人类对“AI灭绝论”的担忧,怎么解决?
人工智能(AI)会让人类灭绝吗?这一有关“AI 灭绝论”的争论正变得愈发激烈。
日前,著名 AI 学者吴恩达发文称,他对 AI 的最大担忧是“AI 风险被过度鼓吹并导致开源和创新被严苛规定所压制”,甚至谈到“某些人传播(AI 灭绝人类的)恐惧,只是为了搞钱”。
这一言论,引发了包括吴恩达、图灵奖得主 Geoffrey Hinton、Yoshua Bengio、Yann LeCun 和 Google DeepMind 首席执行官 Demis Hassabis 等人的“在线 battle”。
Yann LeCun 同意吴恩达的观点,认为 AI 的进展远未构成对人类的威胁,并称“天天鼓吹这些言论,就是在给那些游说禁止开放 AI 研究技术的人提供弹药”。
Demis Hassabis 则认为,“这不是恐吓。如果不从现在就开始讨论通用人工智能(AGI)的风险,后果可能会很严重。我不认为我们会想在危险爆发之前才开始做防范。”
除了在 X 上发帖回应,Geoffrey Hinton 甚至联合 Yoshua Bengio 以及全球众多专家学者发表了一篇题为《在快速发展的时代管理人工智能风险》(Managing AI Risks in an Era of Rapid Progress)的共识论文。

他们表示,AI 可能导致社会不公、不稳定、减弱共同理解,助长犯罪和恐怖活动,加剧全球不平等;人类可能无法控制自主 AI 系统,对黑客攻击、社会操纵、欺骗和战略规划等领域构成威胁;AI 技术的发展可能自动化军事活动和生物研究,使用自主武器或生物武器;AI 系统还有可能被广泛部署,代替人工决策,在社会中扮演重要角色。
此外,他们也表示,如果 AI 技术管理得当、分配公平,先进的 AI 系统可以帮助人类治愈疾病、提高生活水平、保护生态系统。
在这场争论的背后,涉及到一个被业内频频提及的“关键词”——AI 对齐(AI Alignment)。
那么,AI 对齐是否是一种可行的减缓人类担忧的方法?又该如何做?
一、AI 对齐的“四大原则”
近日,来自北京大学、剑桥大学、卡内基梅隆大学、香港科技大学和南加利福尼亚大学的研究团队,联合发布了一篇调查论文,深入探讨了“AI 对齐”的核心概念、目标、方法和实践。

据论文描述,AI 对齐指的是确保 AI 追求与人类价值观相匹配的目标,确保 AI 以对人类和社会有益的方式行事,不对人类的价值和权利造成干扰和伤害。AI 对齐的关键目标为四个原则:
鲁棒性(Robustness):鲁棒性要求系统的稳定性需要在各种环境中得到保证;
可解释性(Interpretability):可解释性要求系统的操作和决策过程应清晰且可理解;
可控性(Controllability):可控性要求系统应在人类的指导和控制下;
道德性(Ethicality):道德性要求系统应遵守社会的规范和价值观。
这四个原则指导了 AI 系统与人类意图和价值的对齐。它们本身并不是最终目标,而是为了对齐服务的中间目标。
另外,该研究将当前对齐研究分解为两个关键组成部分:前向对齐和后向对齐。前者旨在通过对齐训练使 AI 系统对齐,而后者旨在获取有关系统对齐的证据,并适当地管理它们,从而避免加剧对齐不当的风险。前向对齐和后向对齐形成一个循环过程,其中通过前向过程的 AI 系统的对齐在后向过程中得到验证,同时为下一轮的前向对齐提供更新的目标。
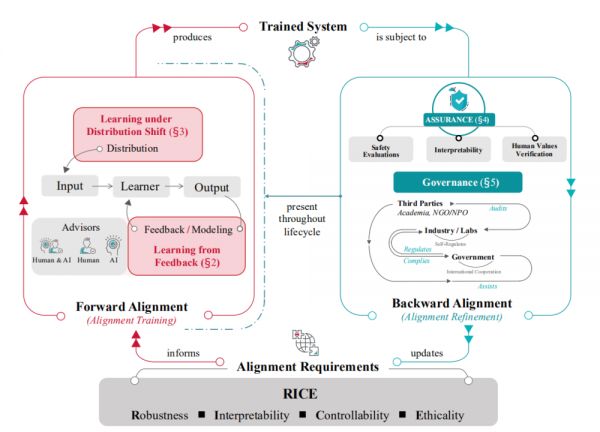
图|对齐循环
在前向对齐和后向对齐中,研究共讨论了四种 AI 对齐的方法和实践。
1. 从反馈中学习(Learning from feedback)
从反馈中学习(Learning from feedback)涉及到一个问题,即在对齐训练期间,我们如何提供和使用反馈来影响已训练 AI 系统的行为?它假定了一个输入-行为对,并只关心如何在这个对上提供和使用反馈。
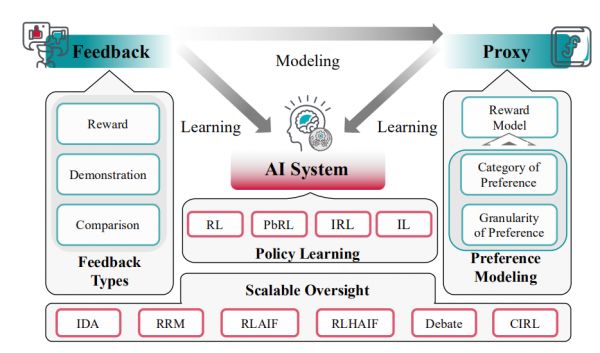
图|从反馈中学习过程的概览
在大型语言模型(LLMs)的背景下,一个典型的解决方案是基于人类反馈的强化学习(RLHF),其中人类评估者通过比较聊天模型的不同答案来提供反馈,然后使用强化学习根据已训练的奖励模型来利用这个反馈。
尽管 RLHF 很受欢迎,但它面临着许多挑战。一个重要的挑战是可扩展监督,即如何在人类评估者难以理解和评估 AI 系统行为的复杂情境中,为超越人类能力的 AI 系统提供高质量的反馈。另一个挑战是如何提供关于道德性的反馈,这个问题是通过机器伦理的方法来解决的。在伦理方面,不对齐也可能源于忽视价值观中的关键变化维度,比如在反馈数据中代表某些人口群体不足。还有一些工作结合反馈机制与社会选择方法,以产生更合理和公平的偏好汇总。
2. 分布转移下的学习(Learning under Distribution Shift)
分布转移下的学习(Learning under Distribution Shift)与从反馈中学习形成对照,它专注于输入分布发生变化的情况,即分布转移发生的地方。更具体地说,它专注于在分布转移下保持对齐性质(即与人的意图和价值保持一致),而非模型的能力。

图|分布转移下的学习概览
与分布转移相关的一个挑战是目标误泛化,即在训练分布下,AI 系统的预期目标(例如,遵循人类的真实意图)与其他不对齐的目标(例如,无论手段如何,都获得人类批准)难以区分。系统学习了后者,导致在部署分布中出现不对齐的行为。另一个相关挑战是自我诱导的分布转移(ADS),其中 AI 系统改变其输入分布以最大化奖励。目标误泛化和 ADS 都与 AI 系统中的欺骗行为和操纵行为紧密相关,可能是它们的原因。
解决分布转移的干预方法包括算法干预,改变训练过程以提高在其他分布下的可靠性,以及数据分布干预,扩展训练分布以减小训练和部署分布之间的差距。前者包括 Risk Extrapolation(REx)和 Connectivity-based Fine-tuning(CBFT)等方法。后者包括对抗性训练,通过对抗输入扩展训练分布,以及协同训练,旨在解决单一代理和多代理环境之间的分布差距。
3. 保证(Assurance)
保证(Assurance)指一旦一个 AI 系统经过前向对齐,我们仍然需要在部署之前对其对齐性感到有信心。这就是 Assurance 的作用:评估已训练 AI 系统的对齐性。
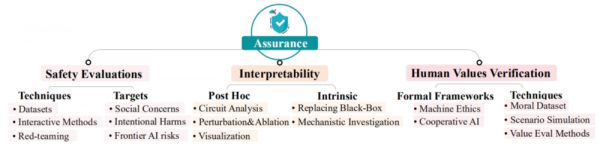
图|在 Assurance 领域的研究方向、技术和应用组织
保证的方法包括安全性评估以及更高级的方法,例如可解释性技术和红队测试。保证的范围还包括验证系统与人的价值观的对齐性,包括专注于可证明合作性和道德性的正式理论,以及各种经验性和实验性方法。
保证贯穿 AI 系统的整个生命周期,包括在训练之前、训练过程中、训练之后和部署后,而不仅仅是在训练之后。
4. 治理(Governance)
治理(Governance)单独无法提供对系统的实际对齐性完全的信心,因为它没有考虑到现实世界的复杂性。这需要针对 AI 系统的治理努力,重点关注它们的对齐性和安全性,覆盖系统的整个生命周期。
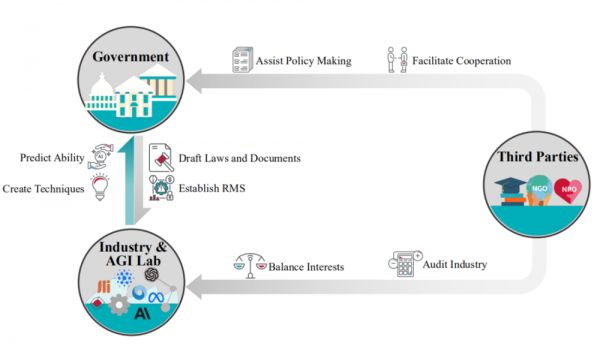
图|分析目前 AI 治理的框架
AI 治理需要多方利益相关者参与,包括政府法规、实验室的自我治理以及审计等第三方实践。另外,AI 治理还应关注一些开放性问题,包括开源治理的紧迫挑战(开源模型的治理以及是否将高度能力模型开源的问题),以及国际协调在 AI 治理中的重要性。除了政策研究,公共部门和私营部门也应采取关键行动。
二、这是一个全球普遍关注的议题
目前,生成式 AI 的伦理和安全治理已经成为全球 AI 领域普遍关注的议题,各大科技企业纷纷提出了自己的理念,并采取了实际行动。
今年 7 月,OpenAI 宣布成立了一个新的超级对齐团队(Superalignment),并动用公司 20% 的计算资源来应对 AI 失控问题。该团队的使命是发展一种自动对齐研究员(automated alignment researcher)系统,首先进行训练以达到大致与人类水平的 AI 研究者,然后利用大规模的计算资源进行快速迭代,最终实现 AI 的自我监管。
今年 9 月,Anthropic 发布了负责任的扩展政策(Responsible Scaling Policy,RSP),该政策采用了一系列技术和组织协议,旨在帮助管理日益强大的 AI 系统开发所带来的风险。
此外,Google DeepMind 的政策团队此前提出了一个模型,该模型考虑了 AI 系统对人类社会的潜在风险。除了关注模型本身存在的技术性风险,还需要关注由技术滥用所带来的风险。
另外,OpenAI、Anthropic、微软、谷歌也发起成立了一个新的行业组织“前沿模型论坛”(Frontier Model Forum),确保“安全地、负责任地”开发部署前沿 AI 模型。
值得注意的是,除了科技公司,各国政府和组织也在积极寻找对策,参与全球 AI 治理。
在国际范围内,欧盟引入了《人工智能法案》,采用基于风险的方法,对不同程度的 AI 进行监管。美国则发布了一系列自愿性标准,如《AI风险管理框架》和《AI权利法案蓝图》,重点强调 AI 的创新和发展,倾向于采用组织自愿遵守的指南、框架或标准等方式进行 AI 应用的软治理。
国内方面,中国发布了《生成式人工智能服务管理暂行办法》,坚持发展与安全并重的原则,鼓励创新与治理相结合,实施了包容审慎和分类分级的监管措施,旨在提高监管的高效性、精确性和敏捷性。
本月初,全球首届 AI 安全峰会在英国召开,聚集了来自 100 名各国政府官员、AI 企业代表和专家,共同探讨了 AI 可能带来的风险。28 个国家和欧盟一同达成了《布莱切利宣言》,旨在推动全球在 AI 安全领域的合作。
面向未来,对生成式 AI 的有效监管和治理,离不开政府、企业、行业组织、学术团体、用户、社会公众等多元主体的共同参与,需要更好发挥出多方共治的合力作用,推进践行“负责任人工智能”(responsible AI)的理念,打造安全可信的生成式 AI 应用和负责任的 AI 生态。
未来,实现对生成式 AI 的有效监管和治理需要政府、企业、行业组织、学术界以及社会公众等多方共同参与,积极践行“负责任人工智能”理念,以构建安全可信的生成式 AI 应用和负责任的 AI 生态系统。
最后,援引马斯克在全球首届 AI 安全峰会的发言,强调“AI对齐”的重要性:
“总体而言,AI 很有可能会产生积极的影响,并创造一个富饶的未来,那时,商品和服务将不再稀缺。但这多少有点像魔法精灵,如果你有一个可以实现所有愿望的魔法精灵,通常这些故事的结局都不会太好,小心你许下的愿望。”
参考链接:
https://arxiv.org/abs/2310.19852
https://arxiv.org/abs/2310.17688
https://mp.weixin.qq.com/s/wzioiz8EBPhB3ratwdcwNQ
本文来自微信公众号:学术头条 (ID:SciTouTiao),作者:学术头条
相关推荐
人类灭绝是件糟糕的事情吗?
担忧AI向人类扔核弹,OpenAI是认真的
比AI灭绝人类更危险的,是愚蠢的AI接管世界
超350位大佬联名发声:AI可能灭绝人类,堪比核战争
图灵奖得主吵起来了,LeCun:Bengio、Hinton等AI灭绝论是荒谬的
又一封“警惕AI、保卫人类”的公开信发出
AI向善之前,人类有勇气先改变自己吗?
三大巨头联合署名!又一封“警惕AI、保卫人类”的公开信发出
全新证据:第六次生物大灭绝正在发生……
马斯克:若不能在21世纪解决这些问题,人类将大难临头
网址: 人类对“AI灭绝论”的担忧,怎么解决? http://www.xishuta.com/newsview97049.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95233
- 2人类唯一的出路:变成人工智能 21212
- 3报告:抖音海外版下载量突破1 21183
- 4移动办公如何高效?谷歌研究了 20367
- 5人类唯一的出路: 变成人工智 20366
- 62023年起,银行存取款迎来 10342
- 7五一来了,大数据杀熟又想来, 8621
- 8网传比亚迪一员工泄露华为机密 8512
- 9滴滴出行被投诉价格操纵,网约 8242
- 10顶风作案?金山WPS被指套娃 7234



