英伟达H200发布,性能很强,奈何买不到
“皮衣刀客”才是最大赢家

前几天,OpenAI一场开发者大会,让整个AI人工智能行业的从业者几乎彻夜难眠。而今天,NVIDIA英伟达同样带来了一个重磅消息——几乎可以说是目前最快的AI算力芯片H200正式发布。
距离上一次英伟达发布“新品”还没过去多久,皮衣刀客的步伐可以说是又快又稳。根据官方透露的信息,H200相比于此前的旗舰H100,直接性能提升有60%到90%,参数可以说是拉满了。
算力GPU作为当下“地球上最稀缺的工程资源之一”,一度引来科技大厂们的“疯抢”。在H200发布之后,相信已经有AI公司开始订货了。
不过仔细看H200的规格就能发现,H200的升级可能并没有那么夸张,值得期待的,也许还是后来者。
只是一个“小”升级
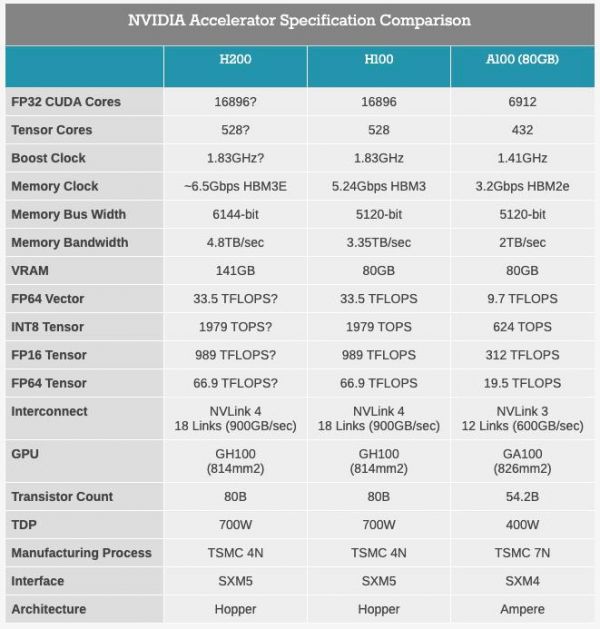
对比H200与前代H100的规格,主要负责计算能力的核心单元部分规格并没有改变,算力规模完全一致,所带来的提升只是显存容量从80GB提高到了141GB,显存的规格从原本的HBM3升级到了HBM3e。
 (图源:anandtech)
(图源:anandtech)由于本身算力部分并没有变化,因此换用H200并不会对AI大模型的训练速度产生更好的影响,以训练175B大小的GPT-3举例,同规模的H200大概只比H100快10%左右。
而它主要的提升之处在于“推理”。
一般而言,推理对于算力的需求并不高,限制反而在于单芯片的显存大小以及显存带宽,如果应用到多GPU的互联,那么信息通信的带宽反而会不够。即便如NV Link提供的900GB/s的数据通信速度,也无法媲美单卡内部超过3TB/s的速度,更不用说换了HBM3e显存后高达4.8TB/s的性能了。
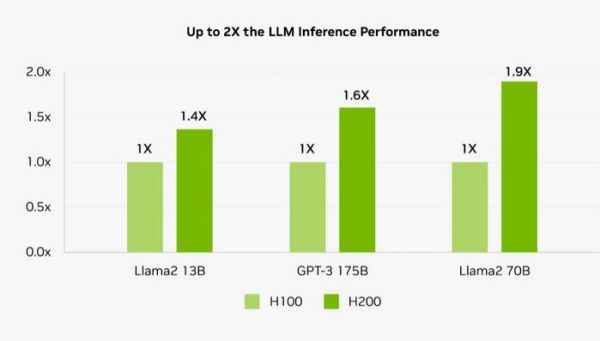 (图源:NVIDIA)
(图源:NVIDIA)同样,更大的单卡显存容量也能有效减少跨卡访问的次数,算是一种变相的效率提升。
随着当前AI大语言模型逐步迈向应用化,计算任务的重心已经由早期的训练模型转变为应用端的推理行为。
此前OpenAI就曾苦于AI太过火爆,挤占了大量的推理资源,国内比如此前曾红极一时的“妙鸭相机”也因为用户太多,没有足够的推理资源而需要等待很长时间才能出片。
而H200对比H100的推理能耗直接减半,极大降低了使用成本,真应了那句话——「买的越多,省的越多」
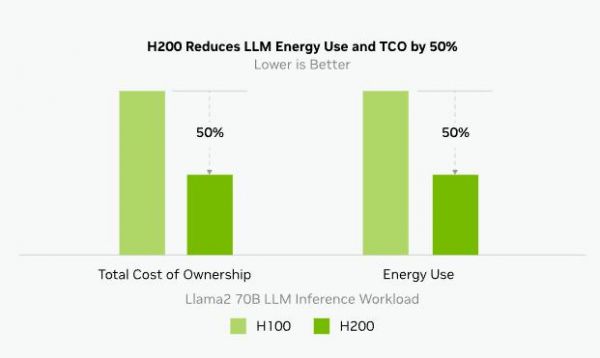 (图源:NVIDIA)
(图源:NVIDIA)有业内人士推测,后续消费级GPU可能也会出现类似的转变,即在算力一定的情况下,通过提升显存容量和带宽以获得更好的模型推理体验,毕竟在“全民AI”的时代,客户端的性能也需要跟上。
英伟达大规模与高性能计算副总裁Ian Buck表示:要利用生成式人工智能和高性能计算应用创造智能,必须使用大型、快速的GPU显存,来高速高效地处理海量数据。借助H200,业界领先的端到端人工智能超算平台的速度会变得更快,一些世界上最重要的挑战,都可以被解决。
显存是关键
自从近两年AI爆火后就迅速带动了AI服务器的需求爆发,AI大模型的数据参数庞大,除了需要算力支撑模型训练,同样需要数据的传递和处理。
过去20年间,算力硬件的性能提升了90000倍,但是内存、存储的互联带宽只提升了30倍,二者已然有所脱节,数据传递的速度可能远低于数据处理的效率。因此,如英伟达这样的GPU厂商,就引入了HBM代替原本的GDDR内存,通过硅中介层与计算核心紧密互联,加快数据传输速度。
据SK海力士介绍,HBM3e不仅满足了用于AI的存储器速度规格,也在发热控制和客户使用便利性等所有方面有所提升。在速度方面,其最高每秒可以处理1.15TB的数据。
早在今年8月,NVIDIA就已经计划发布配备HBM3e显存的 Grace Hopper GH200 超级芯片版本。
 (图源:NVIDIA)
(图源:NVIDIA)根据anandtech的描述,H200差不多就是GH200的GPU部分,从前面也可以看到,H200的HBM3e显存的容量有些奇怪,是141GB,HBM3e的物理容量应该是144GB,这是由于产量和良率而保留了部分容量。另一方面,H200的显存频率应该是6.5Gbps,虽然比H100提升了25%,但依旧没有达到美光希望中的9.2Gbps。
所以,此次发布的H200可能依旧算不上“满血版”,只能算是加上了HBM3e显存的H100小更新,也正因此两者是互相兼容的,已经在使用H100进行模型训练的可以直接更换成H200。
需要注意的是,H200的实际出货时间是2024年第二季度,也是由于海力士的HBM3e显存需要到今年年底才能产出,最快量产得到明年初。由此可见显存其实才是整个AI发展的重中之重。
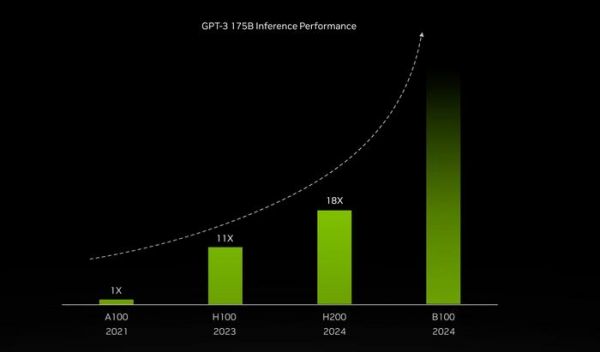 (图源:NVIDIA)
(图源:NVIDIA)不过,在发布中还提到了一些细节,比如2024年的B100,似乎在性能上又能有接近两倍的提升?推测未来的新架构可能会带来一些不同,说不定就是那个真正的“满血版”。
写在最后
当然,受制于美国的出口禁令,H200再强,也卖不到国内。
前两天有消息称,英伟达专为中国市场又开发了新的HGX H20、L20 PCle和L2 PCle GPU,几乎卡在了管制的算力极限上。
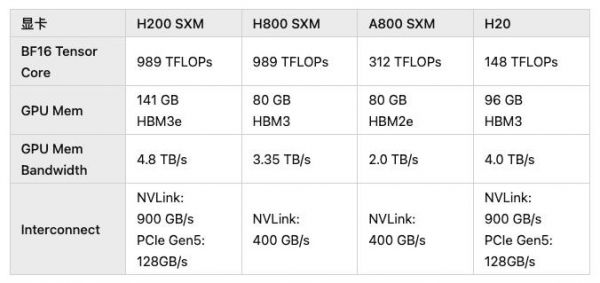 (图源:知乎)
(图源:知乎)只可惜这个规格,嗨……希望国产替代尽快到来吧。
本文作者:Visssom,观点仅代表个人,图源:NVIDIA
发布于:江苏
相关推荐
英伟达H200突然发布:容量翻倍,带宽狂飙
最前线 | 英伟达发布GPU旗舰A100,采用7nma工艺,性能提升20倍
英伟达芯片,最新路线图
英伟达3080Ti、3070Ti来了:继续封锁挖矿性能,网友:不信,空气卡+1
从产业视角看英伟达AI芯片禁售
英伟达,股价涨得其所
英伟达发布 L40S GPU:AI 推理性能较 A100 高 1.2 倍
加量还降价?英伟达发布RTX30系列显卡,性能翻倍,价格只要泰坦一半
谁卡了英伟达的脖子?
性能达英伟达2倍以上,国内首款存算一体芯片问世,采用12nm工艺
网址: 英伟达H200发布,性能很强,奈何买不到 http://www.xishuta.com/newsview97929.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95263
- 2人类唯一的出路:变成人工智能 21515
- 3报告:抖音海外版下载量突破1 21493
- 4移动办公如何高效?谷歌研究了 20661
- 5人类唯一的出路: 变成人工智 20652
- 62023年起,银行存取款迎来 10369
- 7五一来了,大数据杀熟又想来, 8890
- 8网传比亚迪一员工泄露华为机密 8561
- 9滴滴出行被投诉价格操纵,网约 8513
- 10顶风作案?金山WPS被指套娃 7255



