大模型时代,孩子还需要读经典吗?
最近,在娃有空时,教他C++编程,好些我也忘了,都是问文心一言。前两天教一个编程题,求几个数中最小数,书上有两三种解法,让娃问问百度,给出一段代码.简单看了眼,惊讶于大模型给出的代码简洁而实用,只有C++经验丰富的老手才能写出那样语法,还契合了问题,没有书上的通用,却简明干净。强行和娃解释了下心中获得的美好,看着他茫然的眼睛,悻悻然。
消息称 OpenAI 正在筹建 OpenAI 学院,预计 2023 年底启动。一个是人人可访问的免费在线教学系统,老师、学生能更方便地利用ChatGPT5进行课程学习。以后人人都有一个全科老师,还真是幸事,特别对那些跨学课问题:
学生:百度,百度,给我一段代码找个合适算法处理下我的生物学实验数据吧
文心一言:刷的一段(以后大模型必然和运行环境整合一块,自动调试)
学生:这个算法只是拟合了下,找个有物理原理支持的模型再跑跑
文心一言:刷的一下又一段,还带模型解释
学生看不懂模型解释,又问道....
感慨之余,心中不仅也产生一个疑问:以后都是要和大模型一块学习,是面向问题学习。那些人类经典书籍,不涉及任何实际问题,可能只能给出些启发的书籍,包括讨论哲学、抽象方法论、感想的书籍还需要读吗?笔者是偏好看看那些书籍,特别是有些领域大牛写的,往往他们本身具备良好的人文、哲学素养,当人类长久的思考结合到具体领域,读起来更让人愉悦。
人学习需要书籍、资料,大模型也是如此,讨论这个问题之前,我们先来看看大语言模型学习用了哪些数据。
一、大语言模型的训练数据
大语言模型的训练数据大致分为两类:
1. 预训练数据
大量文本,用于进行无监督预训练,学习通用表征. AI研究机构Allen Institute for AI发布了一个名为Dolma的开源语料库,含了来自网络内容、学术出版物、代码、书籍和维基百科材料的3万亿token。 包括Wikipedia、CommonCrawl等开源的语料库,以及社交媒体数据、对话数据集。
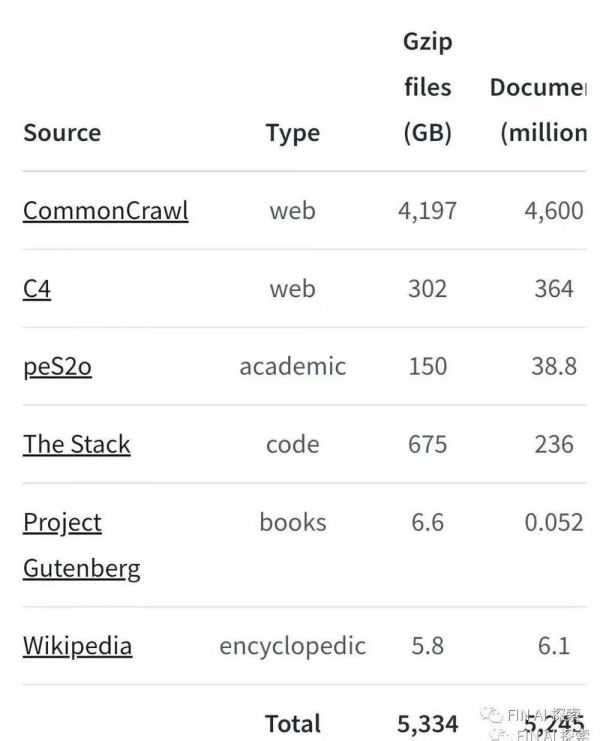
大体上可以认为人类一切干净文本都可以用于训练。对于特定领域,如法律:相关书籍、论文、法规、案件、庭审等等;金融领域:相关书籍、论文、研报、公告、财报、新闻等等;其他学科也是如此。大抵可以认为,对于预训练:专业、干净的领域相关文本数据,越多越好。
2. 有监督微调数据
有监督微调数据,以适应任务和用户偏好。有监督微调(Supervised fine-tuning)数据准备也是通常我们应用大模型主要的工作。强化学习训练的数据通常也和指令微调数据类似,而且通常应用阶段也不需要进行,也归于这类。
典型的如Alpaca-52k(alpaca_data.json)数据集。Alpaca-52k是一个开源数据集,用来微调LLaMA模型以得到Alpaca-7B模型的数据集,包含了52000条指令数据。其数据格式分为两类:instruction/output和instruction/input/output。input是任务的可选上下文或输入。例如,当指令为“总结以下文章”时,输入为文章。行业、领域有监督微调数据也是如此。自然科学、社会科学还有一定标准,人文科学很可能主观偏好就放进去了。这也是为啥我国需要大模型监管,持证上岗。
3. 大模型有监督微调训练也是需要少量高质量数据就够了

Mata公司的研究人员发现,只使用1000个高质量的样本数据进行微调,在没有任何强化学习或人类偏好建模情况下。65B的LLaMA模型表现出非常优异的性能。这对我们做大模型应用的人当然是福音,在领域中不缺少高质量数据。论文认为模型的知识和能力几乎完全是在预训练期间学习的,而有监督微调(SFT)则教会它在与用户互动时应该使用哪种子分布的格式,少量高质量数据就能达到预期效果。这看起来和人类少量数据就能学习有些相似。
二、对比大语言模型,人类的学习过程
1. 经典是人类高质量数据
自然科学、社会科学领域,人类学习需要的高质量可以认为是机器的标准一致。我们重点讨论下人文科学。
陈寅恪被誉为三百年学问第一人,一人担任了清华大学历史、中文、哲学三系教授,精通二十多门外语。上课号称“前人讲过的,我不讲;近日讲过的,我不讲;外国人讲过的,我不讲;我自己过去讲过的,我不讲。”他对读书的建议是读原典,“中国真正的原籍经典(原典)也只不过一百多部,其余的书都是在这些书的基础上互为引述参照而已。” 2023年诺贝尔生理学或医学奖得主卡塔林·考里科在访谈中也说:我的爱好之一是阅读经典的科学论文。当我意识到RNA中的尿苷会引爆免疫细胞,导致炎症和干扰素的产生时,我想知道以前是否有人注意到这一点。果不其然,在1963年的一篇论文中发现,从哺乳动物细胞中分离的核糖核酸不会诱导干扰素的产生。
2. 熏陶是人类的训练过程
说到人类经典书籍,木心先生的《文学回忆录》,是给他的学生陈丹青们讲课的笔录.从古希腊、新旧约,到中国诗经、魏晋文学,再到中世纪欧洲文学,一直讲到二十世纪文学和各种流派。将他自身对文学、艺术、哲学等领域的见解和偏好都融入了讲课。可以想见,这样五年的熏陶,对他的学生们人生、艺术生涯将多么的有益。
科学、工程领域也是如此,在阅读经典、研究、解决问题过程中。被老师熏陶,学习领域方向和价值选择。
三、高质量数据学习: 人类 VS 大语言模型
通常,大部分研究领域,只有阅读领域经典,在实践中训练才能掌握解决领域问题的方法.投资这样需要智慧的领域不算。即使文学这样领域,读的多当然有价值,但也不是全部,钱钟书先生就以博学见长,号称古今中外的原典都已掌握。有“从兔毛中见乾坤”的智慧。但有时“白茫茫一片真干净”这样的简洁、直指人心的风格更打动人,这必然是小样本学习的结果。
笔者断言:因为大语言模型是大量数据训练的结果,所以永远无法成为领域具备直觉的专家。光靠它不可能有创新的发现与新观点。
当今天Chatgpt已进入科学与艺术等人类社会方方面面时,笔者却要强调大模型永远只是二流助手。
——ChatGPT写不出《罗刹海市》
1. 为什么大模型不能和人类一样只用那些经典资料、数据学习?
ChatGPT等大语言模型简化并统一的问题形式,当输入特定问题作为提示(Prompt),模型尝试匹配已提供的上下文,根据已学习的人类知识去做文本补全。ChatGPT也是人工智能生成内容模型(AIGC,AI Generated Content),需要通过序列对抗网络(SeqGAN)生产大量样本数据进而进一步优化模型。当最终模型在输入输出形式上和生成的问题保持一致,这样理解和生成任务在表现形式就实现了完全的统一,更有利于生成内容模型数据生产与优化。
这也是为什么大模型不能只用那些经典资料、数据学习的原因. 原典、经典论文太少,根本不够大模型训练,至少几十亿个参数需要拟合,必须大量数据进行训练。互为引述参照的书籍、文章,对大模型来说,同样是高质量数据,它们总比那些生成的数据更靠谱吧。
2. 挖掘高维数据价值是人类认识世界的方向之一,但不是全部
更多维的数据向量化特征表示必将有利于挖掘产生更多数据价值。既然语言可以向量化,那有什么不能向量化的。向量化也是机器学习算法发挥作用的前提条件之一,利用机器学习挖掘数据中的信息。而利用机器挖掘数据中我们所不能理解的高维信息还将进一步加速。
3. 大模型才是世界模型(World Model)的方向
最近,图灵奖获奖者,深度学习创始人之一LeCun在公开演讲中,再次批评了GPT大模型,他认为根据概率生成自回归的大模型,根本无法破除幻觉难题。甚至直接发出断言:大语言模型活不过5年。
他的愿景是,创造出一个机器,让它能够学习世界如何运作的内部模型,即世界模型,这样它就可以更快速地学习,为完成复杂任务做出计划,并且随时应对不熟悉的新情况。
LeCun作为Meta首席人工智能科学家,近期还指导发布了一个“类人”的人工智能模型 I-JEPA,号称在同样数据、同样训练资源请看下,可以比现有模型更准确地分析和完成缺失的图像。不明觉厉,但笔者有个不讲武德的个人看法:比效果,为啥要在同样数据、同样训练资源下比?

LeCun希望设计出一种学习算法,捕捉关于世界的常识背景知识,然后将其编码为算法,这是强人工智能方案,在学术上优于ChatGPT的弱人工智能方案。用算法对世界建模显然自大了。就如投资领域,希望对各行各业产业链建模,捕捉相互之间影响一样.基于朴素的常识,飞机不必学鸟的飞行原理,笔者个人认为:大模型才是世界模型的方向。
五、结论:人不必学机器,正如机器不必学人
大语言模型所展示出的令人印象深刻的能力之一,是通过提供上下文中的示例并要求模型生成响应来跟随所提供的最终输入,从而进行小样本学习。模型的知识和能力几乎完全是在预训练期间大量样本学习,这和人类善于少量高质量数据学习本质不同。
前些日,美国食品和药物管理局批准马斯克的Neuralink公司就脑机接口项目展开人体临床试验。
人的大脑不会因为ChatGPT的发明就自动进化,除非接入脑机接口。所以,对人类的孩子来说,读经典的学习方式依然存在。
本文来自微信公众号:FIN AI 探索(ID:fin_ai_research),作者:袁峻峰
相关推荐
大模型时代,孩子还需要读经典吗?
果麦文化、读客上市,出版还是一门好生意吗?
大语言模型能拯救互联网大厂吗?
透视“樊登小读者”:怎样的读书App才能吸引孩子?
OpenAI CEO宣布转向,“大模型时代”即将结束?
周鸿祎:未来属于正确使用大模型的人
阿里进入大模型时代,核心是算力和生态
为什么我们要阅读经典?
优爱腾还需要《老友记》吗?
赴港读书的孕妇:为了孩子,硕士决定读大专
网址: 大模型时代,孩子还需要读经典吗? http://www.xishuta.com/newsview97642.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95088
- 2人类唯一的出路:变成人工智能 20304
- 3报告:抖音海外版下载量突破1 20127
- 4移动办公如何高效?谷歌研究了 19524
- 5人类唯一的出路: 变成人工智 19425
- 62023年起,银行存取款迎来 10245
- 7网传比亚迪一员工泄露华为机密 8365
- 8五一来了,大数据杀熟又想来, 7851
- 9滴滴出行被投诉价格操纵,网约 7477
- 10顶风作案?金山WPS被指套娃 7167



