对话 Moonshot AI 杨植麟:闭源是通往超级 APP 的唯一通路
The Information 今年 6 月评选了五家最有可能成为中国 OpenAI 的公司:上榜的分别是 MiniMax、智谱、澜舟科技、光年之外,以及杨植麟创立的 Moonshot AI。
相比王小川、王慧文这些互联网时代的风云创业者,杨植麟在公众中的知名度稍逊。但在 AI 圈和创投圈眼中,他在这一波大模型创业浪潮中的关注度丝毫不弱于前二者。
今年 31 岁的杨植麟是典型的学院派创业者。根据机器之心此前的报道,2015 年从清华计算机系毕业后,杨植麟前往美国卡内基梅隆大学攻读博士,师从苹果 AI 研究负责人 Ruslan Salakhutdinov 和谷歌首席科学家 William Cohen。
博士期间,杨植麟先后以一作身份,发表 Transformer-XL 和 XLNet 两项工作,谷歌学术被引次数近两万。Transformer-XL 成为首个全面超越 RNN 的注意力语言模型,论文成为 NeurIPS 2019 与 ACL 2019 的最高引论文之一;XLNet 则在 20 项任务上超越谷歌 BERT 模型,一鸣惊人。
根据 GitHub 上的个人资料,杨植麟曾在 Google 和 Meta Platforms 的人工智能实验室工作。在创立 Moonshot AI 前,杨植麟还与他人共同创立了循环智能(Recurrent AI),红杉中国也对该公司进行了投资。据该公司网站称,Recurrent AI 为销售人员开发工具。
杨植麟的学术和创业实践背景,让 Moonshot AI 成为了投资机构追逐的明星项目。据极客公园了解,今年 3 月成立以来,Moonshot AI 累计已经获得近 20 亿元融资,投资方包括红杉资本、今日资本、砺思资本等知名投资机构。
10 月 9 日下午,Moonshot AI 在北京首次举行媒体沟通会,杨植麟接受了包括极客公园在内的多家科技创投媒体的群访。
他在会上分享了 Moonshot AI 未来的发展规划,坚定表示将专注 ToC,并会以“长文本输入”为核心构建其底座大模型的差异化竞争力。他认为这是行业现在最需要解决的问题,也是通往下一步产品化路上的最大卡点。之后他们不会拘泥于单一产品,而是多个产品共同发展,可能的方向包括生产力工具、娱乐产品等。
而对于开源和闭源,杨植麟也发表了自己的看法,认为像 OpenAI 一样的闭源是通往 Super APP(超级应用)的唯一通路,而开源只是 ToB 的获客手段。“凡要做 C 端超级 APP 的,都是闭源。”
以下是杨植麟对话实录,由极客公园节选整理。
专注 ToC 的大模型公司
问:Moonshot 是一家怎样的公司?
杨植麟:我们是一个大模型公司,成立于今年 3 月份。
我最喜欢的一张专辑是英国摇滚乐队平克·弗洛伊德的《The Dark Side of the Moon》(月之暗面)。今年 3 月份刚好是这个专辑发布 50 周年,也是我们公司成立的日子,(名字)跟月亮无关,想去探索宇宙的未知。因为月亮其实它的背面一直都是看不到的,你只能看到它正面,但它的背面其实很让人好奇。
问:Moonshot 最大的特色是什么?
杨植麟:我觉得最主要的一个特色,其实是我们的人才密度。团队非常多的成员有训练超大模型的经验,包括参与了 Google 的下一代多模态模型 Gemini 的核心开发;在 Google 训练大几千亿参数的经验;也包括国内最早的大模型悟道、盘古的原班人马。
还有成员参与开发过一些世界上非常领先的技术,这些技术在很多大家耳熟能详的模型或产品里得到了使用,比如像 Stable Diffusion 里面有一个非常关键的模块,叫 group normalization,也是我们团队的成员作为第一作者开发的。同时也包括,比如说像 rope 这种 positional encoding,也得到了广泛使用,在 Meta 的 LLaMa 的模型,Google 的 Palm 模型这些大家耳熟能详的模型里面,部分关键技术的第一作者都加入了我们团队。不光是技术人才,产品方面,我们也吸纳了非常出色的一些人,包括有过几亿 DAU 的产品经验,很多有从 0 到 1 产品经验的天才加入。
我们希望通过这种很高的人才密度以及组织力量,能够打造一个很快迭代的组织机器,让人才能够快速基于我们现有和未来发展出的技术,开发出比较好的产品。
问:Moonshot AI 的客户场景 ToB 还是 ToC?
杨植麟:Moonshot AI 是专注 ToC 的公司,现在最高优先级的任务是在 C 端找到产品、技术以及市场的方向。但同时我们也会以开放心态去做更多 B 端以及具体行业的一个方向。
问:之前你的创业经验在 ToB,这次成立月之暗面,想做什么样的事情?
杨植麟:现在成立公司做这个事情最主要还是几个点:
第一个是出于对未知的探索、对智能边界的好奇心,想去探索未知。
第二层很关键,希望这个东西探索之后,对这个世界是有用的。我们希望能跟用户去一起去共创这个所谓的通用泛化的智能,而不是自己闭门造车、做了一些技术号称实现 AGI。更多会跟很多用户一起去共创、去打磨、去真正找到有用的场景来落地。
第三个很关键的点,我们希望最终的 AI 是普惠的,或者用更容易理解的一个词,个性化。包括我们今天讲的 long context,其实也是个性化很重要的基础。每个人可能都需要不一样的 AI,那怎么能让他在像微调这种方式以外,有更便捷、更强大的方式做个性化?我最终希望的,其实也是通过技术和产品的结合,去达到 AI 真正的普惠。
问:过去在循环智能做 ToB,MoonShot 却选择做C端产品,这个想法怎么来的?
杨植麟:我们做 ToC 其实还是以终为始来看这个问题。像刚刚说的,我们最终想去探索智能边界,想让它真正有用,想去做个性化。
以终为始去讨论的话,最终需要的一个很重要的东西,是能够有非常快速的迭代效率,不管是在技术、还是产品侧能够去快速去推进。所以迭代效率可能是我们现在最重要的一个关键词。
那迭代效率的话,我觉得 ToC 是一个非常自然的选择。它会决定你的企业文化、他会决定你的人才结构、他也会决定你最终到底是用什么样的思路、做出来什么样的事情。所以把这几个维度加起来,你发现其实只有 ToC 这一条路。
而且,每个时代,当有新的技术变革时,都会产生很多新的 Super APP。从市场的存在性的角度来讲,我觉得大模型赛道大概率也会出现,所以这是我们现在最关注的一个方向。
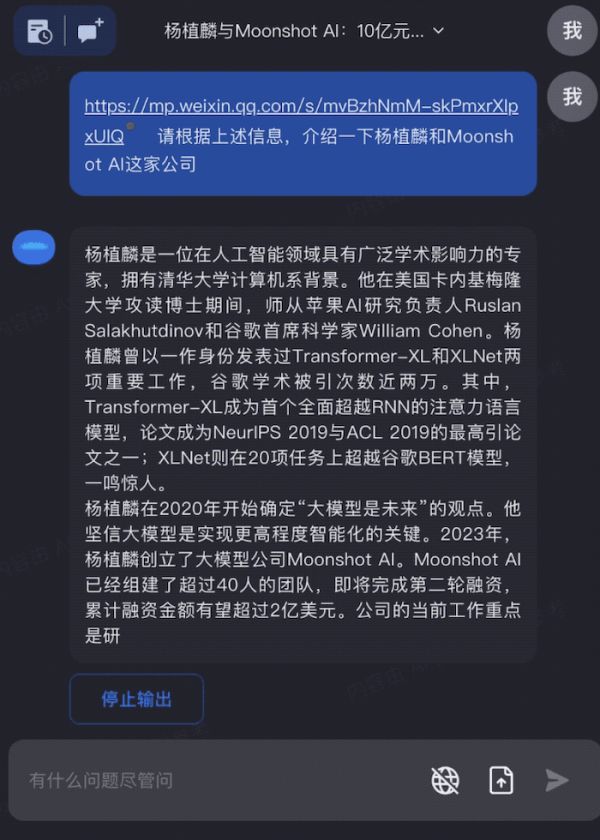
Moonshot 对话机器人 Kimichat 总结公众号文章丨来自:Moonshot
问:ToC 似乎比 ToB 更难,怎么考虑商业化落地?有什么现有场景和案例?怎么看待竞争的问题?
杨植麟:现在已经就是有大量的迹象证明,通过 AI native 的产品产生了新的流量入口,基于此,去做 Super APP 会是一个非常巨大的机会,但这个 Super APP 需要产品和技术很好地结合。现在很难说基于一个开源的模型就能够去做一个非常好的 Super APP,因为 Super APP 肯定是要给用户提供最好的体验,这个是我们接下来要去做的方向。
关于竞争的问题,我觉得其实最终考验的还是能不能在技术上做到领先,同时能不能用最快的速度在产品上找到落地点。
问:在模型和应用上,你们怎么分配资源?
杨植麟:成本结构、资源分配其实还好。更关键的点是:这些不同的团队,产品和技术应该怎么合作。我们内部形成了一套,相对来说比较高效的、创业式的协作方式,能够让他们通过模型评估这个中间桥梁,把技术和产品快速连接起来,一起探索变化,快速迭代。
我认为这其实也是大模型公司最需要具备的一个组织能力,需要一个很快速的迭代能力,在有一个大模型机构的情况下,能够去快速探索、天然试错,因为它试错的方式其实跟传统的互联网完全不一样。这是我们非常关注去建设的。
问:未来要做多模态,什么时候会做出来?
杨植麟:多模态的时间点,我们预期应该会在明年,具体也会有更多信息后面跟大家分享。
“长文本输入”是行业最需要解决的问题
问:为什么支持长文本的输入,是产品化路上最大的卡点?
杨植麟:我们把“长文本”称作我们登月计划的第一步,其实是基于一个朴素的判断。如果我们去看模型的参数量,这个参数量可能是大家比较熟悉的,它决定了你能够支持多复杂的计算。如果类比计算机的话,它其实是你的这个 CPU 能支持的这个指令集到底有多复杂,你能处理多复杂的计算。
而上下文对应的其实是计算机的内存,如果我们去看计算机系统的发展,可能最近几十年内存发生了翻天覆地的变化。比如说像超级玛丽的第一版,使用的内存就是非常非常低,可能是兆级别,甚至更少。但我们如果去看现在的应用,它的内存都是至少是几 GB,甚至是更多的。所以我们认为不光是要有足够多的参数量,同时你要有很强的上下文,这个上下文是标志着新一代的这种大模型的配置,所以我们把这个作为我们的登月计划的第一步,去率先突破了这个能力,那我们后面其实也会去结合这个能力去做更多新的延展,就像我们刚刚说的去与用户去共创通用的智能,然后去探索更多实际落地和智能的突破。
问:MoonShot 的模型参数多大?
杨植麟:我们是千亿参数。
如果你只是一个10亿参数的模型,那么即使上下文做到1亿都没用,因为它的计算能力相对有限。而当计算足够复杂时,需要有足够大的内存来管理这个过程。
问:为什么把上下文长短作为需要解决的最重要的问题?
杨植麟:我们观察到现有的市面上,所谓的长文本的解决方案,其实都是在走捷径。但其实去看计算机系统发展的历史,一个必然的趋势是,都是从最开始的很小内存的计算机服务,再到很大的内存的服务。
所以我觉得大模型肯定也是会有一样的趋势,从现在很少内存的大模型,到以后的很大内存。而且这个可能是决定模型的应用最关键的因素之一,我们是觉得这里面它的重要性其实非常大,然后另一个是刚刚说到的参数量。
但同时,除了这个点之外,我们肯定不仅仅只做长文本,还会在更多的技术维度发力,做到世界领先水平。
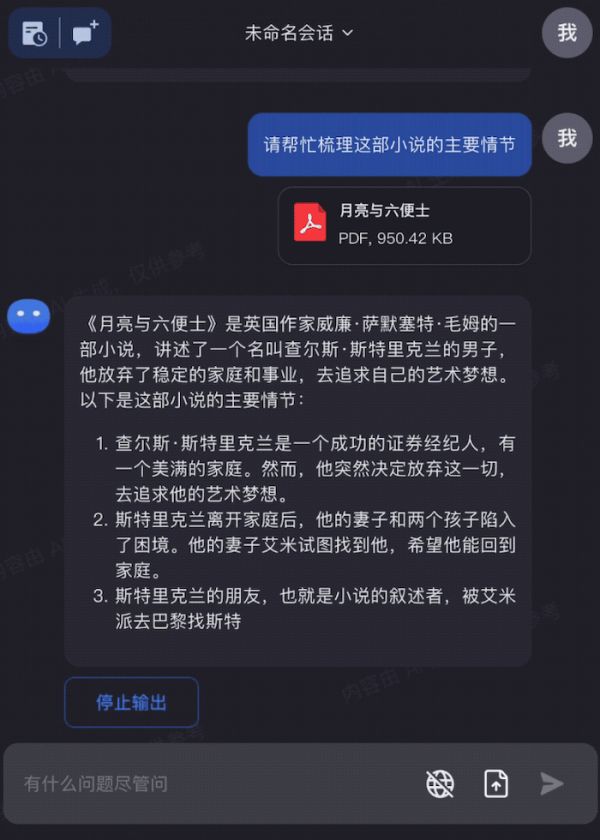
Kimi chat 总结《月亮与六便士》一整本书的内容丨来自:Moonshot
问:你说的一些解决方案是“走捷径”,具体怎么理解?
杨植麟:解决上下文长短问题的背后,会有很多不同的技术路径,其实这里面会有一些捷径,我们提炼出来三种可能的方案。
第一种捷径是去训练一个这个我们称之为金鱼模型,因为金鱼的记忆非常短暂,所以现在很多这个所谓的长上下文的模型,你别看他说的很长,实际上他采用比如说这种滑动窗口的方式,直接我可能主动抛弃了很多上文。所以这个时候虽然我号称能支持长文本,但是实际上它是很难解决任何任务。比如刚我们去上传这个 50 个文档,对吧?然后让他去结合这个东西进行总结,那如果是个金鱼模型就没有办法做。
第二种捷径我们称之为这个叫蜜蜂模型,因为蜜蜂很多时候它是关注局部,忽略了全局,所以其实也有一种捷径,就是说对于上下文,我可能只是采样其中的一部分,比如现在像 RAG(retrieval augmented generation)的方法,基于检索增强的方法,其实就是一个蜜蜂模式,还有很多任务也没有办法做。比如说我刚传了一本《非暴力沟通》,然后我基于这个东西去给他提很多问题,那他需要结合整本书的信息来做,蜜蜂模型就解决不了问题。
第三种模型我们称之为这个蝌蚪模型,它是一个能力不够的模型,是一个小模型,比如说我今天当然可以去训练一个 10 亿参数的模型,那你这样就可以很容易轻易的做到一个非常长的文本,但是也没有用,因为它能力达不到,所以你光有这个长文本其实是不够的。所以不管是金鱼模型、蜜蜂模型,还是蝌蚪模型,其实它都没有办法真正能够到产品化的效果。我们只有真正去面对这里面的核心的技术挑战,然后正面去解决这些问题,你才有可能真正达到产品化的效果。所以我们在这里面其实做了非常多的算法和工程优化,去实现一个真正的长项效果,而不是一个走捷径的上下文。这里面不管是存储还是算力还是带宽,其实我们都做了非常非常多的优化,去实现一个真正可用、可产品化的长文本大模型。
问:支持长文本的输入,怎么控制计算资源、成本?
杨植麟:在这里面我们从算法和工程的角度其实都做了非常多的针对性的优化,让这个东西能够用一个产品化的形式去面向用户,具体有很多技术细节。
比如从计算的角度来看,如果是直接做全注意力机制,它的算力复杂度是平方级增长,需要的带宽也很大,它需要的显存即便用现在配置最高的单机,也只能支持到 64K。
问:Moonshot 推出的首款大模型产品智能助手 Kimi Chat 有哪些典型场景?
杨植麟:可能的应用场景其实非常多,包括生产力、娱乐层面的一些场景都可以。
刚刚我也提到就是比如说基于这种很长的这个上下文去做这种角色扮演,最后预期就是说你可能每个人可能都会拥有一个有着终身记忆的这样一个陪伴的角色,那其实这是一个非常关键的任务,如果去看 character AI 的很多反馈,就会发现就是它这种上下文的理解能力,其实在很大程度上限制了这个应用,因为它可能会遗忘之前的交互,那么这个对于用户说就是一个非常糟糕的体验,我觉得这是一个点。

只需要一个网址,就可以在 Kimi Chat 中和自己喜欢的原神角色聊天|来源:Moonshot
然后可能比如说往下走,如果是 agent 这个角度的话,其实也会有非常多的空间,因为它是需要完成复杂的任务,包括跟用户本身去做投影,去建立这种共生的关系,就他应该能看到你所有的这个知识和文档,包括外部的知识和内部的知识,所以它潜在能完成的任务其实会是非常非常多的。
所以我们相信就说不管是在生产力工具层面,还是说在娱乐层面,其实它都可以去解决更多新的场景。
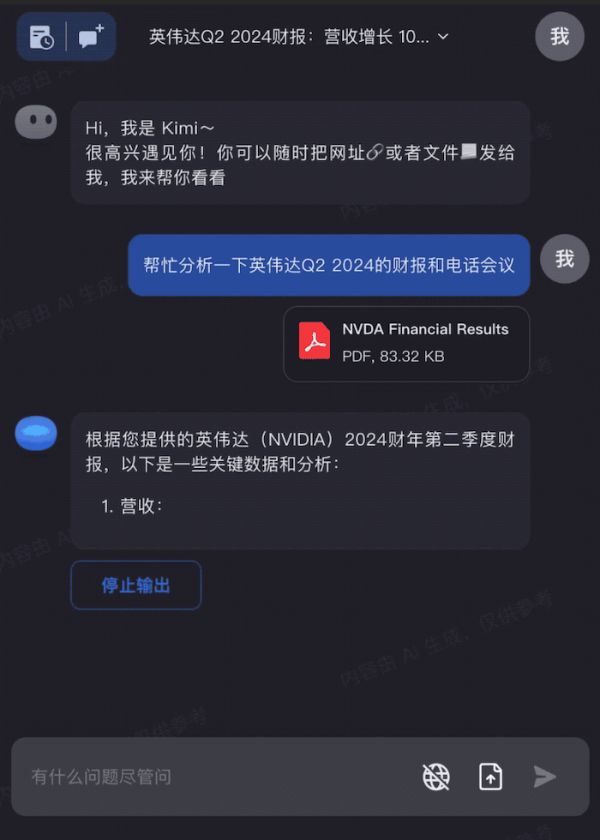
新鲜出炉的英伟达财报,交给 Kimi Chat,快速完成关键信息分析|来源:Moonshot
问:现在做长文本的公司有很多,能不能给我们介绍一下思路和难点?你们的技术路线相比其他公司的优势?
杨植麟:做长文本,不管是存储、算力还是带宽,消耗其实都非常大。我们要去真正克服这些困难,在这里面做了算法的优化。
这里面其实主要包含两个部分,一个是说需要对网络结构进行优化,一个是在工程上做优化。
有一种捷径是采用我们刚刚说过的蜜蜂模式,就是你可能会把文本分段,每段分别去做嵌入,然后再去做检索,但这种方式的问题是支持不了理解全文的场景。
但我们的模型,它是完整的上下文接入,也就是它可以基于不管是 50 个文档还是 10 个链接,是可以同时对这些内容去进行处理的。
问:相对于国内市面上的大模型,比如智谱和深言科技,在大模型长文本的优势上,月之暗面领先多少?
杨植麟:据我们所知,其他家目前还没有(支持这么长的文本)。
问:突破长文本最大的突破卡在 GPU,你怎么看?
杨植麟:GPU 肯定是一个很重要的一个基础,但这里面不光是 GPU 的事情,而是很多不同因素的结合,一方面是 GPU,一方面是所谓的能源转换成智能的效率,那这个效率里面拆解出来可能就会有算法的优化、工程的优化、模态的优化、上下文的优化这些因素,最后会是这些因素的结合。
如果我们更全局地看这个事情,如果你把 AI 看成一个黑盒子,它就是往里面去加入很多能源,然后把这个能源转化成智能的一个过程,有点像发电一样,只是说它的输入和输出不一样。
那 GPU 它本身它只是在这个转换过程中去把能源利用起来的一种方式,但是理论上只有 GPU 肯定是不够的,所以我觉得最后会是这几种不同的因素的结合,我们今天其实也是把这几种不同的因素去结合起来。
问:上下文输入过程,其实会导致注意力分散,你怎么看这一问题?
杨植麟:注意力分散确实是一个挑战。比如说当你的输入有 20 万字的时候,你让这个模型准确去 attend 到某一个 token 上的难度肯定是会变大。所以在这里面其实你就需要一些更高效的一些对齐的方式,就是你在这里面怎么去高效的得到好的数据,怎么得到一个高效的公式,同时还有公式化的方式,去把它实现出来,所以这个其实需要很很多大量的迭代的训练,所以我觉得这个本身它也是一个很大的挑战,并且是传统的金鱼模型和蜜蜂模型无法解决的问题。
问:输入 20 万字,是指上下文的窗口长度是 200k 吗,还是比较短的训练长度,可以外推到 20 万字?
杨植麟:对,它的上下文长度是 20 万字,然后我们不是通过外推的方式,因为外推其实我刚才也说了,是走金鱼模型的捷径。我们没有用外推的方式。
问:长文本输入时,怎么限制幻觉?
杨植麟:限制或者减少幻觉本身就是长文本场景的一个优点。如果我现在不给它任何上文,不给他任何知识,其实出现幻觉的概率是更大。但我如果现在已经给了上文,那它就会基于规定内容来分析,这其实很大程度降低了幻觉。
问:如果文本输入过长,模型可能很难准确抓住每个部分的要点,你怎么看待?比如如果信息出现在中间部分,回答的准确率会下降?
杨植麟:我们的模型,其实对于它出现在哪里,本身可能没有那么相关,因为还是跟你的技术路线有关系。比如说你如果是一个金鱼模式,那你就出现在什么地方,它就会很受影响,因为它只能记住一小部分。但是对我们来说,是整个上下文完整输进去了。
所以在这里面其实相对来说会没有那么明显,但同时也会有更多的其他的技术优化去保证。
问:你们的长文本输入,更强调整体思维。怎么理解整体思维?
杨植麟:第一个关键词是,全局,怎么让全局的上下文输入。第二个关键词是有很大参数规模的情况下去做这件事,不是说我现在拿一个 10 亿参数量的模型去做,这本身没有意义。所以我觉得是在这两条很重要的前提下去做。
问:支持上下文输入,有很多评测框架,认同哪个?
杨植麟:暂时还没有非常好的评测。我们内部其实做了大量的建设,而且我认为整个领域在这个评测上可能确实也需要做更多的工作,来把更多的标准或者更多的评测需求提出来。我们目前更多是以内部的效果作为迭代的指标。
问:未来想做的具体方向是什么?
未来,我们肯定还是会以在这个领域的技术的领先性不断的去扩充版图。大模型公司不可能说只局限在一个很狭窄的方向上,因为这是它的成本结构所决定的。不管是娱乐、还是生产力的工具与场景,还有多模态,我们都会去做尝试。
开源是获客手段,闭源才是超级 APP 的唯一通路
问:Transformer 有限制,会只是一个中间态吗?
杨植麟:我觉得是一个中间态,而且它是一个持续演化的过程,最后量变才能质变。因为所有东西它都是一个这种组合式的演进,比如 Transformer,本身它也是 Attention 加 Resnet 加 Layernorm 合起来的。
这几个东西其实在 Transformer 之前就存在了,所以我觉得它会是一个渐进式的演变,比如说 GPT 4,他们用的肯定不光只是 Transformer 结构。包括我们也是,所以我觉得在这个连续演进的过程中,最后肯定它不会是跟原来的 Transformer 一样,反正演进到一定程度,它就可能量变产生质变,它就可能是大家认为是一个新的架构(architecture),所以我们肯定会是这样的一个过程。
问:您觉得未来国内大模型的格局会是怎么样的?
杨植麟:我觉得首先会分成 ToB 和 ToC,它就可能是两个不同的阵营。然后我们肯定是坚定在 ToC 这个阵营,然后 ToC 的话就是会有头部的 Super APP,我认为这些 Super APP 会是基于自研的模型做出来的,因为需要在用户体验上能够有差异化,我们是希望能够在 Super APP 里面去占领一个比较好的位置。
但同时我们还会觉得可能会出现一个长尾的各种各样的应用,这样的应用就有可能是基于开源模型去做。
问:Moonshot AI 会有开源的计划吗?
杨植麟:我们是这么看,开源本身是 ToB 的获客工具。开源闭源扮演不同角色,最后共生,Moonshot AI 用闭源的方式做,是持续演化的过程。
对于开源我们是这么看,它本质上还是一个 ToB 的获客工具。所以你的开源策略其实完全取决于你最后的产品和商业化的策略。所以我们在这里面肯定是更专注的是去把 C 端的东西做好,这个是我们非常重要的核心的一个战略。
然后我觉得就像我刚刚说的,开源和闭源在整个生态里面它会扮演不同的角色,最 top 的几个 Super APP,大家都是用闭源方式重新做的,因为你最后拼的是用户体验。
但是长尾的应用,可能会有大量是基于开源做的,我觉得最后其实是一个共生的关系。但在这里面我们肯定是瞄准,就是说用闭源的方式去把 super APP 做好。我们暂时没有开源的计划。
问:闭源才能做出 APP,这个认知怎么出来的?
杨植麟:对,其实现在有非常多的证据来支撑这个观点。我们看到的基本上所有做的好的公司,都是做得好的 C 端的公司,它其实都是基于闭源模型来做的。
背后的逻辑也很好理解,就是如果你是基于开源去开发一个东西,比如说像基于 stable diffusion 开发一个东西,之前在美国可能有 400 个不同的 APP,但最后其实没有任何一个跑出来。
最主要一个点是你没有办法通过开源去形成很强的产品上的开发。第二个点是你没有办法通过这种技术,这种数据的虹吸效应能让你的这个模型持续地优化,因为你的开源本身是分布式的部署,每个人部署一块,没有一个集中式的地方让你收集数据。
所以我觉得这个不管是说从底层逻辑,还是说我们从现在观察到的情况来说,我都坚定认为说最后的 Super APP 肯定是你需要用自己的模型。
问:在大模型创业里边,清华系是占了半壁江山,对此您有什么感受?
杨植麟:这个我觉得更多的倒不是一个问题,我觉得是大家可能共同的去对这个领域产生贡献,因为这里面的空间非常大,我觉得很难有任何一家公司说他可以把所有的事情都做了。
所以我觉得大家可能更多,比如说你 ToB 的 ToC 可能就不一样,比如说你做不同的 C 端的尝试,或者你做不同的技术路线也不一样,所以我觉得这个是一个巨大的空白的空间。除了 OpenAI 之外,除了中国这几个公司之外,我觉得可能每个人在这里面都会有机会去产生自己独一无二的价值。
本文来自微信公众号:极客公园 (ID:geekpark),作者:宛辰、连冉,编辑:郑玄
相关推荐
都怪清华?中国版Open AI开卷五道口
快手APP内测“AI对话”
AI的新规则(五):Facebook赌下一代接口是“对话”
经纬张颖:AI的远与近
通往5G之路 | 有「AI」的5G
争鸣:OpenAI奥特曼、Hinton、杨立昆的AI观点到底有何不同?
非常时期:健身房闭店,集体转向线上直播
Meta启示:AI是通往元宇宙的关键变量
为什么说创业者做AI大模型完全是浪费钱?
用“擦边”留住你的AI女友,性感背后藏着危险
网址: 对话 Moonshot AI 杨植麟:闭源是通往超级 APP 的唯一通路 http://www.xishuta.com/newsview93392.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95228
- 2人类唯一的出路:变成人工智能 21183
- 3报告:抖音海外版下载量突破1 21148
- 4移动办公如何高效?谷歌研究了 20339
- 5人类唯一的出路: 变成人工智 20338
- 62023年起,银行存取款迎来 10336
- 7五一来了,大数据杀熟又想来, 8596
- 8网传比亚迪一员工泄露华为机密 8505
- 9滴滴出行被投诉价格操纵,网约 8215
- 10顶风作案?金山WPS被指套娃 7230



