零一万物发文回应质疑:对疏忽表示歉意,尽快完成版本更新

近日,开发者群体正热议一款基于开源模型更换张量(Tensor)名字的话题。
具体来看,在Yi-34B 的Hugging Face开源主页上,开发者ehartford质疑李开复带队创办的AI2.0公司零一万物近期发布的Yi-34B 模型使用了Meta LLaMA的架构,只对两个张量(Tensor)名称进行了修改。ehartford表示,开源社区肯定会重新发布 Yi 大模型,并重命名张量以符合 LLaMA 架构。
据悉,Yi-34B是零一万物在11月6日正式发布的首款开源预训练大模型,其Yi系列模型,包含34B和6B两个版本。其中开源的Yi-34B模型将发布全球最长、可支持200K 超长上下文窗口(context window)版本,可以处理约40万汉字超长文本输入。
针对此事,“零一万物”公司昨日正式公开进行回应,该公司开源团队总监 Richard Lin 承认了修改Llama张量名称的做法不妥,将会按照外界建议把“修改后的张量名称从Yi改回LLaMA”。今日零一万物更是在其公司订阅号发布“对Yi-34B训练过程的说明”。
文中表示,在零一万物初次开源过程中,公司发现用和开源社区普遍使用的LLaMA 架构会对开发者更为友好,对于沿用LLaMA部分推理代码经实验更名后的疏忽,原始出发点是为了充分测试模型,并非刻意隐瞒来源。零一万物对此提出说明,并表达诚挚的歉意,公司正在各开源平台重新提交模型及代码并补充LLaMA 协议副本的流程中,承诺尽速完成各开源社区的版本更新。
对于社区反馈,零一万物在文中表达了感谢,并表示公司在开源社区刚刚起步,希望和大家携手共创社区繁荣,在近期发布Chat Model之后,公司将择期发布技术报告,Yi Open-source会尽最大努力虚心学习,持续进步。
李开复在转发这则说明时,也在朋友圈表示,该内容是回应这两天大家对于模型架构的探讨。
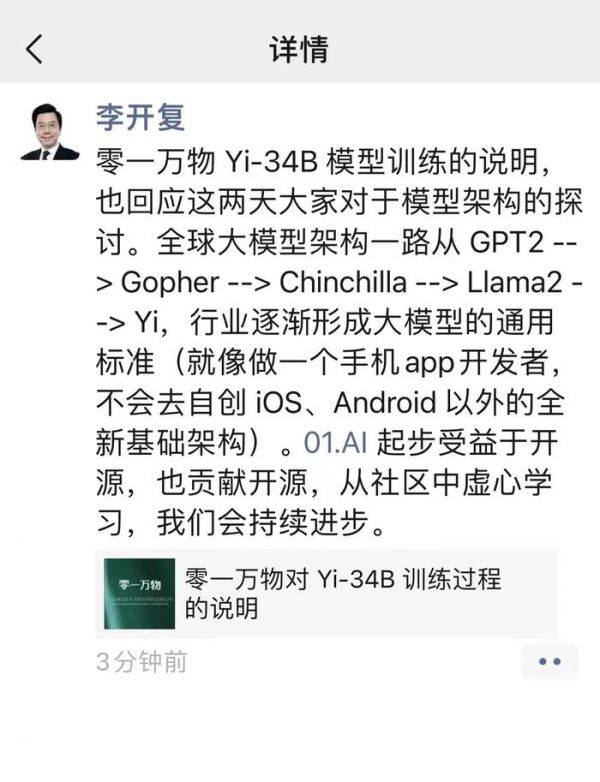
“全球大模型架构一路从GPT2-->Gopher-->Chinchilla-->Llama2-->Yi,行业逐步形成大模型的通用标准(就像做一个手机app开发者,不会去自创iOS、Android以外的全新基础架构)。01.AI起步受益于开源,也贡献于开源,从社区中虚心学习,我们会持续进步。”
“零一万物对Yi-34B训练过程的说明”全文内容如下:
就零一万物的观察和分析,大模型社区在技术架构方面现在是一个处于接近往通用化逐步收拢的阶段,基本上国际主流大模型都是基于Transformer的架构,做attention,activation,normalization,positional embedding等部分的改动,LLaMA、Chinchilla、Gopher 等模型的架构和 GPT 架构大同小异,全球开源社区基于主流架构的模型变化非常之多,生态呈现欣欣向荣,国内已发布的开源模型也绝大多数采用渐成行业标准的 GPT/LLaMA 的架构。然而,大模型持续发展与寻求突破口的核心点不仅在于架构,而是在于训练得到的参数。
模型训练过程好比做一道菜,架构只是决定了做菜的原材料和大致步骤,这在大多数人的认知中也逐步形成共识。要训练出好的模型,还需要更好的“原材料”(数据)和对每一个步骤细节的把控(训练方法和具体参数)。由于大模型技术发展还在非常初期,从技术观点来说,行业共识是与主流模型保持一致的模型结构,更有利于整体的适配与未来的迭代。
零一万物在训练模型过程中,沿用了GPT/LLaMA的基本架构,由于LLaMA社区的开源贡献,让零一万物可以快速起步。零一万物从零开始训练了 Yi-34B 和 Yi-6B 模型,并根据实际的训练框架重新实现了训练代码,用自建的数据管线构建了高质量配比的训练数据集(从3PB原始数据精选到3T token高质量数据)。除此以外,在 Infra 部分进行算法、硬件、软件联合端到端优化,实现训练效率倍级提升和极强的容错能力等原创性突破。这些科学训模的系统性工作,往往比起基本模型结构能起到巨大的作用跟价值。
零一万物团队在训练前的实验中,尝试了不同的数据配比科学地选取了最优的数据配比方案,投注大部分精力调整训练方法、数据配比、数据工程、细节参数、baby sitting(训练过程监测)技巧等。这一系列超越模型架构之外,研究与工程并进且具有前沿突破性的研发任务,才是真正属于模型训练内核最为关键、能够形成大模型技术护城河 know-how积累。在模型训练同时,零一万物也针对模型结构中的若干关键节点进行了大量的实验和对比验证。举例来说,我们实验了Group Query Attention(GQA)、Multi-Head Attention(MHA)、Vanilla Attention 并选择了GQA,实验了Pre-Norm和Post-Norm在不同网络宽度和深度上的变化,并选择了Pre-Norm,使用了 RoPE ABF作为positional embedding等。也正是在这些实验与探索过程中,为了执行对比实验的需要,模型对部分推理参数进行了重新命名。
在零一万物初次开源过程中,我们发现用和开源社区普遍使用的LLaMA 架构会对开发者更为友好,对于沿用LLaMA部分推理代码经实验更名后的疏忽,原始出发点是为了充分测试模型,并非刻意隐瞒来源。零一万物对此提出说明,并表达诚挚的歉意,我们正在各开源平台重新提交模型及代码并补充LLaMA 协议副本的流程中,承诺尽速完成各开源社区的版本更新。
我们非常感谢社区的反馈,零一万物在开源社区刚刚起步,希望和大家携手共创社区繁荣,在近期发布Chat Model之后,我们将择期发布技术报告,Yi Open-source会尽最大努力虚心学习,持续进步。
发布于:北京
相关推荐
李开复AI公司回应大模型抄袭:尊重开源社区的反馈,将更新代码
李开复旗下“零一万物”大模型被指抄袭LLaMA
李开复大模型公司“零一万物”官网上线:打造全新的 AI 2.0平台
李开复被大模型绊了一跤
李开复筹办的AI大模型公司“零一万物”上线,百亿级模型已内测|钛媒体焦点
弹个车称遭遇“恶意维权”,对用户质疑逐一回应
数字广东软件致歉:缺失MIT协议文件,被质疑“自主研发”
阿里云领投李开复 AI 公司新一轮融资,首款大模型正式发布
请尽快升级WinRAR至 6.23及更高版本,新漏洞可远程执行任意代码
呆萝卜“剧情”反转?创始人回应质疑,供应商公开力挺
网址: 零一万物发文回应质疑:对疏忽表示歉意,尽快完成版本更新 http://www.xishuta.com/newsview98270.html
推荐科技快讯






- 1问界商标转让释放信号:赛力斯 95113
- 2人类唯一的出路:变成人工智能 20443
- 3报告:抖音海外版下载量突破1 20263
- 4移动办公如何高效?谷歌研究了 19637
- 5人类唯一的出路: 变成人工智 19554
- 62023年起,银行存取款迎来 10261
- 7网传比亚迪一员工泄露华为机密 8389
- 8五一来了,大数据杀熟又想来, 7957
- 9滴滴出行被投诉价格操纵,网约 7584
- 10顶风作案?金山WPS被指套娃 7179



