HBM技术,如何发展?
伴随着英伟达AI芯片的热卖,HBM(高带宽内存)成为了时下存储中最为火热的一个领域,不论是三星、海力士还是美光,都投入了大量研发人员与资金,力图走在这条赛道的最前沿。
HBM 的初衷,是为了向 GPU 和其他处理器提供更多的内存,但随着GPU 的功能越来越强大,需要更快地从内存中访问数据,以缩短应用处理时间。例如,在机器学习训练运行中,大型语言模型 (LLM) 可能需要重复访问数十亿甚至数万亿个参数,而这可能需要数小时或数天才能完成。
这也让传输速率成为了HBM的核心参数,而已有的HBM都采用了标准化设计:HBM 存储器堆栈通过微凸块连接到 HBM 堆栈中的硅通孔(TSV 或连接孔),并与放置在基础封装层上的中间件相连,中间件上还安装有处理器,提供 HBM 到处理器的连接。与普通的DRAM相比,如此设计的HBM能够垂直连接多个DRAM,能显著提升数据处理速度,
目前,HBM 产品以HBM(第一代)、HBM2(第二代)、HBM2E(第三代)、HBM3(第四代)、HBM3E(第五代)的顺序开发,最新的HBM3E是HBM3的扩展版本,速率达到了8Gbps。
但对于AI芯片来说,光靠传统的硅通孔已经无法满足厂商对于速率的渴求,内存厂商和标准机构正在研究如何通过使用光子等技术或直接在处理器上安装 HBM,从而让像GPU 这样的加速处理器可以获得更快的内存访问速度。
谁才是新方向?
虽然目前业界都在集中研发HBM3的迭代产品,但是厂商们为了争夺市场的话语权,对于未来HBM技术开发有着各自不同的见解与想法。
三星
三星正在研究在中间件中使用光子技术,光子通过链路的速度比电子编码的比特更快,而且耗电量更低。光子链路可以飞秒速度运行。这意味着10-¹⁵个时间单位,即四十亿分之一(十亿分之一的百万分之一)秒。在最近举行的开放计算项目(OCP)峰会上,以首席工程师李彦为代表的韩国巨头先进封装团队介绍了这一主题。

除了使用光子集成电路外,另一种方法是将 HBM 堆栈更直接地连接到处理器(上图中的三星逻辑图)。这将涉及谨慎的热管理,以防止过热。这意味着随着时间的推移,HBM 堆栈可以升级,以提供更大的容量,但这需要一个涵盖该领域的行业标准才有可能实现。
SK海力士
据韩媒报道,SK海力士还在研究 HBM 与逻辑处理器直接连接的概念。这种概念是在混合使用的半导体中将 GPU 芯片与 HBM 芯片一起制造。芯片制造商将其视为 HBM4 技术,并正在与英伟达和其他逻辑半导体供应商洽谈。这个想法涉及内存和逻辑制造商共同设计芯片,然后由台积电(TSMC)等晶圆厂运营商制造。
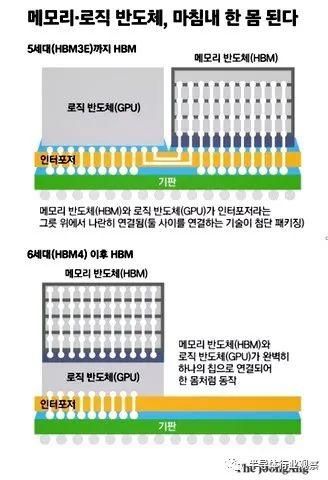
这有点类似于内存处理(PIM)的想法,如果最终不能成为行业标准的话,很可能会变成事实上的厂商独占。
美光
Tom's Hardware 报道称,美光与市场上的其他公司正在开展 HBM4 和 HBM4e 活动。美光目前正在生产 HBM3e gen-2 内存,采用 8层垂直堆叠的 24GB 芯片。美光的 12 层垂直堆叠 36GB 芯片将于 2024 年第一季度开始出样。它正与半导体代工运营商台积电合作,将其 gen-2 HBM3e 用于人工智能和 HPC 设计应用。
美光表示,其目前的产品具有高能效,对于安装了1000万个GPU的设备来说,每个HBM堆栈能节省约5瓦的功耗,预计五年内将比其他HBM产品节省高达5.5亿美元的运营开支。
下一代HBM
2015年以来,从HBM1到HBM3e,它们都保留了相同的1024位(每个堆栈)接口,即具有以相对适中的时钟速度运行的超宽接口,为了提高内存传输速率,下一代HBM4可能需要对高带宽内存技术进行更实质性的改变,即从更宽的2048位内存接口开始。
出于多种技术原因,业界打算在不增加 HBM 存储器堆栈占用空间的情况下实现这一目标,从而将下一代 HBM 存储器的互连密度提高一倍。HBM4 会在多个层面上实现重大技术飞跃。在 DRAM 堆叠方面,2048 位内存接口需要大幅增加内存堆叠的硅通孔数量。同时,外部芯片接口需要将凸块间距缩小到远小于 55 微米,而 HBM3 目前的凸块总数(约)为 3982 个,因此需要大幅增加微型凸块的总数。
内存厂商表示,他们还将在一个模块中堆叠多达 16 个内存模块,即所谓的 16-Hi 堆叠,从而增加了该技术的复杂性。(从技术上讲,HBM3 也支持 16-Hi 堆叠,但到目前为止,还没有制造商真正使用它)这将使内存供应商能够显著提高其 HBM 堆叠的容量,但也带来了新的复杂性,即如何在不出现缺陷的情况下连接更多的 DRAM 凸块,然后保持所产生的 HBM 堆叠适当且一致地短。
在阿姆斯特丹举行的台积电 OIP 2023 会议上,台积电设计基础设施管理主管这样说道:"因为[HBM4]不是将速度提高了一倍,而是将[接口]引脚增加了一倍。这就是为什么我们要与所有三家合作伙伴合作,确保他们的 HBM4(采用我们的先进封装方法)符合标准,并确保 RDL 或 interposer 或任何介于两者之间的产品都能支持(HBM4 的)布局和速度。因此,我们会继续与三星、SK 海力士和美光合作"。
目前,台积电的 3DFabric 存储器联盟目前正致力于确保 HBM3E/HBM3 Gen2 存储器与 CoWoS 封装、12-Hi HBM3/HBM3E 封装与高级封装、HBM PHY 的 UCIe 以及无缓冲区 HBM(由三星率先推出的一项技术)兼容。
美光公司今年早些时候表示,"HBMNext "内存将于 2026 年左右面世,每堆栈容量介于 36 GB 和 64 GB 之间,每堆栈峰值带宽为 2 TB/s 或更高。所有这些都表明,即使采用更宽的内存总线,内存制造商也不会降低 HBM4 的内存接口时钟频率。
总结
与三星和 SK海力士不同,美光并不打算把 HBM 和逻辑芯片整合到一个芯片中,在下一代HBM发展上,韩系和美系内存厂商泾渭分明,美光可能会告诉AMD、英特尔和英伟达,大家可以通过 HBM-GPU 这样的组合芯片获得更快的内存访问速度,但是单独依赖某一家的芯片就意味着更大风险。
美国的媒体表示,随着机器学习训练模型的增大和训练时间的延长,通过加快内存访问速度和提高每个 GPU 内存容量来缩短运行时间的压力也将随之增加,而为了获得锁定的 HBM-GPU 组合芯片设计(尽管具有更好的速度和容量)而放弃标准化 DRAM 的竞争供应优势,可能不是正确的前进方式。
但韩媒的态度就相当暧昧了,他们认为HBM可能会重塑半导体行业秩序,认为IP(半导体设计资产)和工艺的重大变化不可避免,还引用了业内人士说:"除了定制的'DRAM 代工厂'之外,可能还会出现一个更大的世界,即使是英伟达和 AMD 这样的巨头也将不得不在三星和 SK 海力士制造的板材上进行设计。"
当然SK 海力士首席执行官兼总裁 Kwak No-jeong的发言更值得玩味,他说:“HBM、计算快速链接(CXL)和内存处理(PIM)的出现将为内存半导体公司带来新的机遇,这种滨化模糊了逻辑半导体和存储器之间的界限,内存正在从一种通用商品转变为一种特殊商品,起点将是 HBM4。”
由此看来,下一代HBM技术路线的选择,可能会引发业界又一轮重大的洗牌,谁能胜出,我们不妨拭目以待。
发布于:广东
相关推荐
德国HBM称重传感器RTNC3/2.2t
PW10AC3MR/250Kg称重传感器/德国HBM
德国HBM力传感器 U9C/1KN
AE301 1-AE301S6德国HBM信号放大器
2024年HBM供应量将增长105%,销售收入将大涨127%
1-C2/0.5KN C2/100KN德国HBM测力传感器
德国HBM U3/5KN 1-U3/1KN力传感器
Z6FC3/100kg波纹管式传感器 德国HBM称重传感器
抓住 AI 大趋势,三星、美光积极筹备 HBM 扩建计划
传三星已获得英伟达HBM订单,最快10月供货
网址: HBM技术,如何发展? http://www.xishuta.com/newsview99293.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95178
- 2人类唯一的出路:变成人工智能 20885
- 3报告:抖音海外版下载量突破1 20771
- 4移动办公如何高效?谷歌研究了 20054
- 5人类唯一的出路: 变成人工智 20036
- 62023年起,银行存取款迎来 10307
- 7网传比亚迪一员工泄露华为机密 8456
- 8五一来了,大数据杀熟又想来, 8338
- 9滴滴出行被投诉价格操纵,网约 7960
- 10顶风作案?金山WPS被指套娃 7213



