普通工程师简史

图片来源@视觉中国
文|郭华
我今年大概三十多岁,因为工作的关系,看上去比实际年龄还要老一些,像个微秃的胖子,但如果硬要回忆的话,我也是有过青春的。
只不过时间稍微有些久远,要到2004年。
那年周星驰拍了《功夫》,王宝强出演了《天下无贼》,百度收购了hao123,腾讯刚刚上市,而支付宝还没出现。
那年我刚上高一,才知道县城比村子大的多。于是开始在懵懂中新奇,又在新奇中自卑,我不知道欧洲杯,不认识贝克汉姆,也没用过摩托罗拉,我不大爱说话,只是喜欢晚自习。
因为只有在这个时候我才会感到一种青涩的希望,我可以用左手托着脑袋,把耳机藏在袖子里听周杰伦的七里香,然后目光穿过右手,偷偷的看隔壁背单词的女同学,她的马尾辫摆来摆去,嘴巴嘟嘟囔囔不敢出声,在红白校服的衬托下,我觉得她好像一个谁。
我常常想,如果时间可以定格的话,那最好一直留在那个瞬间。
但这是不可能的,关于我的未来正在展开,只是遥远的像与我无关。
2003、2004年的时候,谷歌接连发表了两篇论文,大概意思就是自己的数据太多了,所以就开发了两个系统,一个是分布式存储系统GFS,一个是分布式计算系统MapReduce,然后说在这两个系统的帮助下,谷歌已经完美的解决了这些问题,所以如果你也有类似问题的话,最好也这么试试,因为如果我们都没想出来的话,应该是不存在什么其他办法了云云。
论文很短,也没什么公式,再加上是谷歌写的,所以很快就传播开了。
在众多读者之中,有一个叫Doug Cutting人。
他当时正在弄自己的开源搜索引擎Nutch,碰到了很多论文里描述的问题,所以他在看到这两篇文章的时候眼睛立马就亮了,断定这就是他苦苦追寻的东西,很快便照着文章在Nutch里把两个系统都实现了一遍。在这个过程中,他还敏锐的意识到这种处理范式有着比搜索引擎广阔的多的应用空间,所以又在2006年把这两个系统从Nutch中独立了出来,创建了大名鼎鼎的Hadoop项目。
他看到了Hadoop的前景,也意识到了自己的局限,Hadoop要发展仅仅靠自己是不够的,他还要找一个地方,一个适合Hadoop成长的地方。于是他来到了雅虎,也就是在雅虎,Hadoop集群突破了一千台,从一个试验品变成了真正可用的大系统,然后以燎原之势席卷了全球互联网公司。
2007年,中国的百度、淘宝等纷纷开始调研Hadoop。
而我也在当年上了大学,来到了海滨城市大连。
实话实说,我对计算机只有抗拒,因为每次坐到它面前我都会头昏脑胀,所以报志愿的时候便避开了所有与之相关的专业,只不过由于分数不够,我还是被调剂到了软件工程系。这个系有两个特点,一个是学费高,一个是分数低,所以当时大部分同学都是被调剂过来的,很少有人对学习有什么热情。
辅导员也看到了这一点,于是他给我们推荐了《世界是平的》这本书,让我们好好看看,计算机就是未来。
我大约看了,也或者没看,总之除了书名外什么都不记得,但交了学费总要学习,上了大学总要毕业。而且退一万步讲,班里都是比自己又高又帅的男生,看着那三四个女同学,我便不再抱任何希望了,于是就借了几本C++的书跑去了图书馆,开始琢磨计算机这个莫名其妙的东西。
我的进步是缓慢的,大数据的发展却是迅猛的。
Hadoop不断攻城略地,在展示力量的同时也暴露了自己的问题,一是运行起来太慢,二是MapReduce的编程方式太难用——这就是开源软件的运作方式,我并不完美,但你可以一起完善。
2008年的时候,Facebook率先开始了对Hadoop易用性的改造,发起了一个叫做Hive的项目,其目的就是在MapReduce上加一层SQL,让所有的人都能直接上手Hadoop。这个项目迅速走红,Hadoop加Hive成了很多公司大数据的标准解决方案,直到今天都没过时。
但是如果把Hadoop比做一辆车的话,Hive只是把原来的手动挡换成了自动挡,好开是好开了,但引擎没变,所以速度还是上不来。
这时号称比Hadoop快一百倍的Spark就出现了。
Spark的作者曾经在谷歌做过分布式系统。他觉得Hadoop最大的问题就是数据都放硬盘了,如果能把他们放在内存的话,速度肯定会快很多。在这个思路的引导下,他发明了一种叫做RDD的分布式数据结构,巧妙的利用内存解决了Hadoop的性能问题。
Spark很快就成了MapReduce的替代方案。
到这时,Hadoop已经成了一个庞大的生态系统,从计算到存储到查询到工作流,其版图扩展到了大数据的方方面面,一时间成了所有人谈论的焦点。
这大概是2010年。
当时我刚上大四,正在头疼研究生实验室的事情,拿不准该选哪个,便去咨询一个学长。学长说现在Hadoop最火,找工作只要说懂这个很快就能拿到offer,反正你读研也是要工作的,不如选个Hadoop相关的吧。我信以为真,再加上当时一直想和几个同学出去玩,早有点不耐烦了,就随便选了一个介绍里有Hadoop的实验室,背着书包离开了大连。
2011年,我来到杭州,开始真正接触Hadoop,然后在导师的建议下看了03、04年谷歌那两篇文章,终于弄懂了什么叫MapReduce,但这并没有让我有多少成就感,反而觉得越看不懂的越多,一想起Hadoop那庞大的版图,便觉得前路漫漫怎么都学不完。
我是悲观的心灰意冷,但有人却是乐观的热血向前。
比如Nathan Marz,他在这年兴致勃勃的发布了Storm,口号是实时的Hadoop。
简单来说,那时Hadoop版图虽大,里边却存在着空缺,这个空缺就是流式处理。Hadoop的所有系统都假设数据已经归档,从没假设过数据正在产生,然而在真实的世界中,数据却总是正在产生的。Nathan Marz意识到了这个问题,并想到了流式处理的概念,即把数据当成水流一样,源源不断的流过来,来一条处理一次,然后立即推送结果——围绕这些想法,他开发了一个叫做Storm的引擎,并在Twitter的推动下大获成功,最终补上了Hadoop拼图里实时计算的这一角。
Spark很快,Storm也很快,两者有什么区别呢?
我举个例子。
大家知道公交车开起来肯定比电瓶车快,所以要去十公里外你肯定会不假思索的选择坐公交车而不是骑电瓶车,可如果要去五百米外的隔壁小区,你的选择可能会截然相反,因为可能等车的功夫你已经骑到了。
Spark是公交车,Storm就是电瓶车,Spark需要等大家都上车之后一批运过去,而Storm不用,来一个走一个。
当然了,这个例子也是我现在才想到的,因为当时的我完全没有动力再看任何关于Hadoop的东西,心情就像庄子说的“吾生也有涯,而知也无涯 。以有涯随无涯,殆已”,干脆放弃了。
抱着这个念头的我,2014年研究生一毕业便选择了一家三线城市的国企,做好了这辈子也就这样的准备。
可大数据实在是太火了,领导一听我学过Hadoop便两眼放光,兴冲冲的把我塞到了公司的大数据实验室里,于是我开始在一个连不上网的环境里继续折腾Hadoop,除了版本低一些、集群小一点之外和互联网公司也没什么区别,一样辛苦,一样996。
后来我觉得这辈子可能是躲不开了大数据了,这样干着也不是个事,不如索性堂堂正正的面对这个问题。
所以在2015年的时候,我又回到了杭州。
作为一个刚毕业的壮劳力,我很快就在一家不大不小的公司里找到了工作,生活开始变的很简单,每天就是写各种SQL,然后加着和大部分人差不多的班,业余时间看看InfoQ上分享的大数据架构,憧憬着什么时候能有一套自己的房子。虽然我很快就又一次确定了自己对大数据毫无兴趣的事实,但不同的是我这次找到了坚持的力量,因为我结婚了,还要很多事情要做,而这都需要钱。
时间过的很快,我开始记不起年少时的模样,在这种日复一日的工作之中,我的儿子出生了,这件事给平淡的生活增加了一丝乐趣,也给我那日渐稀疏的头顶增加了一层压力。
有一次在带娃的间歇里,我坐在马桶上刷手机,不经意间看到了阿里收购Flink的消息,里边讲了Flink的种种神迹,我随手便转到了公司的群里,过了一会,主管回复说,有点意思,那谁谁你就负责研究研究看看吧。
我一边在心里说,得,手贱了,一边快速在群里回复说“收到,没问题”。
时间已经是2019年了,我还没搞懂2014年发布的Flink,我被时代裹挟着向前,却不知道要去哪里。儿子正在长大,父母越来越老,我看着那些裁员的新闻,不敢想象未来。
但我必须强行充满希望。
马换了一次又一次,路愈赶越远,再要回去已经来不及了,于是我只得继续往前赶。朝雾早已在一片肃穆中消散净尽,那花花世界就展现在我的面前。
借狄更斯的话,敬所有人都有远大前程。(本文首发钛媒体)
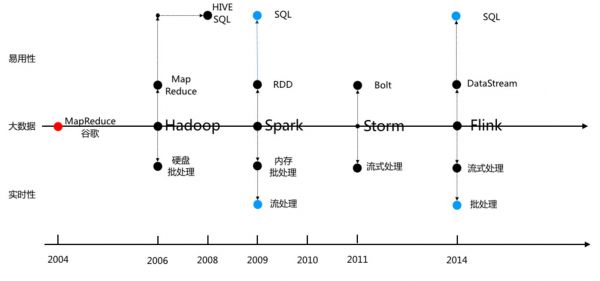
大数据计算引擎发展史
【钛媒体作者介绍:郭华,微信kakuka1988】
相关推荐
普通工程师简史
城市通勤简史
口罩简史:人类的呼吸防护是如何进化的?
2007-2019:手势交互简史
手机“变色”简史
中关村简史:从创业有罪到中国硅谷
移动支付三年简史
时尚杂志“割韭菜”简史
小米、华为互撕简史
“寻找贾维斯”简史
网址: 普通工程师简史 http://www.xishuta.com/zhidaoview684.html
推荐专业知识





- 136氪首发 | 瞄准企业“流 3926
- 2失联37天的私募大佬现身,但 3217
- 3是时候看到全球新商业版图了! 2808
- 436氪首发 | 「微脉」获1 2759
- 5流浪地球是大刘在电力系统上班 2706
- 6招商知识:商业市场前期调研及 2690
- 7Grab真开始做财富管理了 2609
- 8中国离硬科幻电影时代还有多远 2328
- 9创投周报 Vol.24 | 2183
- 10微医集团近日完成新一轮股权质 2180



