英伟达芯片,最新路线图
来源:半导体行业观察
众所周知,随着生成式AI的大热,英伟达正在数据中心领域大杀四方,这也帮助他们实现了更好的业绩。根据公司公布的数据,截至 2023 年 7 月 30 日的第二季度,英伟达收入为 135.1 亿美元,较上一季度增长 88%,较去年同期增长 101%。
不过,英伟达目前的业绩预期很多都是基于当前的芯片和硬件所做的。但有分析人士预计,如果包含企业 AI 及其 DGX 云产品,该数据中心的市场规模将至少是游戏市场的 3 倍,甚至是 4.5 倍。
瑞银分析师Timothy Arcuri也表示,英伟达目前在DGX云计算方面的收入约为10亿美元。但在与客户交谈后,他认为,该公司每年可能从该部门获得高达100亿美元的收入。他给出的理由是Nvidia仍然可以在DGX云上添加额外的产品,包括预先训练的模型,访问H100 GPU等等。他说,现在这些领先GPU仍然“非常难”获得访问,能够根据需要扩大和缩小规模,并与现有的云或内部部署基础设施“基本上无缝集成”。
因此,英伟达在最近公布了一个包括H200、B100、X100、B40、X40、GB200、GX200、GB200NVL、GX200NVL 等新部件在内的产品路线图,这对英伟达未来的发展非常重要。
数据中心路线图
根据servethehome披露的路线图,英伟达的一项重大变化是他们现在将其基于 Arm 的产品和基于 x86 的产品分开,其中 Arm 处于领先地位。作为参考,普通客户现在甚至无法购买 NVIDIA Grace 或 Grace Hopper,因此在 2023-2025 年路线图的堆栈中显示它是一个重要的细节。以下是 NVIDIA 提出的路线图:
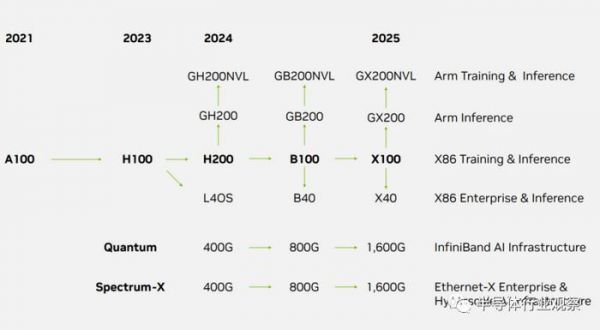
在Arm方面,英伟达计划将在2024年推出GH200NVL,在2024年推出GB200NVL,然后在2025年推出GX200NVL。我们已经看到 x86 NVL 系列与NVIDIA H100 NVL一起推出,但这些都是基于 Arm 的解决方案。然后是 2024 年推出的 GH200NVL。还有快速跟随的 GB200NVL,然后是 GX200NVL。还有非 NVL 版本。
在NVIDIA 宣布推出双配置的新型 NVIDIA Hopper 144GB HBM3e 型号(可能最终成为 GH200NVL)的时候,我们介绍了具有 142GB/144GB 内存的 GH200 (非 NVL)。据介绍,与当前一代产品相比,双配置的内存容量增加了 3.5 倍,带宽增加了 3 倍,包括一台具有 144 个 ArmNeoverse 核心、8 petaflops 的 AI 性能和 282GB 最新 HBM3e内存技术的产品。

GB200 将成为 2024 年的下一代加速器,GX200 将成为 2025 年的下一代加速器。
面向 x86 市场,英伟达预计 2024 年将推出 H200,它会在 Hopper 架构上进行更新,并具有更多内存。B100和B40是下一代架构部件,随后是2025年的X100和X40。考虑到B40和X40位于“企业”赛道上,而当前的L40S是PCIe卡,因此这些可能是PCIe卡。
在网络方面,Infiniband 和以太网都将于 2024 年从 400Gbps 发展到 800Gbps,然后在 2025 年达到 1.6Tbps。鉴于我们已经在 2023 年初研究了 Broadcom Tomahawk 4 和交换机,并看到了合作伙伴今年的800G Broadcom Tomahawk 5 交换机,感觉有点像 NVIDIA 以太网产品组合在以太网方面明显落后。Broadcom 的 2022-2023 年 800G 系列似乎与 NVIDIA 的 2024 年升级保持一致,NVIDIA 在 2023 年中期宣布了 Spectrum 4,而Tomahawk 5 则在大约 21-22 个月前宣布。在业界,芯片发布与投入生产之间通常存在很大的差距。

由此可见,在 Infiniband 方面,NVIDIA 是孤军奋战。从该路线图中,我们没有看到 NVSwitch/NVLink 路线图。
其他人工智能硬件公司应该会被 NVIDIA 的企业人工智能路线图吓到。在人工智能训练和推理领域,这意味着 2024 年将更新当前的 Hopper,然后在 2024 年晚些时候过渡到 Blackwell 一代,并在 2025 年采用另一种架构。
在 CPU 方面,我们最近已经看到了令人激动的更新节奏,x86 方面的核心数量之战出现了大幅增长。例如,英特尔的顶级 Xeon 核心数量预计从 2021 年第二季度初到2024 年第二季度将增加 10 倍以上。NVIDIA 在数据中心领域似乎也在紧跟这一步伐。对于构建芯片的人工智能初创公司来说,考虑到 NVIDIA 的新路线图步伐,这现在是一场竞赛。
对于英特尔、AMD,或许还有 Cerebras 来说,随着 NVIDIA 销售大型高利润芯片,他们的目标将会发生变化。它还将基于 Arm 的解决方案置于顶级赛道中,这样它不仅可以在 GPU/加速器方面获得高利润,而且可以在 CPU 方面获得高利润。
一个值得注意的落后者似乎是以太网方面,这感觉很奇怪。
精准的供应链控制
据semianalysis说法,英伟达之所以能够在群雄毕至的AI芯片市场一枝独秀,除了他们在硬件和软件上的布局外,对供应链的控制,也是英伟达能坐稳今天位置的一个重要原因。
英伟达过去多次表明,他们可以在短缺期间创造性地增加供应。英伟达愿意承诺不可取消的订单,甚至预付款,从而获得了巨大的供应。目前,Nvidia 有111.5 亿美元的采购承诺、产能义务和库存义务。Nvidia 还额外签订了价值 38.1 亿美元的预付费供应协议。单从这方面看,没有其他供应商可以与之相媲美,因此他们也将无法参与正在发生的狂热AI浪潮。
自 Nvidia 成立之初起,黄仁勋就一直积极布局其供应链,以推动 Nvidia 的巨大增长雄心。黄仁勋曾在重述了他与台积电创始人张忠谋的早期会面中表示:
“1997 年,当张忠谋和我相遇时,Nvidia 那一年的营收为 2700 万美元。我们有 100 个人,然后我们见面了。你们可能不相信这一点,但张忠谋曾经打销售电话。你以前经常上门拜访,对吗?你会进来拜访客户,我会向张忠谋解释英伟达做了什么,你知道,我会解释我们的芯片尺寸需要有多大,而且每年都会变得越来越大而且更大。你会定期回到英伟达,让我再讲一遍这个故事,以确保我需要那么多晶圆,明年,我们开始与台积电合作。Nvidia 做到了,我认为是 1.27 亿,然后,从那时起,我们每年增长近 100%,直到现在。”

张忠谋一开始不太相信英伟达需要这么多晶圆,但黄仁勋坚持了下来,并利用了当时游戏行业的巨大增长。英伟达通过大胆供应而取得了巨大成功,而且通常情况下他们都是成功的。当然,他们必须时不时地减记价值数十亿美元的库存,但他们仍然从超额订购中获得了积极的收益。
如果某件事有效,为什么要改变它?
最近这一次,英伟达又抢走了SK海力士、三星、美光HBM的大部分供应,这是GPU和AI芯片正在追逐的又一个核心。英伟达向所有 3 个 HBM 供应商下了非常大的订单,并且正在挤出除Broadcom/Google之外的其他所有人的供应。
此外,Nvidia 还已经买下了台积电 CoWoS 的大部分供应。但他们并没有就此止步,他们还出去考察并买下了Amkor的产能。
Nvidia 还利用了 HGX 板或服务器所需的许多下游组件,例如重定时器、DSP、光学器件等。拒绝英伟达要求的供应商通常会受到“胡萝卜加大棒”的对待。一方面,他们可以从英伟达那里获得看似难以想象的订单,另一方面,他们也面临着被英伟达现有供应链所设计的问题。他们仅在供应商至关重要并且无法设计出来或多源时才使用提交和不可取消。
每个供应商似乎都认为自己是人工智能赢家,部分原因是英伟达从他们那里订购了大量订单,而且他们都认为自己赢得了大部分业务,但实际上,英伟达的发展速度是如此之快,甚至已经超出了他们的想想。
回到上面的市场动态,虽然 Nvidia 的目标是明年数据中心销售额超过 700 亿美元,但只有 Google 拥有足够的上游产能,能够拥有超过 100 万个规模的有意义的单元。即使AMD最新调整了产能,他们在AI方面的总产能仍然非常温和,最高只有几十万台。
精明的商业计划
众所周知,Nvidia 正在利用 GPU 的巨大需求,利用 GPU 向客户进行追加销售和交叉销售。供应链上的多位消息人士告诉semianalysis,英伟达正在基于多种因素对企业进行优先分配,这些因素包括但不限于:多方采购计划、计划生产自己的人工智能芯片、购买英伟达的 DGX、网卡、交换机和光学器件等。
Semianalysis指出,CoreWeave、Equinix、Oracle、AppliedDigital、Lambda Labs、Omniva、Foundry、Crusoe Cloud 和 Cirrascale 等基础设施提供商所面临的分配的产品数量远比亚马逊等大型科技公司更接近其潜在需求。
据semianalysis所说,事实上,Nvidia 的捆绑销售非常成功,尽管之前是一家规模很小的光收发器供应商,但他们的业务在 1 季度内增长了两倍,并有望在明年实现价值超过 10 亿美元的出货量。这远远超过了 GPU 或网络芯片业务的增长率。
而且,这些策略是经过深思熟虑的,例如目前,在 Nvidia 系统上通过可靠的 RDMA/RoCE 实现 3.2T 网络的唯一方法是使用 Nvidia 的 NIC。这主要是因为Intel、AMD、Broadcom缺乏竞争力,仍然停留在200G。
在Semianalysis开来,Nvidia正在趁机管理其供应链,使其 400G InfiniBand NIC 的交货时间明显低于 400G 以太网 NIC。请记住,两个 NIC (ConnectX-7) 的芯片和电路板设计是相同的。这主要取决于 Nvidia 的 SKU 配置,而不是实际的供应链瓶颈。这迫使公司购买 Nvidia 更昂贵的 InfiniBand 交换机,而不是使用标准以太网交换机。当您购买具有 NIC 模式 Bluefield-3 DPU 的 Spectrum-X 以太网网络时,Nvidia 会破例。
事情还不止于此,看看供应链对 L40 和 L40S GPU 的疯狂程度就知道了。
Semianalysis透露,为了让那些原始设备制造商赢得更多的 H100 分配,Nvidia 正在推动 L40S的销售,这些 OEM 也面临着购买更多 L40S 的压力,进而获得更好的 H100 分配。这与 Nvidia 在 PC 领域玩的游戏相同,笔记本电脑制造商和 AIB 合作伙伴必须购买大量的 G106/G107(中端和低端 GPU),才能为更稀缺、利润率更高的 G102/G104 获得良好的分配(高端和旗舰 GPU)。
台湾供应链中的许多人都被认为 L40S 比 A100 更好,因为它的 FLOPS 更高。需要明确的是,这些 GPU 不适合 LLM 推理,因为它们的内存带宽不到 A100 的一半,而且没有 NVLink。这意味着除了非常小的模型之外,以良好的总体拥有成本在它们上运行LLM几乎是不可能的。高批量大小(High batch sizes)具有不可接受的令牌/秒/用户(tokens/second/user),使得理论上的 FLOPS 在实践中对于 LLM 毫无用处。
Semianalysis说,OEM 厂商也面临着支持 Nvidia 的 MGX 模块化服务器设计平台的压力。这有效地消除了设计服务器的所有艰苦工作,但同时也使其商品化,创造了更多竞争并压低了 OEM 的利润。戴尔、HPE 和联想等公司显然对 MGX 持抵制态度,但台湾的低成本公司,如超微、广达、华硕、技嘉、和硕和华擎,正在急于填补这一空白,并将低成本“企业人工智能”商品化。
当然,这些参与 L40S 和 MGX 游戏的 OEM/ODM 也获得了 Nvidia 主线 GPU 产品更好的分配。
虽然英伟达正在面临着芯片厂商和系统厂商自研芯片的夹击。但这些布局,似乎短期内都能让英伟达高枕无忧。他们依然会是AI时代最成功的“卖铲人”。
发布于:北京
相关推荐
英伟达芯片,最新路线图
英伟达公布最新路线图:下一代显卡将在2024年登场
围攻英伟达,三大巨头的芯片再出招!
消息称微软或下月公布自家AI芯片Athena,降低对英伟达依赖
三巨头围攻英伟达
英伟达CEO黄仁勋:供应链力求多元化,未来还将委托英特尔代工
英伟达为什么要革自己的命?
美国将限制英伟达AI芯片出口到部分中东国家
AMD发起AI芯片挑战,但英伟达依然独孤求败
英伟达发布首个 CPU,集齐“三芯”叫板英特尔?
网址: 英伟达芯片,最新路线图 http://www.xishuta.com/newsview93537.html
推荐科技快讯






- 1问界商标转让释放信号:赛力斯 95185
- 2人类唯一的出路:变成人工智能 20919
- 3报告:抖音海外版下载量突破1 20809
- 4移动办公如何高效?谷歌研究了 20085
- 5人类唯一的出路: 变成人工智 20072
- 62023年起,银行存取款迎来 10313
- 7网传比亚迪一员工泄露华为机密 8460
- 8五一来了,大数据杀熟又想来, 8367
- 9滴滴出行被投诉价格操纵,网约 7989
- 10顶风作案?金山WPS被指套娃 7216



