人类对大脑多巴胺机制理解错了,顶级版AlphaGo背后技术启发脑科学,DeepMind最新成果登上Nature
编者按:本文来自微信公众号“量子位”(ID:QbitAI),作者:赖可、乾明、十三,36氪经授权发布。
人工智能,往往从人类思维方式中获取灵感。
但现在反过来了!
人工智能的进步,已经能够为揭秘大脑如何学习提供启发。
这是来自DeepMind的最新研究,刚登上Nature,研究证明:
分布式强化学习,也就是AlphaGo的顶级版Alpha Zero和AlphaStar背后的核心技术,为大脑中的奖赏通路如何工作提供了新解释。

如此结论,也让DeepMind创始人哈萨比斯非常激动,发表推文表示:
我们在机器学习方面的研究,能够重新认识大脑的工作机制,这是非常令人兴奋的!
他当然有理由兴奋。
从长远来看,这也证明了DeepMind提出的算法与大脑运作逻辑相似,也就意味着能够更好地拓展到解决复杂的现实世界问题上。
而且一直以来,哈萨比斯的目标就是打造通用人工智能。
Alpha系列背后利器:分布式强化学习
强化学习,就是让智能体在一个未知的环境中,采取一些行动,然后收获回报,并进入下一个状态。
而时间差分学习(temporal difference learning,TD)算法,可以说是强化学习的中心。
它是一种学习如何根据给定状态的未来值,来预测价值的方法。
算法会将新的预测和预期进行比较。
如果发现两者不同,这个“时间差分”就会把旧的预测调整到新的预测中,让结果变得更加准确。
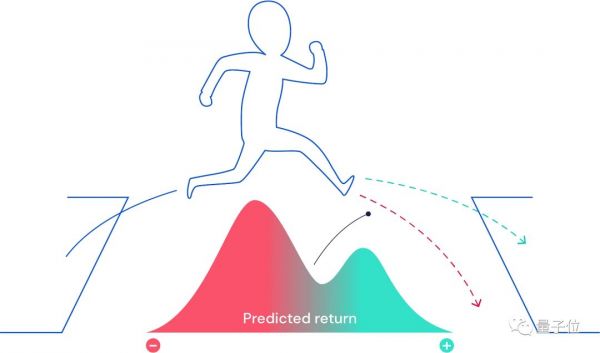
△当未来不确定时,未来的回报可以表示为一种概率分布。有些可能是好的结果(蓝绿色),有些结果可能是不好的(红色)。
一个特定的行为所带来的未来奖励数量,通常是未知且随机。在这种情况下,标准的TD算法学习去预测的未来回报是平均的。
而分布式强化学习则是更复杂的预测方式,会预测所有未来奖励的概率分布。
那人类大脑的多巴胺奖赏机制是怎么样的呢?
然后研究的雏形就在DeepMind研究人员的脑海中生根了。
不研究不知道,一研究真的“吓一跳”。

过去,人们认为多巴胺神经元的反应,应该都是一样的。
有点像在一个诗唱班,每个人唱的都是一模一样的音符。
但研究小组发现,单个多巴胺的神经元似乎有所不同——所呈现的积极性是多样的。
于是研究人员训练小鼠执行一项任务,并给予它们大小各异且不可预测的奖励。
他们从小鼠腹侧被盖区域(Ventral tegmental area,控制多巴胺向边缘和皮质区域释放的中脑结构)中发现了“分布式强化学习”的证据。
这些证据表明,奖励预测是同时并行地由多个未来结果表示的。
这和分布式机器学习的原理也太像了吧?
解释大脑多巴胺系统
实验运用了光识别技术来记录小鼠大脑中腹侧被盖区中单个多巴胺神经元的反应。
腹侧被盖区富含多巴胺与5-羟色胺神经,是两条主要的多巴胺神经通道的一部分
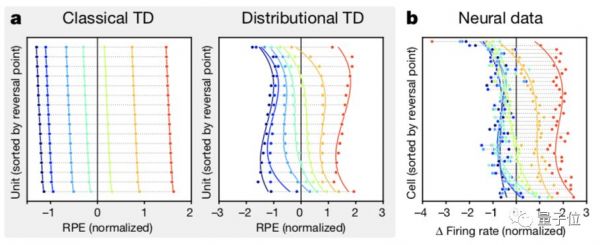
基于强化学习理论,研究假设大脑存在多巴胺的奖赏预测误差(RPE)。
一个信号会引起一个奖赏预测,当奖赏预测低于分布的均值时,会引起负的RPE,而较大的奖励会引起正的RPE。
在一般强化学习中,获得的奖励幅度低于平均值分布将引起消极(负)的RPE,而较大的幅度将引出积极(正)的RPE(如上图a左所示)。
在分布式强化学习中,每个通道都携带不同的RPE价值预测,不同通道的积极程度不同。
这些值的预测反过来又为不同的RPE信号提供了参考点。在最后的结果上,一个单一的奖励结果可以同时激发积极(正)的RPE和消极的RPE(如上图a右所示)。
记录结果显示,小鼠大脑的多巴胺神经元反转点根据积极程度的不同而不同。符合分布式强化学习的特点(如上图b所示)。
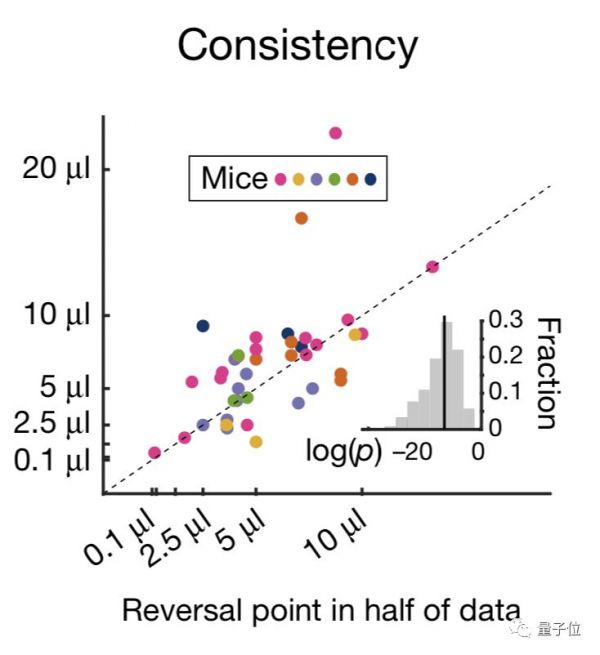
为了验证神经元反应多样性不是随机的,研究者做了进一步验证。
将随机地将数据分成两半,并在每一半中独立地估计反转点。结果发现其中一半的反转点与另一半的反转点是相关的。
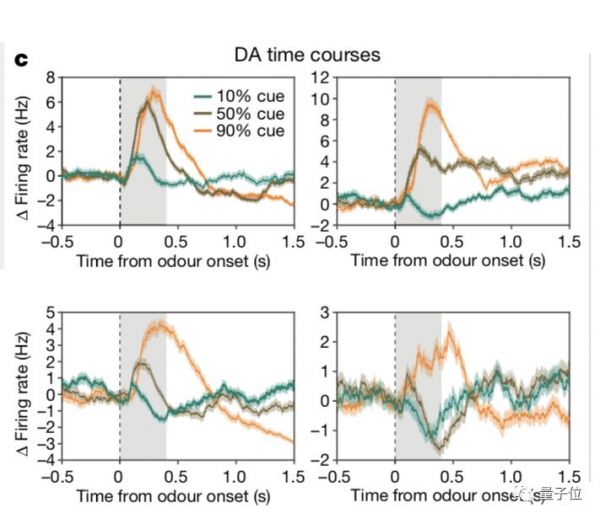
为了进一步了神经元对奖赏预测的处理方式。研究者给神经元进行了三种不同的信号刺激。
分别是10%、50%、90%的奖赏概率,并同时记录了四个多巴胺神经元的反应。
每条轨迹都是对三种线索之一的平均反应,零时是开始时间。
结果显示,一些细胞将50%的线索编码为90%的线索,而另一些细胞同时将10%的线索编码为10%的线索。
最后 ,研究者还进行了验证,试图从多巴胺细胞的放电率来解码奖赏分布。
通过进行推理,成功地重建了一个与老鼠参与的任务中奖励的实际分配相匹配的分配。
初步验证了小鼠的大脑分布式强化学习机制,给研究员带来了更多的思考:
是什么电路或细胞级机制导致了不对称的多样性?
不同的RPE通道是如何与相应的奖励预测在解剖学上结合?
这些大脑的谜团都有待于进一步了解。
而且这一研究结果也验证了之前多巴胺分布对成瘾和抑郁等精神障碍机制影响的假说。
有理论认为,抑郁症和双相情感障碍都可能涉及关于未来的负面情绪。
这些情绪与未来的负面预测偏差有关,偏差则可能来自于RPE coding28、29中的不对称。
但更多的意义,则是对当前机器学习技术发展的激励。
DeepMind 神经科学研究负责人Matt Botvinick说:“当我们能够证明大脑使用的算法,与我们在人工智能工作中使用的算法类似时,这将增强我们的信心。”
跨学科研究团队的成果
这篇论文中一共有3位共同一作,也是跨学科团队的研究成果。
排在第一位的是Will Dabney,DeepMind的高级研究科学家。

△Will Dabney
本科毕业于美国奥克拉荷马大学,在马萨诸塞大学阿默斯特分校获得了博士学位。
在加入DeepMind之前,曾在亚马逊的Echo团队工作过。
2016年加入DeepMind。
第二位共同一作是Zeb Kurth-Nelson,他是DeepMind的研究科学家。

△Zeb Kurth-Nelson
博士毕业于明尼苏达大学,2016年加入DeepMind。
第三位共同一作是Naoshige Uchida,来自于哈佛大学,是分子和细胞生物学教授。

△Naoshige Uchida
此外,DeepMind创始人哈萨比斯也在作者之列。
他一直都希望,能够通过人工智能的突破也将帮助我们掌握基础的科学问题。
而现在的研究发现,他们致力的研究方向,竟然能够给人们研究大脑带来启发,无疑坚定了他们的研究信心。
One More Thing
就在这篇论文登上Nature的同时,DeepMind还有另外一篇研究出现了同一期刊上。
它就是DeepMind在2018年12月问世的AlphaFold,一个用人工智能加速科学发现的系统。
仅仅基于蛋白质的基因序列,就能预测蛋白质的3D结构,而且结果比以前的任何模型都要精确。
DeepMind称,这是自己在科学发现领域的第一个重要里程碑,在生物学的核心挑战之一上取得了重大进展。
截止到现在,DeepMind提出Alpha系列,从AlphaGo,到AlphaZero,再到AlphaStar,以及现在的AlphaFold,一门4子,全上了Nature。
唉…顶级研究机构的快乐,就是这么朴实无华,且枯燥。
传送门
https://www.nature.com/articles/s41586-019-1924-6
封面图来自pexels
相关推荐
人类对大脑多巴胺机制理解错了,顶级版AlphaGo背后技术启发脑科学,DeepMind最新成果登上Nature
碾压99.8%人类对手,三种族都达宗师级,星际AI登上Nature,技术首次完整披露
DeepMind星际争霸机器人领先人类多少?答:191年
那个AlphaGo背后的男人,获得2019 ACM计算奖
控制AI之战:揭秘谷歌与DeepMind的爱恨情仇
谷歌量子霸权论文正式登上Nature,200秒顶超算10000年
DeepMind新成果:让AI做了200万道数学题,结果堪忧
算法耗尽全球GPU算力都实现不了,DeepMind阿尔法系列被华为怒怼,曾登Nature子刊
脑科学这个商业前景被严重低估的领域,AI如何助力其产业化
我们给AlphaGo做了一次智商检测,结果发现……
网址: 人类对大脑多巴胺机制理解错了,顶级版AlphaGo背后技术启发脑科学,DeepMind最新成果登上Nature http://www.xishuta.com/zhidaoview5991.html
推荐专业知识







- 136氪首发 | 瞄准企业“流 3926
- 2失联37天的私募大佬现身,但 3217
- 3是时候看到全球新商业版图了! 2808
- 436氪首发 | 「微脉」获1 2759
- 5流浪地球是大刘在电力系统上班 2706
- 6招商知识:商业市场前期调研及 2690
- 7Grab真开始做财富管理了 2609
- 8中国离硬科幻电影时代还有多远 2328
- 9创投周报 Vol.24 | 2183
- 10微医集团近日完成新一轮股权质 2180



