日常生活水平。”
更多细节详见原论文:https://arxiv.org/abs/2309.10020
本文来自微信公众号:学术头条(ID:SciTouTiao),作者:Hazel Yan,编辑:佩奇
相关推荐
科技创新2030—“新一代人工智能”重大项目《“数据-模型-知识”增强的多模态基础模型学习与压缩关键技术》正式启动
APUS发布多模态大模型“AiLMe”
360 发布视觉大模型,周鸿祎:多模态大模型与物联网结合是下一个风口
一文读懂F8大会亮点:小扎潜心隐私,新品乏善可陈
8K退烧:一文读懂手机8K视频功能“公开的秘密”
一文读懂:AI Agents究竟是什么?
5G最强优势亦是最大弱点?一文读懂5G背后的科技与商业
从中超、CBA零元卖队到湖人遗产忠诚继承,一文读懂俱乐部退出简史
消息称蚂蚁集团正研发语言和多模态大模型 定名“贞仪”
一文读懂苹果信用卡,Apple Card中国能办吗?
网址: 一文读懂“多模态基础模型” http://www.xishuta.com/newsview92170.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95064
- 2人类唯一的出路:变成人工智能 20149
- 3报告:抖音海外版下载量突破1 19949
- 4移动办公如何高效?谷歌研究了 19373
- 5人类唯一的出路: 变成人工智 19255
- 62023年起,银行存取款迎来 10226
- 7网传比亚迪一员工泄露华为机密 8342
- 8五一来了,大数据杀熟又想来, 7703
- 9滴滴出行被投诉价格操纵,网约 7326
- 10顶风作案?金山WPS被指套娃 7158



