最强AI芯片H200?黄仁勋又在挤牙膏了
11月13日晚,英伟达在国际超算大会上推出新一代GPU,NVIDIA HGX H200。
对这块GPU,黄仁勋给的学术名称是“新一代AI计算平台”,专为大模型与生成式AI而设计,翻译一下:只看算力H200和H100基本相同,但为了加速AI推理速度,我们优化了显存和带宽。
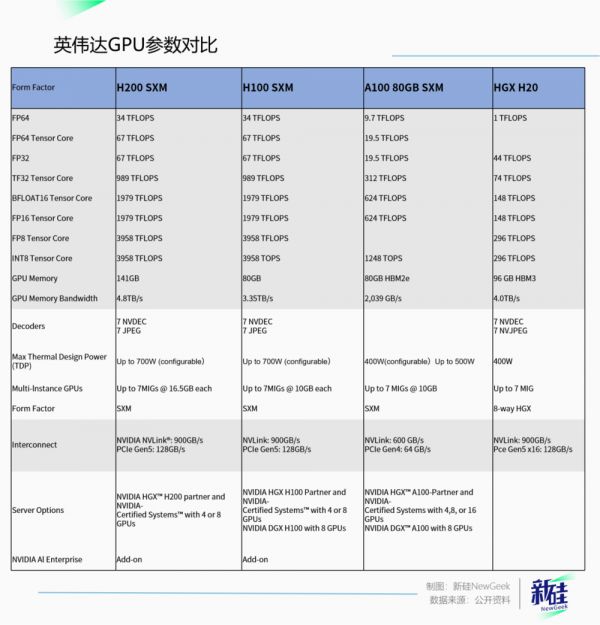
又一块史上最强芯片
先看具体的参数升级,官方新闻稿是说相比H100而言性能提升了60%-90%,具体来看则是四个方面:
1. 跑70B Llama2,推理速度比H100快90%;
2. 跑175B GPT-3,推理速度比H100快60%;
3. 显存容量达到141GB,是H100的近1.8倍;
4. 带宽达到4.8TB,是H100的1.4倍。
换句话说,虽然算力没有提升,但更高速的推理就意味着大量时间和金钱成本的节约,虽然还没有公布定价,新卡的“单美元效率”有了显著的提升。
虽然当下H200的具体架构还没有曝光,根据已有信息我们推测,最重要的三个部分中,逻辑芯片应该还是台积电的4N工艺,CoWoS封装也没有变化,但HBM存储芯片却由原先的HBM3升级到了HBM3e。

H100拆机图
原先的6颗HBM3芯片由SK海力士独供,内存带宽为3.35TB/s,内存为80GB,而全球首款搭载HBM3e内存的H200,内存带宽达到4.8TB/s,内存达到141GB。
141GB内存这个数字还挺奇怪,但这也是惯例。之前的HBM3芯片单颗内存为16GB,堆叠6颗理论上应该是96GB,但实际只有80GB,就是英伟达为了保证良率,保留了一部分冗余空间。
而这次的HBM3e单颗容量为24GB,6颗算下来是144GB,等于说这次英伟达只保留了3GB冗余,更大程度压榨了内存的空间,以实现性能上的突破。
这或许带来产能爬坡速度较慢的问题。
至于供应商方面,英伟达暂时没有公布,SK海力士和美光今年都公布了这一技术,但美光在今年9月份表示,它正在努力成为英伟达的供应商,不知道H200有没有选上它。
这块最强GPU要到2024年二季度才正式发售,现在大家依然得抢H100。
今年8月英伟达发布的GH200超级芯片,实际上是由Grace CPU与H100 GPU组合而成的。
这套组合在NVLink的加持下与H200完全兼容,也就是说原先用H100的数据中心既可以直接升级H200,也可以再堆几块H200进去增加算力。
另一方面,根据此前英伟达公布的更新路径图,在2024年的四季度就将发布下一代Blackwell架构的B100,性能将再次突破。
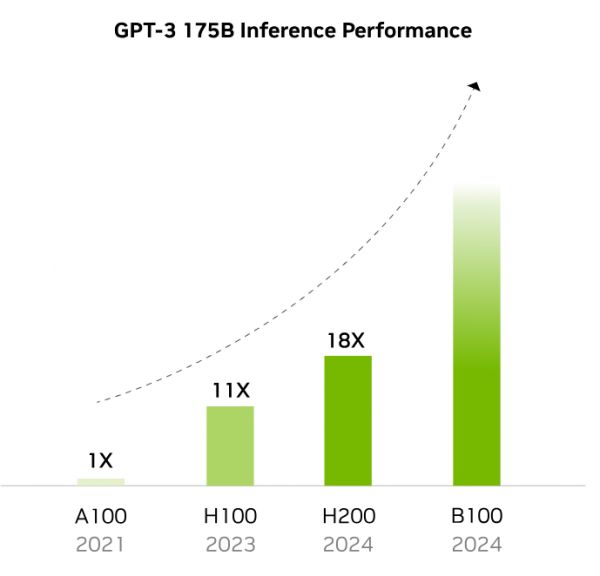
再结合我们上文提到的,相比于H100,H200只是在推理能力上有所提升,更接近老黄一贯以来的挤牙膏产品,真正的大招还得看明年的B100。
问题是,英伟达为什么要出一款这样的产品?
H200称不上传奇
显卡玩家都知道,老黄的刀法是出了名的精湛。
所谓刀工,就是你去买肉的时候说要一斤肉,老板一刀下去刚好一斤。放到显卡这里,则是厂商通过分割性能设计出不同价位的产品,以满足各类不同需求的消费者。
比如下图所示的五款同一年发售的显卡,采用相同制程和架构,但通过屏蔽不同量的流处理器以诞生性能有所差异的五款显卡。
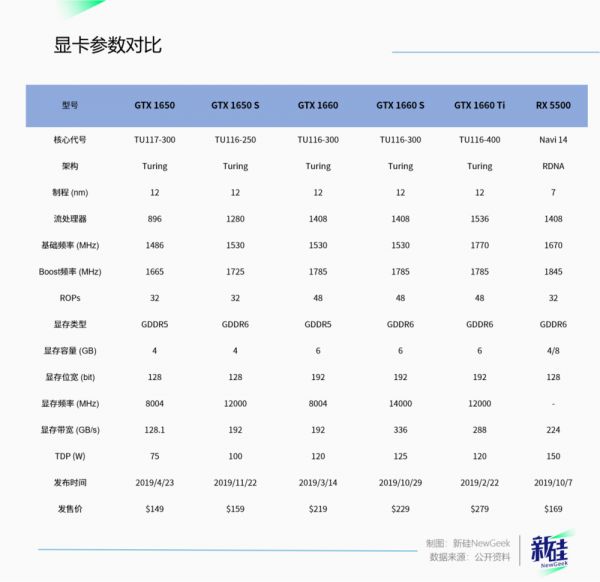
发售价基本呈等差数列,如果把他们变成性能差异的话,则会出现下面这张层层递进的得分图。
很明显,消费者多花一分钱,就能多得到一点性能,号称“每500元一档,每5%性能一级”。
毕竟打游戏这事,有人只玩热血传奇,也有人就喜欢4K光追120FPS玩《赛博朋克2077》,不同人群的需求千差万别,不同价位都有市场。
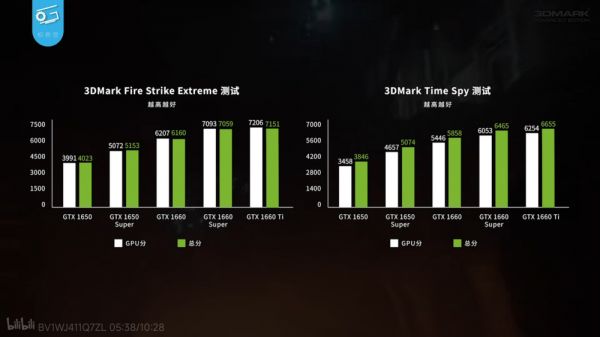
图片来源:极客湾
至于这么操作有什么好处——抢占市场,节约成本。
抢占市场比较好理解,在所有价格带和各种性能档次上铺满自家产品以挤压对手生存空间,这套做法各行各业都有,看看白酒和车企就知道了。
成本这边,一片晶圆能够切割出若干块“die”(也就是芯片封装前的晶粒),而这切割出来的die质量参差不齐,也就有了良品率的概念。
因此简单来说,以16xx系显卡为例,英伟达就会把质量最高的芯片做成性能最强的1660Ti,差一点的做成1660Super和1660,再差一点的继续降级。
这样就能够保证在芯片制造过程中的损耗尽可能降低。
同时这种刀法还能用来清库存,比如22年矿机市场崩盘,英伟达30xx系列芯片堆在仓库里卖不动,老黄就把用在高端显卡上的芯片放进低端显卡系列里,降价出售。
比如说原先放在3090上的ga102核心,22年3月首发价11999元,到了11月就搭载到新版的3070Ti V2上,价格直接打到了3500左右。
回到H200这里,H100已经是最强的AI芯片了,但英伟达就是要在B100和H100之间再切出一个H200,同样也是上述的两个原因。
这里需要科普一下内存带宽的意义,一套服务器的真实计算速度(FLOPs/s),是在“计算密度x带宽”与“峰值计算速度”这两个指标间取最小值。
而计算密度和带宽的上限都是受到内存技术影响的。(这里划个线,后面讨论中国特供H20还会提到。)
通俗来说,就是如果芯片内部计算已经结束,但新的数据没传过来,下一次计算也就不能开始,这部分算力实际上是被浪费的。
这也是为什么我们看到一些服务器的算力(FLOPs)相对较低,但计算速度却更高的原因。
因此对于一款高性能芯片来说,算力和带宽应当同步提升才能使计算速度最大化。
对于H系列GPU来说,在不改架构和所用制程的情况下,可能算力上的突破已经比较困难,但在HBM3e的加持下,内存和内存带宽得以继续提升。
另一方面,相较于此前训练大模型所强调的庞大算力,在当下AI应用大量落地的时代厂商开始重视推理速度。
推理速度和计算速度可以划上约等号,即是将用户输入的数据,通过训练好的大模型,再输出给用户有价值的信息的过程,也就是你等ChatGPT回复你的那段时间。
推理速度越快,回复速度越快,用户体验自然越好,但对于AI应用而言,不同难度等级的推理所需要的运算量天差地别。
打个比方,假设现在有一款和GPT-4同样强大的模型,但问他附近有什么好吃的足足花一分钟才能给出答案,但GPT-4只要一秒,这就是推理速度带来的差异。
这种推理速度上的差异延伸到应用生态上,则会影响应用的广度与深度,比如即时性要求更强的AI就必须拥有更高的带宽,最典型的案例就是自动驾驶技术。
在这一逻辑下,头部大厂自然会愿意为更高的内存买单。
而成本这一块,英伟达就更鸡贼了,咱们来看看中国特供版GPU:H20。
深厚刀工下的产物:H20
日前有消息称,英伟达现已开发出针对中国区的最新改良版系列芯片:HGX H20、L20 PCle和L2 PCle,知情人士称,最新三款芯片是由H100改良而来,预计会在16号正式公布。
这有三款芯片,但L20和L2是基于Intel的第三代平台,这里暂且不表,重点是采用H100/H800架构的H20。
H20的诞生背景这里就不再赘述,单看这名字,足足落后H200十倍,拜登看了直点头。
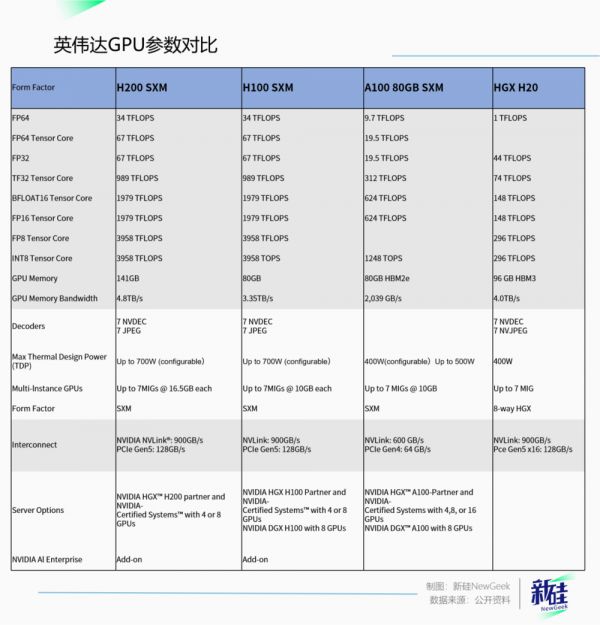
先看参数,H20在内存上用的还是H100相同的HBM3,6个16G堆叠完完整整96GB,完全没有任何留存部分,意味着该技术良率早已不是问题,明显的成熟制程。
但为了规避禁令限制,计算密度(下图中的TPP/Die size)被大幅阉割,根据上文所述,计算速度也就是推理速度差了不止一星半点。
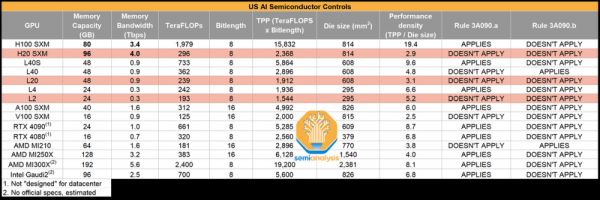
然后再看这张表,计算能力的核心参数FP32为44TFLOPS,相较于H100/200并没有下降多少。
但在张量核心(Tensor Core)的部分则是大砍特砍,BF16、TF32都被砍到只剩一个零头。
简单来说就是生成比GPT-3更高级的大模型所必备的,专为深度学习而设计的计算核心,张量核心被砍,基本意味着这块GPU当下训练不出比GPT-3更高级的模型。
张量核心被砍,同样意味着生产这卡可以用成熟制程,品相差一点的晶粒,也就意味着更低的成本。
想想这是不是和显卡玩法差不多?
看到这里感觉就是个全面阉割版,用国产替代不行吗?
老黄刀法厉害就厉害在这:4.0TB的内存带宽比H100还高,卡间、服务器间带宽NVlink速度900GB/s和H100持平。
也就是说,即便禁令影响不能出售高端GPU,但中国客户可以多买几张堆一起,用来弥补单卡算力不足的问题,粗略算算2.5张H20可以等效于一张A100。
NVlink再加上CUDA生态,再算上成熟制程带来的低成本优势,即便国内厂商不得不给英伟达缴更多的“税”,H20依旧是国内厂商最好的选择。
还是那句话,老黄这么多年积淀下的刀功确实能给蚊子腿做手术,这一刀下来,既规避了禁令限制,又让国内厂商继续买他们家的产品。
英伟达又赢麻了。
参考材料:
[1] 英伟达计划碾压竞争对手 – B100、“X100”、H200、224G SerDes、OCS、CPO、PCIe 7.0、HBM3E,semianalysis
[2] Nvidia upgrades flagship chip to handle bigger AI systems,reuters
[3] 深度学习模型大小与模型推理速度的探讨,知乎
本文来自微信公众号:新硅NewGeek(ID:gh_b2beba60958f),作者:张泽一,编辑:戴老板,视觉设计:疏睿
相关推荐
黄仁勋,挖来Meta一员AI芯片大将
黄仁勋终究难成乔布斯
英伟达CEO黄仁勋获芯片行业最高荣誉:他颠覆了计算
年薪4亿,她要和黄仁勋“掰手腕”
“硅谷狠人”黄仁勋的三个困境
马斯克访华,黄仁勋也不远了
突破封锁的黄仁勋,要来了
黄仁勋要造「第二颗地球」了
黄仁勋带领英伟达争当半导体盟主
英伟达CEO黄仁勋,“制造人工智能的iPhone时刻”
网址: 最强AI芯片H200?黄仁勋又在挤牙膏了 http://www.xishuta.com/newsview98067.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95178
- 2人类唯一的出路:变成人工智能 20885
- 3报告:抖音海外版下载量突破1 20771
- 4移动办公如何高效?谷歌研究了 20054
- 5人类唯一的出路: 变成人工智 20036
- 62023年起,银行存取款迎来 10307
- 7网传比亚迪一员工泄露华为机密 8456
- 8五一来了,大数据杀熟又想来, 8338
- 9滴滴出行被投诉价格操纵,网约 7960
- 10顶风作案?金山WPS被指套娃 7213



