大模型是不是有点太多了?
上个月,AI业界爆发了一场“动物战争”。
一方是Meta推出的Llama(美洲驼),由于其开源的特性,历来深受开发者社区的欢迎。NEC(日本电气)在仔细钻研了Llama论文和源代码后,迅速“自主研发”出了日语版ChatGPT,帮日本解决了AI卡脖子难题。
另一方则是一个名为Falcon(猎鹰)的大模型。今年5月,Falcon-40B问世,力压美洲驼登顶了“开源LLM(大语言模型)排行榜”。
该榜单由开源模型社区Hugging face制作,提供了一套测算LLM能力的标准,并进行排名。排行榜基本上就是Llama和Falcon轮流刷榜。
Llama 2推出后,美洲驼家族扳回一城;可到了9月初,Falcon推出了180B版本,又一次取得了更高的排名。
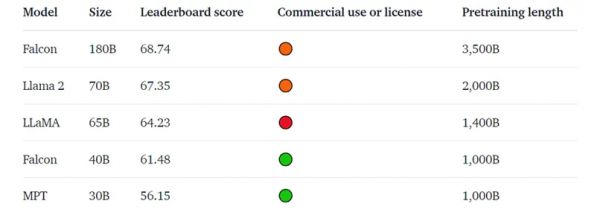
Falcon以68.74分力压Llama 2
有趣的是,“猎鹰”的开发者不是哪家科技公司,而是位于阿联酋首都阿布扎比的科技创新研究所。政府人士表示,“我们参与这个游戏是为了颠覆核心玩家”[4]。
180B版本发布第二天,阿联酋人工智能部长奥马尔就入选了《时代周刊》评选的“AI领域最具影响力的100人”;与这张中东面孔一同入选的,还有“AI教父”辛顿、OpenAI的阿尔特曼,以及李彦宏。
如今,AI领域早已步入了“群魔乱舞”的阶段:但凡有点财力的国家和企业,或多或少都有打造“XX国版ChatGPT”的计划。仅在海湾国家的圈子内,已不止一个玩家——8月,沙特阿拉伯刚刚帮国内大学购买了3000多块H100,用于训练LLM。
金沙江创投朱啸虎曾在朋友圈吐槽道:“当年看不起(互联网的)商业模式创新,觉得没有壁垒:百团大战、百车大战、百播大战;没想到硬科技大模型创业,依然是百模大战……”
说好的高难度硬科技,怎么就搞成一国一模亩产十万斤了?
Transformer吞噬世界
美国的初创公司、中国的科技巨擘、中东的石油大亨能够逐梦大模型,都得感谢那篇著名的论文:《Attention Is All You Need》。
2017年,8位谷歌的计算机科学家在这篇论文中,向全世界公开了Transformer算法。这篇论文目前是人工智能历史上被引数量第三高的论文,Transformer的出现则扣动了此轮人工智能热潮的扳机。
无论当前的大模型是什么国籍,包括轰动世界的GPT系列,都是站在了Transformer的肩膀上。
在此之前,“教机器读书”曾是个公认的学术难题。不同于图像识别,人类在阅读文字时,不仅会关注当前看到的词句,更会结合上下文来理解。
比如“Transformer”一词其实可翻译成“变形金刚”,但本文读者肯定不会这么理解,因为大家都知道这不是一篇讲好莱坞电影的文章。
但早年神经网络的输入都彼此独立,并不具备理解一大段文字、甚至整篇文章的能力,所以才会出现把“开水间”翻译成“open water room”这种问题。
直到2014年,在谷歌工作、后来跳槽去了OpenAI的计算机科学家伊利亚(Ilya Sutskever)率先出了成果。他使用循环神经网络(RNN)来处理自然语言,使谷歌翻译的性能迅速与竞品拉开了差距。
RNN提出了“循环设计”,让每个神经元既接受当前时刻输入信息,也接受上一时刻的输入信息,进而使神经网络具备了“结合上下文”的能力。
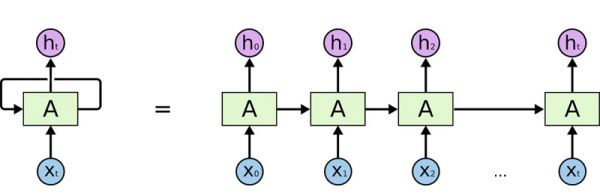
循环神经网络
RNN的出现点燃了学术圈的研究热情,日后Transformer的论文作者沙泽尔(Noam Shazeer)也一度沉迷其中。然而开发者们很快意识到,RNN存在一个严重缺陷:
该算法使用了顺序计算,它固然能解决上下文的问题,但运行效率并不高,很难处理大量的参数。
RNN的繁琐设计,很快让沙泽尔感到厌烦。因此从2015年开始,沙泽尔和7位同好便着手开发RNN的替代品,其成果便是Transformer[8]。
相比于RNN,Transformer的变革有两点:
一是用位置编码的方式取代了RNN的循环设计,从而实现了并行计算——这一改变大大提升了Transformer的训练效率,从而变得能够处理大数据,将AI推向了大模型时代;二是进一步加强了上下文的能力。
随着Transformer一口气解决了众多缺陷,它渐渐发展成了NLP(自然语言处理)的唯一解,颇有种“天不生Transformer,NLP万古如长夜”的既视感。连伊利亚都抛弃了亲手捧上神坛的RNN,转投Transformer。
换句话说,Transformer是如今所有大模型的祖师爷,因为他让大模型从一个理论研究问题,变成了一个纯粹的工程问题。
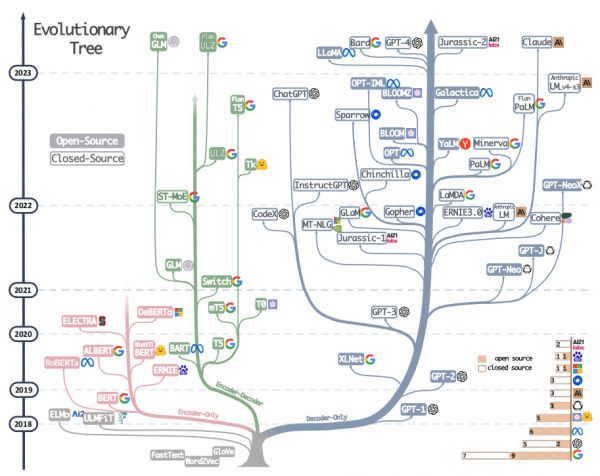
LLM技术发展树状图,灰色的树根就是Transformer[9]
2019年,OpenAI基于Transformer开发出了GPT-2,一度惊艳了学术圈。作为回应,谷歌迅速推出了一个性能更强的AI,名叫Meena。
和GPT-2相比,Meena没有底层算法上的革新,仅仅是比GPT-2多了8.5倍的训练参数、14倍的算力。Transformer论文作者沙泽尔对“暴力堆砌”大受震撼,当场写了篇“Meena吞噬世界”的备忘录。
Transformer的问世,让学术界的底层算法创新速度大大放缓。数据工程、算力规模、模型架构等工程要素,日渐成为AI竞赛的重要胜负手,只要有点技术能力的科技公司,都能手搓一个大模型出来。
因此,计算机科学家吴恩达在斯坦福大学做演讲时,便提到一个观点:“AI是一系列工具的集合,包括监督学习、无监督学习、强化学习以及现在的生成式人工智能。所有这些都是通用技术,与电力和互联网等其他通用技术类似。[10]”
OpenAI固然仍是LLM的风向标,但半导体分析机构Semi Analysis认为,GPT-4的竞争力源自工程解决方案——如果开源,任何竞争对手都能迅速复现。
该分析师预计,或许用不了太久,其他大型科技公司也能打造出同等于GPT-4性能的大模型[11]。
建在玻璃上的护城河
当下,“百模大战”已不再是一种修辞手法,而是客观现实。
相关报告显示,截止至今年7月,国内大模型数量已达130个,高于美国的114个,成功实现弯道超车,各种神话传说已经快不够国内科技公司取名的了[12]。
而在中美之外,一众较为富裕的国家也初步实现了“一国一模”:除了日本与阿联酋,还有印度政府主导的大模型Bhashini、韩国互联网公司Naver打造的HyperClova X等等。
眼前这阵仗,仿佛回到了那个漫天泡沫、“钞能力”对轰的互联网拓荒时代。
正如前文所说,Transformer让大模型变成了纯粹的工程问题,只要有人有钱有显卡,剩下的就丢给参数。但入场券虽不难搞,也并不意味着人人都有机会成为AI时代的BAT。
开头提到的“动物战争”就是个典型案例:Falcon虽然在排名上力压美洲驼,但很难说对Meta造成了多少冲击。
众所周知,企业开源自身的科研成果,既是为了与社会大众分享科技的福祉,同样也希望能调动起人民群众的智慧。随着各个大学教授、研究机构、中小企业不断深入使用、改进Llama,Meta可以将这些成果应用于自己的产品之中。
对开源大模型而言,活跃的开发者社群才是其核心竞争力。
而早在2015年组建AI实验室时,Meta已定下了开源的主基调;扎克伯格又是靠社交媒体生意发的家,更是深谙于“搞好群众关系”这件事。
譬如在10月,Meta就专程搞了个“AI版创作者激励”活动:使用Llama 2来解决教育、环境等社会问题的开发者,将有机会获得50万美金的资助。
时至今日,Meta的Llama系列俨然已是开源LLM的风向标。
截至10月初,Hugging face的开源LLM排行榜Top 10中,共有8个都是基于Llama 2所打造的,均使用了它的开源协议。仅在Hugging face上,使用了Llama 2开源协议的LLM已经超过了1500个[13]。
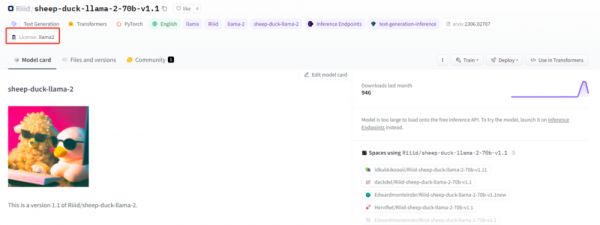
截止至10月初,Hugging face上排名第一的LLM,基于Llama 2打造
当然,像Falcon一样提高性能也未尝不可,但时至今日,市面上大多数LLM仍和GPT-4有着肉眼可见的性能差距。
例如前些日子,GPT-4就以4.41分的成绩问鼎AgentBench测试头名。AgentBench标准由清华大学与俄亥俄州立大学、加州大学伯克利分校共同推出,用于评估LLM在多维度开放式生成环境中的推理能力和决策能力,测试内容包括了操作系统、数据库、知识图谱、卡牌对战等8个不同环境的任务。
测试结果显示,第二名的Claude仅有2.77分,差距仍较为明显。至于那些声势浩大的开源LLM,其测试成绩多在1分上下徘徊,还不到GPT-4的1/4[14]。
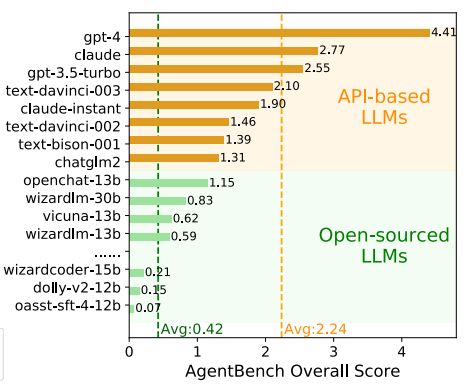
AgentBench测试结果
要知道,GPT-4发布于今年3月,这还是全球同行追赶了大半年之后的成绩。而造成这种差距的,是OpenAI“智商密度”极高的科学家团队与长期研究LLM积累下来的经验,因此可以始终遥遥领先。
也就是说,大模型的核心能力并不是参数,而是生态的建设(开源)或纯粹的推理能力(闭源)。
随着开源社区日渐活跃,各个LLM的性能可能会趋同,因为大家都在使用相似的模型架构与相似的数据集。
另一个更直观的难题是:除了Midjourney,好像还没有哪个大模型能赚到钱。
价值的锚点
今年8月,一篇题为“OpenAI可能会于2024年底破产”的奇文引起了不少关注[16]。文章主旨几乎能用一句话概括:OpenAI的烧钱速度太快了。
文中提到,自从开发ChatGPT之后,OpenAI的亏损正迅速扩大,仅2022年就亏了约5.4亿美元,只能等着微软投资人买单。
文章标题虽耸人听闻,却也讲出了一众大模型提供商的现状:成本与收入严重失衡。
过于高昂的成本,导致目前依靠人工智能赚了大钱的只有英伟达,顶多再加个博通。
据咨询公司Omdia预估,英伟达在今年二季度卖出了超30万块H100。这是一款AI芯片,训练AI的效率奇高无比,全世界的科技公司、科研机构都在抢购。如果将卖出的这30万块H100叠在一起,其重量相当于4.5架波音747飞机[18]。
英伟达的业绩也顺势起飞,同比营收暴涨854%,一度惊掉了华尔街的下巴。顺带一提,目前H100在二手市场的价格已被炒到4万~5万美金,但其物料成本仅有约3000美金出头。
高昂的算力成本已经在某种程度上成为了行业发展的阻力。红杉资本曾做过一笔测算:全球的科技公司每年预计将花费2000亿美金,用于大模型基础设施建设;相比之下,大模型每年最多只能产生750亿美金的收入,中间存在着至少1250亿美金的缺口[17]。
另外,除了Midjourney等少数个例,大部分软件公司在付出了巨大的成本后,还没想清楚怎么赚钱。尤其是行业的两位带头大哥——微软和Adobe都走得有些踉跄。
微软和OpenAI曾合作开发了一个AI代码生成工具GitHub Copilot,虽然每个月要收10美元月费,但由于设施成本,微软反而要倒亏20美元,重度用户甚至能让微软每月倒贴80美元。依此推测,定价30美元的Microsoft 365 Copilot,搞不好亏的更多。
无独有偶,刚刚发布了Firefly AI工具的Adobe,也迅速上线了一个配套的积分系统,防止用户重度使用造成公司亏损。一旦有用户使用了超过每月分配的积分,Adobe就会给服务减速。
要知道微软和Adobe已经是业务场景清晰,拥有大量现成付费用户的软件巨头。而大部分参数堆上天的大模型,最大的应用场景还是聊天。
不可否认的是,如果没有OpenAI和ChatGPT的横空出世,这场AI革命或许压根不会发生;但在当下,训练大模型所带来的价值恐怕得打一个问号。
而且,随着同质化竞争加剧,以及市面上的开源模型越来越多,留给单纯的大模型供应商的空间或许会更少。
iPhone 4的火爆不是因为45nm制程的A4处理器,而是它可以玩植物大战僵尸和愤怒的小鸟。
参考资料
[1] LLM Leaderboard Gone Wrong,Analytics India Mag
[2] NEC独自の大規模言語モデル(LLM)開発の裏側に迫る
[3] Spread Your Wings: Falcon 180B is here
[4] Abu Dhabi throws a surprise challenger into the AI race,The Economist
[5] TIME 100/AI
[6] OpenAI背后的领袖Ilya Sutskever:一个计算机视觉、机器翻译、游戏和机器人的变革者,机器之心
[7] 深度学习算法发展:从多样到统一,国金证券
[8] Your AI Friends Have Awoken, With Noam Shazeer,No Priors
[9] Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond,Jingfeng Yang、Hongye Jin等
[10] Andrew Ng: Opportunities in AI - 2023,Stanford Online
[11] GPT-4 Architecture, Infrastructure, Training Dataset, Costs, Vision, MoE,Semi Analysis
[12] IT 2023,赛迪顾问
[13] Open LLM Leaderboard,Hugging face
[14] AgentBench: Evaluating LLMs as Agents,Xiao Liu, Hao Yu等
[15] Who Owns the Generative AI Platform,a16z
[16] OpenAI Might Go Bankrupt by the End of 2024,Analytics India Mag
[17] AI’s $200B Question,Sequoia
[18] Nvidia Sold 900 Tons of H100 GPUs Last Quarter, Says Analyst Firm,tomshardware
[19] Character.ai's Noam Shazeer: "Replacing Google - and your mom",Danny In The Valley
本文来自微信公众号:远川科技评论 (ID:kechuangych),作者:陈彬,编辑:李墨天
相关推荐
大模型是不是有点太多了?
大模型+机器人,发展到什么阶段了?
大模型太烧钱,快把OpenAI烧没了
陆奇的大模型世界观
企业怎么才能用上大语言模型?
对话出门问问李志飞:AI大模型创业,CEO千万别自己忽悠自己
为什么说创业者做AI大模型完全是浪费钱?
为什么说大模型是“缸中之脑”?
国常会出利好,华为爆大消息,小米也要搞大模型!
万字长文:大模型训练避坑指南
网址: 大模型是不是有点太多了? http://www.xishuta.com/newsview94453.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95263
- 2人类唯一的出路:变成人工智能 21515
- 3报告:抖音海外版下载量突破1 21493
- 4移动办公如何高效?谷歌研究了 20661
- 5人类唯一的出路: 变成人工智 20652
- 62023年起,银行存取款迎来 10369
- 7五一来了,大数据杀熟又想来, 8890
- 8网传比亚迪一员工泄露华为机密 8561
- 9滴滴出行被投诉价格操纵,网约 8513
- 10顶风作案?金山WPS被指套娃 7255



