如果互联网真是有记忆的,这些记忆可以分为哪几种类型?
编者按:本文来自微信公众号“全媒派”(ID:quanmeipai),作者:Lilyann,36氪经授权发布。
QQ空间留言板、淘宝收货地址、听歌软件……这些载体与我们的心情、状态等个人信息密切相关,在网络空间形成了一个个虚拟“记忆之场”。
都说“互联网是有记忆的”,而互联网的记忆归根结底是人的记忆,这些数字载体的存在,为个体记忆与集体记忆提供了更便捷的容器。那么,网络上的这些载体是如何充当“记忆之场”的?我们又是如何为发生在网络世界里的事情存档的呢?
本期全媒派从以下三方面发起讨论,搭乘这艘“互联网时光机”,探讨网络载体的信息存储与再现能力及特征,反思人们与信息易逝性的“对抗”:
1、互联网载体是怎样充当记忆之场的?记忆的5种分类有哪些?
2、个体记忆与集体记忆在网络上的保存呈现出怎样的特征?
3、我们对网络记忆的处理应该注意些什么?
我们在互联网上的记忆如何被划分?
什么是记忆之场?如果我们将时间倒推回1978年,在当时学界着眼研究叙事史的趋势之下,法国历史学家皮埃尔·诺拉在法国社会科学高等研究院开设了一门讨论课,呼吁关注被学者们忘却的“当下历史”——记忆之场。
1984年,《记忆之场》的第一部“共和国”(la république)一卷出版,之后又更新了两部,名为“民族”(la nation)与“复数的法兰西”(les France)。在书中,诺拉提出了三种类型的记忆,与现今的媒介记忆研究也有共通之处:
1、作为记录的记忆:诺拉以档案与口述调查为例,认为虽然这些从业者致力于“为人们提供过去的声音”,但始终属于“第二记忆”,即为制作出来的记忆,类似如今媒体的叙事,这是一种非个人、带有加工色彩的记忆呈现,而受众却可能将这些来自外部的记忆“内在化”,影响自身对历史的印象与理解。
2、作为义务的记忆:每个个体化的记忆都应该拥有自己的历史叙事,在这个基础上,记忆作为一种“个人义务”被理解,受众有义务自主地记录、保存与传播记忆,作为私人事务的一部分,在其中逐渐找到身份认同与归属感。
3、作为距离的记忆:在诺拉看来,这一点主要体现在历史学家的写作中,为了更加突出地表达历史的进程,他们常常会通过划分“从前”“此刻”与“未来”,以分析相比之下,如今究竟是“进步”还是“衰退”。
一方面,记忆因此有了距离感,另一方面,历史学者们又始终追求“祛除距离”——“历史学家就是防止历史仅仅成为历史的人”。
在此之下,记忆之场这一概念希望表达的是重新寻回历史与记忆的连结,帮助人们认识到记忆不等同于历史。
记忆应该是私人化的,是不能忘却的义务,是需要我们每个人“在场”创造,而非“离场”接受统一叙述的历史,只有这样,我们才会置身于“均匀曝光的世界”中,抵达日常、真实、不断翻新的“记忆之场”。
那么,互联网是否会为我们提供这种“记忆之场”?答案是肯定的。如果说网络赋予每个人通过发声与上传记忆的方式,书写个人历史,在虚拟载体的加持之下,记忆也具备了更多的分类。
1、按照能动性划分。
你在微博记录日常,在网易云音乐为好听的歌点下红心,在知乎收藏某条高赞回答,这些都属于“主动创造数字记忆”。而各大平台基于你的使用行为而进行的推荐、弹窗、邀请填写体验问卷,或者搜索引擎基于用户所在地理位置决定搜索结果的呈现顺序,都是试图影响数字记忆,或者邀请你留下更多个人痕迹,在某种程度上说,这些属于“被动接受着外部媒介对记忆的干预”。
但是这两者之间并非有明确界限,例如,在淘宝上搜索某件商品后,算法又智能推荐更多相关物件,你又在筛选的过程中,从信息流推荐页点进了自己感兴趣的其中一款。因此,比起区分主动或被动留下数字记录,更多是我们在与算法相互配合,共同帮助平台更好地了解我们,也就有更多可能性能够留住我们。
2、按照留存性划分。
记忆能够在云端保留多久?是否人人都希望在数字平台留住记忆?
有些平台支持永久保存,例如公共社区Matters利用IPFS分布式存储技术,使用户发布的每一篇文章都会上载到星际文件系统IPFS的节点上永久存储,无法被删除和修改。
但以Snapchat、具备story功能的Instagram为代表的社交媒体则反其道而行之,通过“阅后即焚”功能主打“瞬时场景社交”,减轻用户“自我呈现”的压力,又在激发好奇心的同时有效保护隐私,同样收获大批好评。
而有些社交媒体,特别是通讯软件,则通过另外一种方式表达“在场”,最为直观的例子是:相比QQ提供给用户设置“在线”与“离线”状态的权利(以及隐身这种中间态),微信则不做区分,相当于我们每一个人在微信上都是永久在线、永久连接(permanently online, permanently connected)。[1]换言之,在这类平台上,我们的数字记忆被默认实时在场、实时记录着。
3、按照加工性划分。
在平台上发布内容之后,能否支持再加工?
发完一条朋友圈后如果发现错别字,只能删除重发,连同着点赞与回复都不复存在,而在2017年,微博上线编辑功能,优先提供给7级会员、媒体以及政务账号使用,后开放给全部会员用户,同时也增加了“查看编辑记录”功能,让用户既可以回顾此前的内容编辑历史,又能够将编辑前后的效果做对比,方便后续进行调整。
在更早之前,类似知乎、Instagram等软件已经支持二次编辑,但微博的改版还是引发了较为热闹的讨论,大家对“历史记录是否需要再加工”的看法不一。
有网友认为这种操作的可修正性,使我们在编写发布微博时更有安全感,也有网友指出:“记录一条条不能变更的过去才是微博原本的意义,既然连过去都可以再编辑,还能找得回当时写下那条微博的感觉么?还能凭借一条条微博记录一瞬间的情感吗?”
除此之外,对数字痕迹的编辑记录也会被保留可见,甚至可以因此“发现一些端倪”。所以,为瞬时记忆提供再加工的空间,以及将加工过程透明化,就会使得“记忆”这个在自然中产生的动作变得复杂许多。
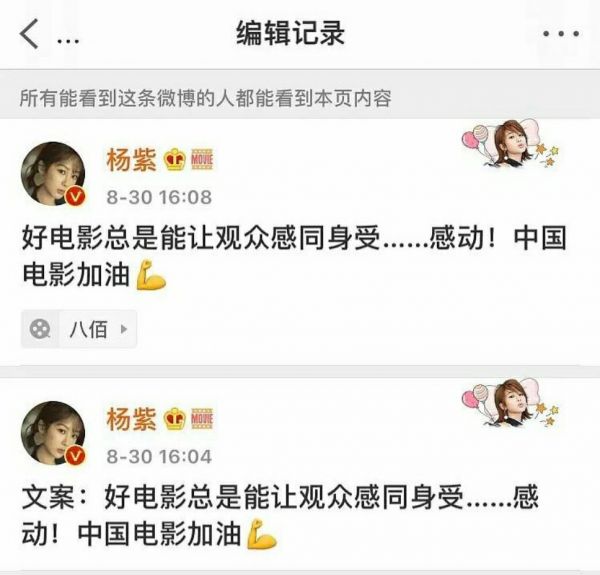
演员杨紫发微博宣传电影《八佰》,忘记删除“文案”两字,后经过编辑及时调整。图片来源:微博截图
4、按照归宿性划分。
我们在互联网上生产的记忆,最终会流向何处?早在1925年,法国社会学者哈布瓦赫提出“集体记忆”的概念,20世纪80年代,美国社会学者康纳顿则在此基础上提出“任何社会秩序下的参与者必须具有一个共同的记忆 ”,强调集体记忆与个人记忆的区分度以及前者的必备性。
然而,在互联网时代,两者的界限变得愈来愈模糊不清,很难清楚说明我们每个人在数字世界中留下的记录是否被合流或者内化成为了社会集体记忆的一个分支。
在“人人皆可发言”的技术民主氛围之下,集体记忆的构建也随即进入了大众书写时代,[2]每个群体与个人都有权利对正在生产的集体记忆进行叙述与解释。
5、最后,按照时效性划分。
这能够分为“共时性”与“历时性”两个维度,更多体现在个人参与社会群体事件的过程中。
此前有学者提出观点为:“集体记忆的社会建构有两个维度。在共时维度上,记忆建构表现为群体差异;在历时维度上,记忆建构表现为代际差异。”[3]
对于前者,它更多体现在身处实时的舆论场中,因群体差异而众说纷纭;而对于后者,一个较为有代表性的例子则为每年的热词评选,从2019年的“雨女无瓜、柠檬精、断舍离、我太难了”到2020年的“云监工、光盘行动、奥利给、好家伙”,我们的集体记忆凝炼成为语言的符号,在每年的更替中展现着时代的差异。
互联网上的记忆保存呈现出哪些特征?
有时候,人们难免会误认为网络上的信息是可以永久保存的,可事实不尽如此。每时每刻都在虚拟空间产出着记忆的网友们,也有可能不断失去着记忆。那么,这些“互联网碎片”在被保存时,呈现出哪些基本特征呢?
上传并保存记忆有时不只是为自己
当有些90后已经听不懂00后的“黑话”,父母有时误会我们发过去的表情包,我们对“共同记忆”的诠释也会逐渐差异化,甚至共识越来越少。因此,有些人正在如同西西弗斯一般,尽心地打捞着互联网角落的碎片,试图守护着互联网易逝的记忆。
国外论坛Reddit曾出现过一个热门贴子,叫做“让老龄网民来告诉当今的年轻人,早年间的互联网是怎样的”,热门回答如“你一定不知道拨号上网有多么痛苦!除了要忍受烦人的噪音,还要等待8分钟才刷开一个一个网页”、“网上的聊天室也只有两个功能:群聊和单聊”......[4]
微博上也兴起了类似于@千禧bot这样的社交账号,目的是“想从20和21世纪的裂缝中打捞一些有趣的东西,旨在分享一些属于90年代末和00年代初的记忆。”在这个账号里,一张张索尼Walkman、数码暴龙机的照片,给了网友分享记忆、找寻身份认同的机会。
图片来源:微博截图
豆瓣上也不乏这类跨越时代、追寻过往记忆的小组。他们有人“假装活在1980-2000年”,试图逃离到过去,也试图守护那个年代的记忆。
还有人默默无言地执笔书写着互联网的编年史。豆瓣上曾有一位叫作Clash-Cash-Car的网友,在现实生活中是一位平凡的保安,但他从2008年开始到2016年整整八个年头,在豆瓣上添加了6108个音乐条目,为那些没有人听过的唱片建立了371个标签,2016年,网友得知他去世,有人将他称为“中华音乐圈的扫地僧”,纪念他为数字世界的贡献。
在这些场景中,人们作为记忆的载体本身,不仅是使用着互联网,而且在其中建设着互联网,记忆的载体成为了记忆的一部分。
保护记忆不仅是个体事务,也是组织性的
1996年,作为“互联网档案计划”的一部分,美国非营利性的数字图书馆——互联网档案馆(Internet Archive)成立,它将互联网上的数字数据如网站、音乐、动态图像,以及数百万书籍的永久性免费存储,并且提供给用户免费下载。
截至2021年1月,这里已经存储了5140亿个网页。其中,所需要的带宽、存储以及人力开支依靠企业资助,以及网友的自发捐款而生。
在这里,你不仅能够检索到2000年的谷歌页面,还可以找到仅剩的“孤品”:例如此前音乐社交巨头Myspace因为服务器迁移,几乎丢失了2016年之前用户上传的所有内容,幸好被互联网档案馆收录了部分音乐,才使得一些音乐人早期的作品被妥善保留了下来。
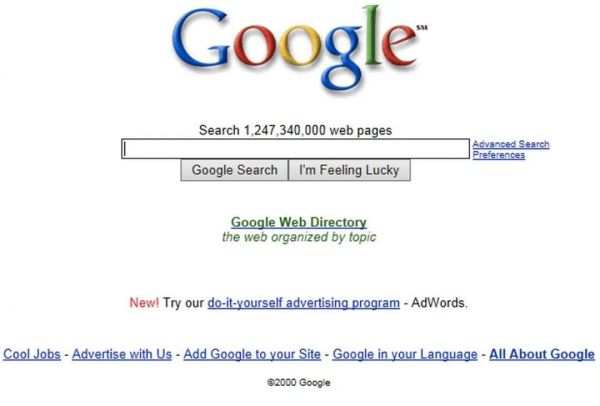
千禧年伊始的谷歌界面。图片来源:谷歌
越来越多的机构也在加入保护群体数字记忆的行列。2003年,国际互联网保存联盟成立,由12个参与机构组成,截至2021年1月,已有55个机构加入,而我国的国家图书馆,也于2007年正式成为国际互联网保存联盟的成员单位,着力于互联网的信息采集和保存。
2019年,国家图书馆互联网信息战略保存项目启动,个人公开发布的,超过2000万亿条微博都将被国图保存,作为信息存档工作的一部分。而类似于Twitter上的所有推文都会被收录到美国国会图书馆。
载体不断消逝,但大家都在学会“好好告别”
在网络世界,产品的淘汰是一件再正常不过的事情,对于那些承载了网友们诸多记忆的应用而言,每一次的关停都意味着一部分记忆的流离失所。
数字坟墓里已经埋藏了太多大大小小的产品,如今面临关停的信息载体已经学会了如何“好好告别”。不仅提前公告,引导用户进行历史记录的迁移,有些还直接将原平台的数据合并到下一个平台,以免资料丢失。
例如今年年初关停的虾米音乐,就提前一个月向用户宣布收尾工作,在停服的前一天,虾米的最后一次日常推送中,给全站用户送上了告别礼:歌单中30首歌,包括了《我终于失去了你》《你一直在》《好久不见》《再见》,也掀起了一波怀旧风潮。当数字回忆到了消逝的那一刻,我们才更深刻的了解它对我们有多重要。
通过网络处理记忆时应该注意哪些问题?
如今互联网提供给人们的不仅仅是数字记忆的记录,还有关于数字记忆的处理。例如,每一个网友都能够对已经生产出的数字记忆进行编辑再加工,能够在众媒时代利用社交媒体的发声筒参与、解读。
在全媒派往期推文《人人都是数字仓鼠:我们为何越来越喜欢将信息存储到网上?》中,我们分析了数字建档对于人们记忆习惯的影响:因为媒介技术提供了强大的存储、备份与搜索能力,使得我们对周遭的记忆能够“有恃无恐”地忘记。记住一切的互联网让我们敢于遗忘。
但从另外一个程度来说,还需要额外注意两点:
第一点是,不要对存储数字记忆的载体过于信赖。选择将生活碎片交给互联网托管并非一劳永逸,因为诸多事例说明:你永远不知道下一个关停的软件是哪一个;
而第二点则是,不要将自己的回忆变成剩余符号。这里的“剩余符号”,例如各大青春片中呈现的经典桥段,又如游戏中的长城与三国人物,比起想要烘托的气氛,其本身的价值在其中逐渐祛魅,变成了一个意义不明的符号,如果过分在意记忆这个形式,而忽略了我们生活的日常点滴,也就相当于悬在半空,忘记自己本心源于何处。
无论如何,赛博时代的集体记忆,是我们共同搭建的一座“数字图书馆”,也是我们亲手创造出的“互联网时光机”。不过,眼前还有许多问题等待解决:当大量信息储存在云端,如果发生“数字灾难”,是否会导致全民“数字化遗忘”?当集体记忆趋向碎片化,这种去中心式的的话语结构会对群体的凝聚力产生什么影响?数字记忆的飞速更新是否要求每个人实时“在场”,剥夺“离场”的自由?
理想化的状态是,在不远的将来,互联网载体作为保留、传播记忆的介质,使每个人的回忆都能在广袤的数字原野上,连续而相互连结地闪着光。
这是属于21世纪赛博时代的记忆之场,它并非只有唯一的宏大叙事,相反的,它由每一位个体的真情实感创造,褪去回忆泛黄的滤镜,重新注入生命力。
参考链接:
1.Nairo.(2020).社交媒体,是怎样改变人类互动的?| 人人都是产品经理
http://www.woshipm.com/it/4066227.html
2.胡百精. (2014). 互联网与集体记忆构建[J].中国高校社会科学 99-106
3.陈全黎.(2016).文学记忆史研究的三条路径-中国社会科学网
http://www.cssn.cn/skjj/201606/t20160613_3066865.shtml
4.砍柴网. (2019).为了不让朋友圈失传,这群人正在备份整个互联网 | 互联网的未来发展趋势 | 互联网是什么行业_科技猎
http://www.kejilie.com/ikanchai/article/vQzYfy.html
相关推荐
如果互联网真是有记忆的,这些记忆可以分为哪几种类型?
记忆的未来:用 AI 解决人类记忆缺陷
睡觉时,大脑正在抹除你的记忆?
记忆一定是你自己的吗?也有可能是媒介塑造的
如何操控人类的记忆?
36氪首发 | 专注于解决记忆问题,一周背完一学期的英语单词,「趣记忆」获数千万天使轮融资
记忆是如何欺骗我们的?
《遗忘工程师》:一次超现实记忆之旅
北大团队成功实现精准删除特定记忆,马斯克脑机接口有望今年人体测试
对话戴锦华:疫情成为历史和人民共同的记忆
网址: 如果互联网真是有记忆的,这些记忆可以分为哪几种类型? http://www.xishuta.com/zhidaoview19314.html
推荐专业知识





- 136氪首发 | 瞄准企业“流 3926
- 2失联37天的私募大佬现身,但 3217
- 3是时候看到全球新商业版图了! 2808
- 436氪首发 | 「微脉」获1 2759
- 5流浪地球是大刘在电力系统上班 2706
- 6招商知识:商业市场前期调研及 2690
- 7Grab真开始做财富管理了 2609
- 8中国离硬科幻电影时代还有多远 2328
- 9创投周报 Vol.24 | 2183
- 10微医集团近日完成新一轮股权质 2180



